Our cultures don't encourage us to think much about learning. Instead we regard it as something that just happens to us. But learning must itself consist of sets of skills we grow ourselves; we start with only some of them and slowly grow the rest. Why don't more people keep on learning more and better learning skills? Because it's not rewarded right away, its payoff has a long delay.
What is incremental learning?
This article describes the fastest avenue towards rock-solid lifetime knowledge: Incremental Learning.
Incremental learning is the fastest and the most comprehensive way of learning available to students at the moment of writing (2013).
Incremental learning is a consolidation of computer-based techniques that accelerate and optimize the process of learning from all conceivable material available in electronic form, and not only.
Currently, SuperMemo is the only software that implements incremental learning. In SuperMemo, the student feeds the program with all forms of learning material and/or data (texts, pictures, videos, sounds, etc.). Those learning materials are then gradually converted into durable knowledge that can last a lifetime.
Incremental learning helps the student convert all forms of learning material into durable and lasting memories.
In incremental learning, the student usually remembers 95% of his or her top priority material. That knowledge is relatively stable and lasts in student's memory as long as the process continues, and well beyond.
Incremental learning easily ensures 95% recall of top-priority learning material for lifetime (as long as the student ensures a regular review along the prescription provided by the program).
The cost of high knowledge retention is very small when compared with various traditional learning methods. For example, in learning a language, the vocabulary of an educated native speaker can be retained in SuperMemo at the cost of 20 minutes per day in the first years of the process, and mere minutes in later years (assuming the original set is acquired in portions spread over 4 years in 30-50 min. sessions).
Incremental learning ensures high recall at a fraction of the cost in time (as compared to textbook learning).
The incremental learning derives its name from the incremental nature of the learning process. In incremental learning, all facets of knowledge receive a regular treatment, and there is a regular inflow of new knowledge that builds upon the past knowledge. In incremental learning, the student sits in the driving seat and determines which knowledge should be mastered. He or she determines when this happens, with what degree of detail, at what priority, and at what desired degree of recall/retention. For example, in a single session, the student may learn a few facts of geography, discover a few rules of healthy lifestyle, figure out a few statistical formulas, read a couple of paragraphs from a friend's blog, process a few minutes of his home video collection, annotate a few family pictures, watch a few pieces from his YouTube video collection, and read a few articles in subjects related to a forthcoming exam. In other words, all areas of knowledge keep growing in parallel in proportion to interests and importance.
Typical learning at school puts an emphasis on a few areas of knowledge and neglects all the remaining areas. A medical student may spend a few months mastering anatomy, while gradually forgetting his biochemistry material in the meantime (or the other way round). At the same time, he or she will not find time to study important issues of the day that will always depend on a given person in a given context. With blinkers imposed by the heavy load of school material, the student may never find time, for example, to figure out what incremental learning is. Narrow horizons and narrow perspectives only make it harder to further rationalize the selection of the learning material.
Incremental learning is the opposite of the irrational school system learning in which a heavy focus is put on just a few areas of knowledge in a semester (at the cost of other, equally important, areas of learning).
General outline of incremental learning
In incremental learning, you acquire and maintain knowledge using the following steps:
- importing knowledge from various electronic and non-electronic sources (e.g. articles on the web, YouTube videos, music files, pictures from your camera, e-mails, scanned paper notes, etc.)
- prioritizing knowledge for incremental processing (e.g. high priority for physics, low priority for movie trivia, etc.). Incremental approach means processing knowledge in small bits and in small steps
- gradually converting the learning materials into lasting knowledge in your memory. This conversion may also produce an easily searchable and well-annotated computer media archive that does not even need to be part of the learning process
- expanding creatively upon the acquired knowledge (e.g. in the process of incremental writing, problem solving, etc.)
With incremental learning, you can consolidate all sources of knowledge, and convert information into lifetime memories at the chosen cost in time, and along strictly defined goals and priorities.
Components of incremental learning
Incremental learning tools differ substantially for various forms of learning material, media, and goals. Here are the main components of incremental learning:
- incremental reading
- incremental image learning (or visual learning)
- incremental video
- incremental audio
- incremental mail processing
- incremental creative elaboration (incl. incremental problem solving, incremental writing, etc.)
With the rich toolset offered by incremental learning, all reading, learning, viewing, archiving, and annotation functions can be delegated to SuperMemo. This goes far beyond standard learning and includes personal notes, home videos, lectures available in audio and video formats, YouTube material, family photo-albums, diaries, audio files, scanned paper materials, etc.
The oldest, most popular, and the most mature component of incremental learning is incremental reading. We will use incremental reading as the comprehensive introduction to other forms of incremental learning.
The value of interruption in learning
In incremental learning, we often quickly move from one subject to another. Such interruptions may occur many times during a single learning day. When people first learn about this incremental methodology they immediately ask "Why interrupt? Aren't these the prime principles of human endeavour to be thorough, persist, and do things right to the end?"
The 3 main advantages of interruption in learning are:
- improving memory: spaced learning has long been proven dramatically more efficient than conglomerate learning massed in time
- improving learning choices/priorities: unless the learning material has been pre-selected by a higher authority, student's own choices require prioritization, which in turn requires preview. Previewing is a form of interruption. Regular interruption allows of prioritizing on the go
- improving attention: whenever attention declines, change of the subject is the simplest remedy other than taking a definite break from learning
As for the disadvantages ... there are none! Simply put: interruption is optional! It is true that incremental learning may lead to "learning impatience" and "craving interruption", however, these have never been proven detrimental beyond showing that once you employ incremental learning, you may never want to go back to traditional "book at a time" learning. Nevertheless, you should not forget that schools are incremental too. Just on a slightly moderate scale. Schools employ interruption when kids move from geography to physics, or when they close the books for the day.
Once the art of incremental learning is mastered, the advantages go far beyond the advantages of the interruption or spaced repetition. Here is a shortlist (for a detailed discussion see: Advantages of incremental learning).
- massive learning - you learn more than you thought your memory can hold
- 95% knowledge retention - you nearly eliminate the problem of forgetting
- lifetime memories - your memories will last for life (as long as you stick with the regular review schedule based on spaced repetition)
- comprehensive learning on all fronts (rather than the school-like focus on 2-4 majors)
- better understanding of the studied subject is assisted by moderation in consuming details, and easy inclusion of explanatory material (e.g. from dictionaries and/or encyclopedias)
- better consolidation of the knowledge structure by incremental approach, interrupted learning, spacing, and slotting in of the new knowledge. Contrary to popular belief, incremental learning helps you keep the big picture in your mind
- better attention by focusing on a single issue at a time without ever missing a detail, and by remedying attention deficits with a constant change of the learning material
- creativity - by encountering different subjects in unpredictable sequences, your creativity soars. You can employ it, for example, in the process of incremental problem solving or incremental writing (this article was written using incremental writing tools in SuperMemo)
- battling chaos - it is easier to resolve contradictions in SuperMemo, e.g. when processing new research with contradictory claims and findings. Unlike your memory in "real life" where you keep oscillating between contradictions, SuperMemo does not tolerate information discrepancy. Contradictory material converges up to a point when you realize you need to decide on the nature of the truth
- all knowledge is well prioritized
- all knowledge is easily searchable
- all knowledge is quantifiable (size, retention, workload, etc.)
- stresslessness - nothing frees your mind for learning efficiently as the sense that no detail will ever be missed and you can focus on a single problem at a time while delegating other problems to later
- fun - once you master incremental learning, it can truly be the best part of your day with few other earthly pleasures giving you as much satisfaction as new useful knowledge
In short, with incremental learning you learn fast, you acquire massive loads of knowledge, retain memories for life, remember almost all that you have learned, understand things better, develop harmoniously in all directions, enhance your creativity, and all that while having incredible fun! If that sounds too good to be true, please read more below or just give it a solid try. For a detailed explanation see: Advantages of incremental learning.
Interruption is not a problem
In learning, choosing the right learning sources is the first step to success. A well-written article will get you to the basic idea from its first paragraph or even a sentence. Incremental reading is best suited for articles written in hypertext or in an encyclopedic manner. Ideally, each sentence you read has a contribution to your knowledge and is not useless without the sentences that follow.
Imagine that you would like to learn a few things about Gamal Abdel Nasser. You will, for example, import to SuperMemo an article about Nasser from Wikipedia. In the first sentence you will find out that "Gamal Abdel Nasser (1918 - 1970) was the second President of Egypt". If you are new to Nasser, you may be happy to just know he was the Egyptian president and safely jump to reading other articles. Thus you may delay the encounter with the historic role of Nasser and economize some time to finding out, for example, who Shimon Peres is. When you see the Nasser article for the second time, you might find that "He was followed by after President Muhammad Naguib and can be considered one of the most important Arab leaders in history". This piece of knowledge is also self-contained and you can patiently wait for your third encounter with Nasser. When you return the next time, you may conclude that another piece about Nasser is of lower priority: "Nasser was born in Alexandria". You can schedule the review of that piece in 2-3 years. Perhaps your interest in Nasser or in Alexandria will grow to the point that this knowledge will become relevant. If not, you can always dismiss or delete such an extract. Alternatively, you can skip a few paragraphs and extract a more important sentence: "In 1952, Nasser led the military coup against King Farouk I of Egypt". Even if your read individual sentences about Nasser in intervals lasting months, your knowledge will progressively expand and will become increasingly consolidated (esp. if you employ cloze deletions, which are mandatory for longer intervals).
Naturally, not all texts are are so well-suited for incremental reading. For example, a research paper may throw at you a detailed description of methods and leave results and conclusions for the end. In such cases, you may extract the abstract and delay the body of the paper by a period in which you believe the abstract will have been sufficiently processed. Then, if you are still interested in the article, you can schedule the methods well into the future (you will or will not read the methods depending on the conclusions of the article). You can schedule the results and the discussion into a less remote point in time, and proceed with reading the conclusions.
The hardest texts may not be suitable to reading in increments. For example, a piece of software code may need to be analyzed in its entirety before it reveals any useful meaning. In such cases, when the text (here the code) comes up in the incremental reading process, analyze it and verbalize your conclusions. The conclusions can then be processed incrementally. You will generate individual questions depending on which pieces of knowledge you consider important and which become volatile. The original computer code can be still retained in your collection as reference only.
When learning at the university, you do many courses in parallel. That's a macro version of incremental reading. Many people love to zap TV channels and play a chaotic version of incremental video with their TV set. Zapping may not be a recommended way of learning, but it won't leave your mind blank. Another example can be seen in people who have a habit of reading a few novels in parallel. Their limit on the number of novels comes from the limits of human memory. There is a breaking point beyond which a novel, if read in bursts separated by longer intervals, cannot be followed due to fading memories. Incremental reading is based on SuperMemo, and by definition is far less limited by your forgetful memory. The number of articles in the process can reach a hundred thousands, and given basic skills, you won't get confused.
Complexity of incremental learning
Unlike classic SuperMemo, incremental learning requires quite a lot of experience and training before it becomes effective. However, your investment will be returned manifold once you become proficient with the method.
Incremental learning is a consolidation of technologies that have been in development for nearly 3 decades. It is still in the process of maturing and it is still pretty complex. It requires skills that take months to develop. It requires your own strategies that may mature over years. Moreover, incremental learning requires the mastery of SuperMemo, which has been optimized for professional use. As such it is not beginner friendly.
Users complain that SuperMemo has a steep learning curve. They are right. SuperMemo has been optimized to make a life of a pro easy. It makes life of beginners hard because it does not ever compromise the learning efficiency for sleekness or marketing value. Take the priority queue as an example. Nearly everyone asks why the articles of highest value have a priority of 0% rather than the obvious 100%. They ask: "Why is SuperMemo always keeping things upside down?". They got a point. However, no pro user would ever swap the ease of typing 1, 2, 3 for his top priority material as opposed to 99, 98 or 97. Those dilemmas slow down the adoption of SuperMemo. However, once you become a pro, you will appreciate this approach and will more likely become a lifelong devotee.
Incremental reading
Introduction
Traditional linear reading is highly inefficient. This comes from the fact that various pieces of the text are of various importance. Some should be skipped. Others should be read in the first order of priority. Old-fashioned books are quickly being replaced with hypertext. Hypertext will help you quickly jump to information that is the most important at any given moment. Hypertext requires a different style of writing. All linear texts can assume that the reader is familiar with the preceding sections. This makes them context-poor. Within hypertext, individual texts become context-independent, and all difficult terms and concepts are explained primarily with additional hyperlinks. In the same way in which the web helped delinearize the global sources of information, SuperMemo can help you delinearize your reading of whatever linear material you decide to import to SuperMemo. While reading with SuperMemo, you will see a linear text as a sequence of sections subdivided into paragraphs and individual sentences. SuperMemo will help you provide a separate and independent processing for each section, paragraph or sentence.
What is incremental reading?
Incremental reading is a learning technique that makes it possible to read thousands of articles at the same time without getting lost. Incremental reading begins with importing articles from electronic sources, e.g. the Internet. The student then extracts the most important fragments of individual articles for further review. Extracted fragments are then converted into questions and answers. These in turn become subject to systematic review and repetition that maximizes the long-term recall. The review process is handled by the proven spaced repetition algorithm known as the SuperMemo method.
Incremental reading converts electronic articles into durable knowledge in your memory. This conversion requires minimum keyboard&mouse work:
- Input: electronic articles (e.g. collected from the net)
- Output: well-remembered knowledge (quizzed regularly in the form of questions and answers)
In incremental reading, you read articles in small portions. After you read a portion of one article, you go on to a portion of another article, etc. You introduce all important portions of texts into the learning process in SuperMemo. This way you do not worry that you forget the main thread of the article, even if you return to reading months later. Your progress with individual articles may be slow, but you greatly increase your efficiency by paying less attention to less important articles and spending more time on articles that are more beneficial to your knowledge. Difficult articles may wait until you read easier explanatory articles, etc. Last but not least, incremental reading increases your efficiency because it is fun! You never get bored. If you do not like an article, you read just a sentence and jump to other articles. This way your attention and focus stay maximized.
Warning! Incremental reading may seem complex at first. However, once you master it, you will begin a learning process that will surpass your expectations. You will be surprised with the volume of data your memory can process and retain!
Five basic skills of incremental reading
Incremental reading requires skills that you will perfect only over months and years of use. This overview will only help you master the basic skills and help you make a start with incremental reading. The 5 basic skills are:
- importing articles to SuperMemo
- reading articles and decomposing articles into manageable pieces
- converting most important pieces of knowledge into question-answer material
- review of the material to ensure good recall
- handling of the unavoidable overflow of information
Skill 1: Importing articles
Five article import methods
Initially, you may limit your imports to a simple copy&paste of individual articles. Later, you will want to master automatic imports from the web that offer many advantages.
Here are the 5 main article import methods in SuperMemo:
- Copy&Paste: select a text of an article in the browser (or any other application that allows of copying texts), copy it to the clipboard, and copy it to SuperMemo with a single keystroke: Alt+N
- Mass import: use a dedicated web import option to import many articles from Internet Explorer. This methods allows of avoiding duplicate imports, marks your imports with references, imports only selected portions of texts, and offers many other advantages.
- Dedicated imports: SuperMemo makes it particularly easy to import material from Wikipedia (the recommended source of basic incremental reading materials) and from YouTube (a source of incremental video materials)
- Local file imports: import files that you have already collected on your hard disk
- Mail imports: for incremental processing of your mail
Import by Copy&Paste
To import an article with copy and paste, follow these steps:
- Select the imported text in your web browser and copy the selection to the clipboard (e.g. with Ctrl+C)
- Switch to SuperMemo (e.g. with Alt+Tab)
- In SuperMemo, press Ctrl+N (this is equivalent to Edit : Add a new article on the main menu). SuperMemo will create a new element, and paste the article. You can also use the Paste an article button (
 ) on the learnbar or on the Read toolbar
) on the learnbar or on the Read toolbar - Optionally, use Alt+P to define priority of the imported article. Use the Percent field and remember that 0% is the highest priority, while 100% is the lowest priority
- Optionally, use Ctrl+J to specify the first review interval. For example: one day for high priority material or 30 days for low priority material
Please remember that if you have many articles opened in Internet Explorer, you can most easily import them with web import as described in the next section.
Import of multiple articles
The most convenient way to import learning materials to SuperMemo is a direct import of multiple articles right from the web. To import many articles at the same time, open these articles in Internet Explorer, and click the import button on the learnbar (or press Ctrl+Shift+A, or chose Edit : Import web pages on the main menu). To avoid importing advertising and other garbage, in Internet Explorer, select portions of the text that is to be imported. If you select texts before imports, you are less likely to need filters to get rid of troublesome HTML (F6). If you prefer to use other browsers, e.g. Chrome or Firefox, you will need to use Copy&Paste method, or re-open the selected articles in Internet Explorer. This is because, at the moment, SuperMemo supports direct imports only from Internet Explorer.
For more details on importing multiple articles see: Web import
Dedicated imports (Wikipedia, YouTube, and pictures)
The most popular sources of learning materials are Wikipedia (for incremental reading) and YouTube (for incremental video). For those sources, you have separate options available on the import menu (right click on the import button on the learnbar). You can also use shortcuts Ctrl+Shift+W (Wikipedia) and Ctrl+Shift+Y (YouTube) to import from those two sources. If you choose those options, only articles available from those sources will be displayed on the import list. Additionally, a dedicated filter will best prepare the imported pages for convenient learning.

After importing an article about the greenhouse effect from Wikipedia (e.g. with Edit : Import web pages : Wikipedia (Shift+Ctrl+W)), its entire text is stored in a single topic.
If you want to import pictures, you can also use a picture filter that will ignore all non-picture pages opened in Internet Explorer. Use Pictures on the import button menu on the learnbar (right click). You can also click Filter : Pictures in the web import dialog when importing pages (e.g. with Ctrl+Shift+A).
For more details see: Web import
Importing articles from local files
If you want to import articles from files that reside on your local drive, you can use the following methods:
- Single article from Internet Explorer into a new element
- open the local article in Internet Explorer
- import in the same way as you import articles from the web (e.g. Import by Copy&Paste or Import of multiple articles)
- Single article from local drive into a new element
- use Edit : Add to category : HTML file on the main menu
- Single article into existing HTML component
- choose File : Import file on the HTML component menu
- Multiple articles (stored in a single folder)
Skill 2: Reading articles
Here is a simplified algorithm for reading articles:
- Choose an article: Import an article as explained earlier or bring up previously imported articles with Learn (Ctrl+L). Learn will display only articles imported in the past. If you import an article, and want to have it shown later during a learning session on the same day, you must place it in the outstanding queue (e.g. Learning : Later today on the element menu, Ctrl+Shift+J, etc.). If you import many articles that you want to process on the same day, you must place them all in the outstanding queue. For example, open the articles in the browser, and choose Learning : Add to outstanding. Most of the time you can rely solely on Learn to schedule articles optimally for review.
- Click the article to enter the editing mode, in which you can modify text, select fragments, etc. Optionally, use filter F6, if the text is hard to process (e.g. selections are hard, extracts not marked correctly, etc.)
- Start reading the article from the top or from the last read point (i.e. a bookmark left in the text last time you read it)
- Extract texts: If you encounter an interesting text in the article, select it and choose Remember extract on the learnbar (or press Alt+X). This operation will introduce the extracted fragment into the learning process as an independent mini-article. If you would like to specify the priority of the new extract, choose Reading : Schedule extract (
 ) instead of Remember extract. Also, if you have an impression that the article is difficult and you would like to read some fragments later, extract those fragments with Reading : Schedule extract and provide a review interval that will reflect the time you believe you will be better equipped to understand the extracted fragment.
) instead of Remember extract. Also, if you have an impression that the article is difficult and you would like to read some fragments later, extract those fragments with Reading : Schedule extract and provide a review interval that will reflect the time you believe you will be better equipped to understand the extracted fragment. - Optionally, use Delete before cursor (Alt+\). This will delete the text that you have read, clean up the article, remove garbage, and help tackle HTML that is difficult to process.
- Optionally, if you read a fragment that seems unimportant, select it (e.g. with the mouse) and either delete it (e.g. with the Del key) or mark it with the ignore style. To mark a text as ignore, choose Reading : Ignore on the component menu, click the Ignore text button (
 ) on the Read toolbar, or just press Ctrl+Shift+I.
) on the Read toolbar, or just press Ctrl+Shift+I. - Optionally, if the selected fragment does not include all the important reading context, you can add this context manually. For example, if you are learning history, you may extract the following fragment from an article about Lincoln: On Sept. 22, 1862, President Lincoln issued the Emancipation Proclamation, one of the most important messages in the history of the world. He signed it Jan. 1, 1863. If you would like to extract the fragment related to signing the Emancipation Proclamation, you will need to change He to Lincoln and it to Emancipation Proclamation so that your stand-alone fragment is understandable: Lincoln signed the Emancipation Proclamation on Jan. 1, 1863. You can use the Reference options on the component menu to easily add context to your extracts (see: References). Context added by Reference will be added automatically to all extracts of a given article. For example, select the text that you want to serve as the reference title of all extracts and choose Reference : Title on the HTML component menu (or press Alt+T). This text will appear at the bottom of all extracts (in reference pink font by default).
- Optionally, mark your last read point: Once you decide to stop reading the article before its end, mark the last processed fragment as the read-point (e.g. with Ctrl+F7 or by choosing Reading : Read-points : Set read-point from the HTML component menu). Next time you come back to this same article, SuperMemo will highlight your read-point and you will be able to resume reading from the point you last stopped reading the article. To go to your current read point, press Alt+F7. If you forget to set a read-point, SuperMemo will leave a read-point at the place of your last extract or last highlight.
- Go to the next article: After you finish reading a portion of one article, choose Learn or Next repetition to proceed with reading other articles. Those buttons are located at the bottom of the element window. You can also use Enter, which will work as long as the selection in the text is not empty (e.g. marked as a reading point), or if you have left the editing mode (e.g. with Esc). If no text is selected, Enter will add a new line in the text (as is the case with standard text editors).
- Optionally, determine the next review date (e.g. with Ctrl+Shift+R), or set the new priority for the article (e.g. with Alt+P).
- In incremental reading, interrupted reading is a rule, not an exception! With a dose of practice, you will quickly get accustomed to this not-so-natural state of affairs and learn to appreciate the power of the incremental approach. The main role of interruption is to prevent the decline in the quality of reading. Use the following criteria to decide when to stop reading the article:
- lack of time: if you still have many articles for review for a given day and your time is running out, keep your increments shorter. After some time, being in a hurry will be a norm and you will tend to read only 1-2 paragraphs of each article and dig deeper only into groundbreaking articles that will powerfully affect your knowledge.
- boredom: if the article tends to make you bored, stop reading. Your attention span is always limited. If your focus is poor, you will benefit more from the article if you return to it after some break. Go on to reading something that you are not yet tired of. If SuperMemo schedules the next review at a date you consider too late, use Ctrl+J or Shift+Ctrl+R to adjust the next review date.
- lack of understanding: if you feel you need more knowledge before you are able to understand the article, postpone it (e.g. use Ctrl+J or Shift+Ctrl+R and schedule the next review in 100 days or so). If you believe you have already imported articles with relevant explanatory knowledge, you can search for these articles (e.g. with Ctrl+F). Once you find them, you can (1) execute a subset review, or (2) add the articles to the outstanding queue for reading on the same day, or (3) advance the articles (for example, in the browser, you can execute: Learning : Review all, or Learning : Add to outstanding, or Advance : Topics). If you have not yet imported any explanatory articles, you can do it now (e.g. search the web and import articles as explained before). Note that you can select a piece of text in SuperMemo and use Ctrl+F3 to search encyclopedias or dictionaries for more material on a given subject.
- lower priority: read lower priority articles in smaller portions thus reducing the overall time allocation to low priority subjects.
- overload: if you have a long queue of articles to read, you will naturally read in smaller portions
- Once you complete reading the entire article and have extracted all the interesting fragments, choose Done! (
 ) on the learnbar. You can also press Shift+Ctrl+Enter, choose Done! in the Commander, or choose Learning : Done on the element menu. Done! will dismiss the article, i.e. remove it from the review process, and delete its contents (without deleting the extracted material). Done will delete a childless article (i.e. an article that did not provide any interesting extract). Using Done will greatly reduce the size of your collection and eliminate "dead hits" when searching for texts.
) on the learnbar. You can also press Shift+Ctrl+Enter, choose Done! in the Commander, or choose Learning : Done on the element menu. Done! will dismiss the article, i.e. remove it from the review process, and delete its contents (without deleting the extracted material). Done will delete a childless article (i.e. an article that did not provide any interesting extract). Using Done will greatly reduce the size of your collection and eliminate "dead hits" when searching for texts.
.jpg)
Figure: The Read toolbar docked at the learnbar. It hosts options used in incremental reading.
Skill 3: Extracting fragments, questions and answers
Extracting texts
In the course of traditional reading, we often mark important paragraphs with a highlighter pen. In SuperMemo, those paragraphs can be extracted as separate mini-articles that will later be used to refresh your memory. Each extracted paragraph or section becomes a new element that will be subject to the same reading algorithm as the original article. Extract important fragments and single sentences with Remember extract (Alt+X)
Adding references
Why need references?
In incremental reading, you always need to quickly recover the context of a question or a piece of text. The easiest way to recover context quickly is via references. References propagate from element to element as you produce extracts and cloze deletions. With all child elements produced from a given text marked with references, you would never need to worry about losing the context of the question.
For example:
Q: He was born in [...](year)
cannot be answered without the context. However, the following question is already easier to understand:
Q: He was born in [...](year)
#Title: Barrack Obama
#Source: Wikipedia
To speed up learning, in the incremental reading process, the above question should naturally be replaced with:
Q: Obama was born in [...](year)
or
Q: Obama was born in [...](year)
#Title: Barrack Obama
#Source: Wikipedia
References are not stored in HTML files that hold your articles but in a reference registry (i.e. in a separate database). The reference registry does not hold the text of references either. All reference texts are held in the text registry and are available for global text searches. In earlier versions of SuperMemo, each text would keep its own copy of references. In newer SuperMemos, elements keep only pointers to reference registry, which in turn keeps pointers to individual text fields in the text registry. As a result, many elements can hold the same reference, and many references can hold the same text. This results in a significant saving in space in your collection. More importantly, you can update the reference in a single element and see the change show in all elements using the same reference. This way, you do not need to waste time on search&replace to correct a single misspelling or reference inaccuracy that propagated to many elements.
Example: references inserted automatically
If you select the title of the source article and press Alt+T (Reference : Title on the HTML component menu), each extract will be marked by the title of the source article. If you use File : Import web pages : All, your articles will be provided with basic references (such as #Title, #Link, #Date, etc.). If you need more context (e.g. to add the author, the journal, etc.), you can use the Reference link button (![]() ) on the navigation bar to jump to the source article from which the extract was produced. On the parent article, that button will lead you to the original link on the net.
) on the navigation bar to jump to the source article from which the extract was produced. On the parent article, that button will lead you to the original link on the net.

Figure: Typical snapshot of incremental reading. While learning about the greenhouse effect, the student extracts the fragment saying that "In the absence of the greenhouse effect and an atmosphere, the Earth's average surface temperature of 14 °C could be as low as -18 °C, the black body temperature of the Earth.". The extracted fragment will inherit illustrations placed on the right, as well as article references. The student can move on to reading another article by pressing Enter. The picture on the right is stored locally in the image registry (on the user's hard disk) and can be reused to illustrate other articles or questions.
Reference system highlights
- To mark texts as reference fields use the Reference submenu on the HTML component menu (e.g. Reference : Select or Alt+Q)
- Reference fields #Article, #Parent and #Category are added automatically and are not stored in the reference registry. These fields are not generated in elements that have no other reference fields defined
- References marked with Alt+Q options show up in the reference field and can be deleted from the text's body (if no longer needed)
- From the user's point of view, there is a little difference in the way the references are handled as compared with earlier SuperMemos. SuperMemo 2008 or later differentiates between the following 2 types of references edits:
- local edits that affect only the present element and create a new reference record vs.
- global edits which change the original reference in all the elements that use it.
- When SuperMemo is not sure if your edits are local or global, it will ask you
- You can edit references in the reference area or in a dedicated window that you can open by choosing Reference : Edit from the element menu. You only need to use legal reference field tags at the beginning of each reference line (e.g. #Author:). If SuperMemo is not sure if your changes should apply to the current element only, or to all elements that use the reference, it will ask you
- References no longer clutter your HTML files. In the past, the size of references would often be greater than the length of the text itself
- Reference registry keeps the references (see below), and their individual text fields are stored in the text registry
- References are added to HTML texts at load time, so that you can still have references located at the bottom of your texts as in earlier versions of SuperMemo
- Adding an existing reference to an element (e.g. with Reference : Link from the element menu) does not add to the size of the collection
Important! Do not add your own non-reference texts below the horizontal bar marking the reference area. All reference field area is owned by SuperMemo. Any modifications to that area will be treated as changes to reference fields. Changes that do not conform with reference field formatting will be discarded without warning.

Figure: An extract from an article on sleep and dreaming. Blue marks an extract produced from the presented text. Yellow marks the search string (i.e. GABA-ergic REM-on neurons) that was used in Search : Find elements (Ctrl+F) to find all the elements (including this one) containing the string. Pink marks the reference area (consisting of the #Title, #Author, #Date, #Source, #Article, #Parent, and #Category fields), which will propagate to all children elements (extracts and clozes) generated from this element.

Editing references
You an use Reference : Edit in SuperMemo Commander, however, you can also edit references in the reference area (which is pink in the default stylesheet). You can safely delete reference fields, but you need to decide if that change should be local (for that element only) or global (for all elements using this reference). You will not be able to delete #Article or #Category fields because they are added automatically to the reference section (i.e. they are not part of the reference itself). You can freely change the text of references. Illegal changes are all changes that do not comply with the reference format, e.g. lines that do not start with reference field tags, or lines that start with unknown reference field tags (e.g. #Country). If you are unsure how this process works, import a single article from Wikipedia to a newly created collection, create some extracts and play with editing to see how references are processed.
Cloze: Generating questions
SuperMemo will show you that extracting important fragments and reviewing them at later time will have an excellent impact on your ability to remember. However, it will also show that once the time between reviewsincreases beyond 200-300 days, reading and re-reading (passive review) will often result in insufficient recall. For this reason, sooner or later, you will need to convert your texts to specific questions. For that purpose you will use cloze deletion.
A cloze deletion is an item that uses an ellipsis ([...]) to replace a part of a sentence.
For example:
Question: The capital of Sierra Leone is [...]
Answer: Freetown
In incremental reading, cloze deletions are generated from topics that have a form of a sentence or a simple paragraph.
To create a cloze deletion do the following:
- make sure a topic contains a short sentence only (e.g. The capital of Sierra Leone is Freetown)
- select an important keyword in that sentence (e.g. Freetown)
- do one of the following:
- click the Cloze button (
 ) on the Read toolbar, or
) on the Read toolbar, or - press Alt+Z, or
- choose Reading : Remember cloze from the HTML component menu.
- click the Cloze button (
Remember cloze will convert a sentence into a specific question with an answer. By using cloze, you will move from passive review to active recall. You do not need to wait until a paragraph or a sentence becomes hard to recall in passive review. For your most important material, you can create cloze items immediately after finding a piece of information that you need to remember well.
The examples below show how to effectively use Remember cloze.

Figure: Two numbers from the extracted sentence are used as keywords for generating questions and answers (temperatures of 14 °C and -18 °C)

Figure: The sentence extracted during incremental reading (see the previous picture) is converted into a cloze deletion. (i.e. a question-answer pair forming the final product of incremental reading used in strengthening the memory of a given fact (here: hypothetical temperature on Earth devoid of atmosphere)). The picture from the original extract has been inherited (on the right). Pink texts at the bottom of the question are references generated automatically when importing an article from Wikipedia.
When you click Cloze, you will not see your newly generated cloze. Only the selected keyword will change the color. This will speed up your work. However, if you would like to immediately edit the newly created cloze deletion, choose the back button (![]() ) on the navigation bar or press Alt+Left arrow. This will make it possible to add context clues, shorten the text, improve the wording, etc.
) on the navigation bar or press Alt+Left arrow. This will make it possible to add context clues, shorten the text, improve the wording, etc.
Simplifying questions
While converting extracts into questions and answers, you should make sure your questions are simple, clear and carrying the relevant context. For example, if you have extracted the following fragment from your reading about the history of the Internet:
The Internet was started in 1969 under acontract let by the Advanced Research Projects Agency (ARPA) which connected four major computers at universities in the southwestern US (UCLA, Stanford Research Institute, UCSB, and the University of Utah)
you may discover that when review intervals become long enough, you may not actually be able to recall the name of the ARPA agency or even forget the year in which the Internet started. You can then select an important keyword, e.g. 1969, and use Remember cloze to produce the following question-answer pair:
Question: The Internet was started in [...] under a contract let by the Advanced Research Projects Agency (ARPA) which connected four major computers at universities in the southwestern US (UCLA, Stanford Research Institute, UCSB, and the University of Utah)
Answer: 1969
In the course of learning, you will need to polish the above item by manual editing it to a more compact and understandable form:
Question: The Internet was started in [...](year) under a contract let by the ARPA agency
Answer: 1969
Or better yet:
Question: The Internet was started in [...](year)
Answer: 1969
As for the precious information "lost" during the editing, it can (but does not have to) be learned independently with separate questions generated by Remember cloze.
The mini-editing of questions presented above added the following benefits to the newly created question-answer pair:
- clearer purpose of the question: the fact that the question is about the year in which the Internet began is emphasized by using the red-colored (year) hint.
- brevity: by removing superfluous information, you will not waste time on information that is not likely to be remembered (only actively recalled material will be remembered for years). You will answer the question and never focus on which universities were originally connected by the early Internet. If you believe this information is also important, you will use the original extract to produce more cloze items that will focus solely on the universities in question by naming them in the answer field (if you disagree, read: 20 rules of formulating knowledge).
- understandability: "the ARPA agency" phrase may defy grammar rules you have learned in primary school, but it is by far more understandable than just the ARPA. In SuperMemo, understandability is more important than stiff rules of grammar or spelling!
Skill 4: Repetition and review
SuperMemo is based on repetition. You will review the learned material from time to time to make sure you prevent forgetting.
If you have never tried SuperMemo before, you will need to get the hang of standard repetitions as described here.
In incremental reading, your review will be based on similar principles as in classical SuperMemo. The main differencesare:
- the learning process will intermingle reading of new articles with reviewing your items
- your items will mostly have a form of cloze deletions, i.e. sentences with a question posed by a missing part [...] (e.g. The planet nearest the Sun is [...])
- as the entire learning process is incremental, your cloze deletions will often show up in an unfinished form
Incrementally processed articles will be subject to periodic review/reading. When you resume reading an article after a certain period, you will proceed to new sections, extracting newly acquired wisdom intoseparate elements with Alt+X (i.e. Remember extract). Usually, you will delete the remnants of the processed article with Delete before cursor (Alt+\).
The algorithms that determine the timing of (1) repetitions of question-and-answer material and (2) reviewing reading material are analogous but not identical. Most importantly, all repetitions and article presentations happen in increasing intervals by default. In incremental reading, you will see a constant inflow of new articles into your collection. Unprocessed material will need to compete with the newlyimported material. Increasing review intervals make sure that your old material fades into lower priority if not processed early. The speed of processing will depend on the availability of your time and the value of the material itself. Articles that are boring, badly written, less important for your work or growth, will receive smaller portions of your attention and may go into long review intervals before you even manage to pass a fraction of the text. That is an inevitable side effect of a voluminous flow of new information into your collection and into your memory. However, intervals and priorities can easily be adjusted. If your priorities change, you can modify the way you process important articles. At review time, you can either read the entire article without interruption, or bring it back for review in a shorter interval. You can manually change its priority (e.g. with Alt+P). You can also use search tools (e.g. Ctrl+F) to locate more articles on the subject that you feel you have neglected. You can reprioritize a bunch of articles by changing their priority. You can shorten intervals of articles, or review them all when needed (see: Subset review).
The algorithm for reviewing questions and answers (e.g. cloze deletions) is quite complex and limits your influence on the timing of repetitions (see: SuperMemo Algorithm). This is to ensure that you achieve a high level of knowledge retention, which might be compromised by manual intervention. However, the algorithm for determining inter-review intervals for topics is much simpler and is entirely under your control. Each article receives a specific priority. The priority determines which articles are reviewed first and which can be postponed in case you run out of time. Each article is also assigned a number called the A-Factor that determines how much intervals increase between subsequent reviews. For example, if A-Factor is 2, review intervals will double with each review. Priority and A-Factors are set automatically, but you can change them manually at any time. You can also set priorities for individual categoriesof the learning material. Priorities and A-Factors are determined and modified heuristically on the basis of the length of the text, the way it is processed, the way it is postponed or advanced, and by many other factors. You can change the priority and A-Factor of an article by pressing Alt+P. You can also use Shift+Ctrl+Up arrow and Shift+Ctrl+Down arrow to increase or decrease an element's priority. Note that A-Factors associated with items cannot be changed by the user, as they are a reflection of item difficulty that determines the length of optimum inter-repetition intervals (see: Forgetting index).
You can control the timing of article review by manually adjusting inter-review intervals. Use Ctrl+J (Reschedule) or Shift+Ctrl+R (Execute repetition) to determine the date of thenext review. Ctrl+J will increment the current interval, while Shift+Ctrl+R will first execute a repetition and then set the new interval. For example, if your current interval is 100 and you specify thevalue of 3 in Reschedule, your new repetition date will be set in 3 days, and the last repetition date will not change (the new interval will be 103). If you do the same with Execute repetition, your new interval will be 3 and the last repetition date will be set to today. In other words, Reschedule increments the interval (it can also shorten intervals), while Execute repetition sets the length of the interval (while leaving a trace of a repetition executed in the learning process). Note that Reschedule executed during the repetition cycle will first complete the repetition and will have the same effect as Execute repetition.
In a heavily overloaded incremental reading process, you will often want to focus on a specific subject on a given day. For that purpose, readabout the priceless concept of subset learning.
Summary
- use the Learn button to process, learn, and review all your knowledge
- the review of items is handled by the SuperMemo Algorithm. Grade your items well, formulate them well, and mark them with honest priorities. SuperMemo will take care of the rest
- review of topics/articles also occurs in increasing intervals, however, you can always manually set the next date with Execute repetition (Shift+Ctrl+R). Make sure you mark your top articles with high priority. Otherwise, they can quickly fade from view
Skill 5: Handling large volumes of knowledge
In incremental reading, you may quickly import and produce more learning material than you can effectively process. To make sure that you can swiftly handle the overload, SuperMemo uses the priority queue.
Using Alt+P (Learning : Priority : Modify on the element menu), you can set each element's priority from 0% to 100%. Note that 0% correspondswith high priority!
By default, the outstanding repetitions will be auto-sorted from high to low priority. This way, if you fail to complete your daily load of learning, it will only be the lower priority material that will suffer. Also by default, at the beginning of your working day (i.e. at your first run of SuperMemo), your outstanding material from previous days will be be auto-postponed (again with high-priority material being least affected).
Read an article about the priority queue to learn more about:
- manual sorting of elements,
- defining sorting criteria,
- turning off auto-sort and auto-postpone, and more.
For more options for handling the overload, see:
- the postpone dialog to postpone portions of the learning material and to define the postpone criteria
- Mercy: to spread the excess of the learning material over a period of time (or to advance the material before a vacation, etc.)
- to learn more about different options, see also: Postpone, Advance and Mercy
Other basic skills
Evolution of knowledge in incremental reading
3 main principles will underlie the evolution of knowledge in SuperMemo:
- decrease in complexity - articles will be converted into sets of paragraphs. Paragraphs will be dismantled into sets of independent sentences and statements. Sentences will be shortened to maximize the information-vs-wording ratio, etc.
- active recall - all pieces of information will ultimately be converted into active recall material such as question-answer pairs, cloze deletions, picture recognition tests, sound recognition tests, etc. This is to maximize your recall of knowledge
- incrementalism - all changes will take place gradually in proportion to available time, with respect to your selected material's priority, and in line with the gradually increasing strength of memory traces. Incremental nature of learning in SuperMemo will help you get the maximum memory effect in minimum time. See: The value of interruption in learning
Using pictures
For additional information, mnemonic cues, and a sheer fun of learning, an article that you read incrementally in SuperMemo can be illustrated with meaningful pictures taken from its contents, or from other sources. Press Ctrl+F8 to choose one of the pictures embedded in the article.
If you happen to import from Wikipedia, SuperMemo 16 makes it possible to download full resolution images instead of just thumbs. Check images marked with THUMB!!! and click Download.

Figure: After importing a Wikipedia article on atherosclerosis, two thumbs have been selected and downloaded in full resolution (one shown in the picture). Insert will insert the picture to illustrate the article and all its extracts and clozes. The remaining thumbs will be available for download in all portion of text that refer to their corresponding images.
For more, see: Visual learning
Topics vs. Items
In SuperMemo you see pieces of information presented to you in 2 basic forms:
- topics: these are usually longer articles that you want to read
- items: these are usually specific questions that you will need to answer
Topics and items are presented in a different manner and at different times. Topics keep the knowledge you want to learn (i.e. things you want to read about), while items keep the knowledge that you want to remember (i.e. the knowledge you already posses, but might forget).
Topics
A topic in SuperMemo is an article, its part, or a sentence that you want to learn. Topics can also have a form of a picture, a video, a piece of music, etc. Unlike items, topics donot test your knowledge. They are used in passive reading, watching, or listening only. Short text topics are used to generate cloze deletions. Topics take part in the incremental learning process. Once they are converted to items, they are often dismissed (i.e. ignored in learning) or done (i.e. deleted from the learning process altogether). Both Done! and Dismiss must be executed by the user (i.e. they are not automatic).
Using topics
Topics are marked in Contents with a green T icon (![]() ). Topics may be very long (entire articles) or very short (single sentences). This is how you work with topics:
). Topics may be very long (entire articles) or very short (single sentences). This is how you work with topics:
- read the topic from the top
- if you find some interesting information, extract it (e.g. with Alt+X); the extract will form a new independent topic; the new topic will be shorter and will be handled in the same way as all other topics
- decide how far you want to go into reading the topic depending on its priority and available time (e.g. interrupt fast, if you are in a hurry, or read it all, if the topic is of top importance)
- if you finish reading the topic, execute Done! (e.g. Ctrl+Shift+Enter); this will delete the topic without deleting the material that it produced
- only if the topic is as short as a single sentence, create cloze deletions (e.g. with Alt+Z)
- return to reading the topic next time it comes for review
On longer topics you read and extract, on very short topics you generate cloze deletions.
Items
Item in SuperMemo is a piece of knowledge that you want to remember. It usually has a question&answer form. The main difference between an item and a topic is that an item actively tests your memory (e.g. with a question), while a topic is used for passive review only (e.g. for reading, viewing, watching, etc.).
Reading overload
Overload occurs when the student has more outstanding items or topics to review than (s)he can handle. Few users can sustain more than 200 item repetitions per day. When the Outstanding parameter in the Statistics window starts going above that number, overload is likely.
Overload can best be handled with Auto-postpone. However, a one-time big load can be resolved efficiently with Postpone (delaying all elements), or Mercy (spreading all review intime).
You can also postpone a specific topic with all its extracts using the following method:
- Go to the topic in question
- Press Ctrl+Space to open the topic, its extracts, and clozes in the browser
- Choose Process browser> : Postpone on the browser menu
Note that you may need to use Learning : Locate extracts on the element menu if you have moved portions of your learning material to other branches.
See also:
Auto-sort and auto-postpone
As long as you prioritize your learning material well, you should make your life easier by checking the following 2 options:
- Learn : Sorting : Auto-sort repetitions that results in sorting your outstanding queue by priority at the start of each day.
- Learn : Postpone : Auto-postpone that results in postponing outstanding repetitions of lower priority at that start of each day. It ensures you do not get overloaded,
and it ensures that you minimize delays for top priority material.
Auto-postpone always leaves a number of top-priority elements in the queue. The purpose of the postpone is to get rid of the main mass of low-priority material and focus on top-priority material. You aremost likely to use Postpone after a day of learning, while Auto-postpone is executed before your learning day begins. This is why it never affects today's material, and does not postpone top-priority material from previous days. If you have Auto-postpone checked on the menu, you will always start the day with all the repetitions scheduled for that day, and a number of unexecuted top-priority repetitions from previous days. Even though Auto-postpone increases the intervals and reduces the retention of low-priority material, it also makes you benefit from the spacing effect. Research shows that longer intervals may paradoxically increase the speed of learning (up to a certain point). This comes from the fact that the default retention in SuperMemo (around 95%) is higher than the retention that delivers the largest number of items remembered per unit of time invested.
You can start with default settings of the sorting criteria, however, if you feel you make insufficient progress with items (e.g. high forgetting index), you can reduce the proportion of topics. If the inflow of new material is too slow, you can increase the proportion of topics. If your priorities are imperfect, increase the degree of randomization. If you think you miss too many high priority items (see: Tools : Statistics : Analysis : Use : Priority protection from the main menu), reduce the randomization. By trial and error, you will arrive at your optimum. Even after you find your optimum, keep experimenting with different randomization and topic levels. This will help you avoid various cognitive biases that develop through the routine of learning. It may also be helpful to execute random review from time to time (just to get a general feel of your overall progress).
With Auto-sort and Auto-postpone, you will nearly never have to worry about material overload. Each time you start SuperMemo for the first time on a given day, it will first postpone repetitions that you failed to execute on previous days. It will use default postpone criteria which you can always modify (e.g. with Learn : Postpone : All elements). After postponing the backlog of repetitions, SuperMemo will sort today's repetitions and those that were left outstanding by Auto-postpone. Auto-sort will use sorting criteria specified earlier with Learn : Sorting : Sorting criteria.
With Auto-postpone and Auto-sort, you can always begin your day with a manageable portion of material sorted by priority. Your learning sequence will be optimized with no action on your part (i.e. no options to choose, and no keys to press).
Hints
- With or without Auto-postpone, your only sure remedy against forgetting is always the same: complete your repetitions!
- Auto-postpone affects all days except for today. If you have low-priority topics scheduled for today, Auto-postpone will delay them only tomorrow and only if you do not review them today. This is to ensure that low-priority topics also have a chance to enter repetitions as determined by your Randomization/Prioritization balance in the sorting criteria
- In the Postpone dialog, Skip the following number of top priority elements skips only elements that were skipped by Skip conditions on the Parameters tab. It will not protect elements from being postponed if they are not protected by the postpone criteria. Whatever the value of this parameter, you can still have all your elements postponed. You can best view it as a pro-postpone parameter that is used to force extra postpones (not an anti-postpone parameter that protects your from extra postpones). Skip here means "skip postpone protections" not "skip postpones"
- Simulate in Postpone can be used to tell you how well your current postpone criteria work. It ignores Skip the following number of top priority elements because this parameter needs no simulation (it will always enforce skipping the said number of elements protected from Postpone by the postpone criteria)
Subset review
Subset review is a review of a portion of the learning material (e.g. before an exam). The portion may be identified with search, by branch selection in Contents, by category, and other means that determine a subset of elements. The reviewed subset material may be sorted by its sequence in the knowledge tree (Contents), priority, difficulty, interval, retention, recency, etc.
Review types
Search and review
Search and review in SuperMemo is a review of a subset of elements that contain a given search phrase. For example, before an exam in microbiology, a student may wish to review all his knowledge of viruses using the following method:
- search for all elements containing the phrase virus (e.g. with Ctrl+F)
- review all those elements (e.g. with Ctrl+Shift+L)
The review may include all subset elements (e.g. Learning : Review all in the browser with Ctrl+Shift+L), or only the elements that are outstanding for review on that particular day (e.g. Learning : Learn in the browser with Ctrl+L). Before you execute the review, you can randomize the review material (Ctrl+Shift+F11), sort it by priority, by recency, by interval, by size, by age (in the learningprocess), etc. You can also apply your default sorting criteria with Ctrl+S in the browser. All forms of review run on all elements except for (1) dismissed elements and (2) those elements that have already been processed on this particular day. The latter condition makes sure that you can do a comprehensive review in various subsets without duplicating your work on a given day. You can overcome the block of double review on a given day by using Add to outstanding (see below).
If you build an extensive collection of things worth learning, subset review may help you learn about Subject A, and do a value-rich review of your material across many others domains at the same time! You kill many birds with one stone.
Search : Find elements makes it possible to define OR-searches and to save search definitions. This way you can, for example, choose a set of terms that define your "diabetes" subset and use them each time you want to review your "diabetes" material.
The parameter Subset in the Statistics window indicates the progress of repetitions in subset learning. This field displays the number of items, the number of topics, and the number of pending elements in subset learning. The name in the parentheses describes the currently processed subset.
Branch review
In the simplest case of branch review, the button Learn at the bottom of the contents window can be used to execute outstanding repetitions on a selected branch of the knowledgetree. For example, to make repetitions in the Medical Sciences branch, click that branch and then click Learn. Using Learn in the contents window is like using Learn in the element window, except only elements belonging to the selected branch will be considered in making repetitions.
To thoroughly review a branch of knowledge (including non-outstanding elements), do the following:
- Select the branch in Contents
- Choose Learning : Review all on the Process branch> menu (Ctrl+Shift+L)
Random review
To randomly review a branch or a subset:
- open the branch or subset in the browser
- randomize the content of the browser (Ctrl+Shift+F11)
- execute a review (e.g. Learning : Review all on the browser processing menu)
Review modes
In a browser subset, in a contents branch, or in the entire collection, there are 3 main ways of executing subset review:
- review only the outstanding material: Learn (Ctrl+L) will execute only the outstanding repetitions, i.e. the elements that have been scheduled for review today or before today
- review all the material: Review all (Shift+Ctrl+L) will execute all outstanding repetitions as well as force mid-interval repetitions on all elements in a subset (except those elements that have already been reviewed today). Review of non-outstanding elements is equivalent to Learning : Execute repetition (Shift+Ctrl+R) available from the element menu
- review all topics: Review topics works like Review all but it does not include items, i.e. it forces a review of all topics in a subset (except topics that have already been reviewed today). Each time you do subset review on a set of items, you add some extra time to the total cost of learning of that portion of the material. This is why you may wish to exclude items from a review that occurs often
All the above options are available on Process branch> : Learning submenu of the contents menu, or Process browser> : Learning submenu of the browser menu.
Adding elements to the learning queue
Instead of spending your time on a thorough review of a branch or subset, you may prefer to intersperse the review material in your standard learning process. You can do it with Learning : Add to outstanding.
Add to outstanding is a rationalization upon 2 extremes:
- well-timed incremental learning (or classical spaced repetition)
- subset review (e.g. before an exam)
On one hand you can proceed with your outstanding queue, on the other, you can smuggle some subset review in between. For example, you might learn about the superiority of "intermittent fasting" over "fasting". You will want to investigate the subject to perhaps employ it in your lifestyle. However, you do not want the subject to be buried in thousands of articles you keep reading. Nor do you want it to monopolize your learning time on a given day. You can import several articles on intermittent fasting and spread them sparsely in your outstanding queue with Add to outstanding. By the end of the day, you will have a peek at all those articles, have them all well prioritized, and integrated with the learning process (in proportion to the value of the newly discovered content).
An alternative to Add to outstanding is to spread priorities (with Priority : Spread), however, it has 2 flaws:
- you will not get the instant gratification from the instant review of a hot topic
- you risk that new imports will displace the articles of interest before you manage to give them a preview
In other words, Add to outstanding is a more extreme version of Priority : Spread, but not as radical as Learning : Spread in the browser (irreversible rescheduling), or subset review (reversible review).
Repeating items before topics
If you ever neglect learning, you may wish to unload your item backlog ahead of your topic backlog. You can optimally do it with a change to your sorting criteria. However, you can also start your day from 100% item repetitions:
- Choose View : Outstanding
- Sort repetitions by type (items first)(e.g. by clicking the header of the Type column), or choose Child : Items
- Choose Learn on the browser menu to make repetitions (or Tools : Save repetitions on the same menu to make the sorting permanent)
Ideally, in incremental reading, you should have items and topics mixed up. This will help you achieve balance between retention of the old material and the inflow of the new material. By working with items first, you risk slowing down learning by working on high retention. That's a step back to classical SuperMemo.
Semantic review
If you want to semantically connect a group of elements related to a single subject in incremental reading, you can use subset review based on the elements' tree structure created in the incremental learning process. This way you can quickly review all elements related to a topic whose "big picture" became hazy.
- go to any element that makes a part of the knowledge structure related to given problem
- use the Reference link button (
 ) on the navigation bar to get to the original article
) on the navigation bar to get to the original article - use Contents to find a relevant subbranch (or stay at the root of the article to review it all)
- browse the selected branch (e.g. with Ctrl+Space)
- choose Learning : Review all (Shift+Ctrl+L) to review all elements in the logical/semantic sequence (the sequence of branches reflects the order of processing of individual paragraphs in the article)
You can also choose Learning : Learn branch on the element menu to begin branch learning for one of the ancestors of the currently displayed element. You can use this method if you encounter interesting material that you would like to refresh more thoroughly before you proceed with your standard learning process.
Advance
Advance is not a form of review. However, it makes it possible to shorten the intervals and speed up the review. For example, if your exam comes in 100 days, you can shorten all intervals in a subset to less than 100 days with Advance.
The Advance operation will not work on 2 kinds of topics:
- those whose interval is shorter than the advance interval
- those who have been repeated today (use Learning : Add to outstanding if you need to go around this limitation)
Examples of subset review
Example 1: search and review
If you would like to review the material related to Auguste Comte (1798-1857) do as follows:
- Press Ctrl+F and paste Auguste Comte in the search box
- Press Enter or click Find (this will search your collection and open a browser with the results)
- Choose one of the subset learning options:
- to prevent forgetting: press Ctrl+L or choose Process browser> : Learning : Learn to review only the outstanding material. This will help you review only the items that are most likely to be forgotten and a portion of topics that have been scheduled for review for today
- to learn new things: choose Process browser> : Learning : Review topics to review all topics related to Auguste Comte
- to maximize the review (e.g. before an important deadline): press Shift+Ctrl+L or choose Process browser> : Learning : Review all to review all topics and to force a repetition on all items related to Auguste Comte. Remember that premature review of items may paradoxically slow down your long-term learning
Example 2: branch review
If your history exam is approaching and you cannot cope with all repetitions in the collection, make sure that at least your daily portion of history is thoroughly reviewed:
- Select History branch in the contents window
- Click Learn at the bottom of the contents window
Repeat the procedure daily. However, in the last 3-5 days, you could follow that yet with Process branch> : Learning : Review all to protectively refresh the material that would optimally be scheduled after the exam.
Important! The frequent use of Review all is not recommended for long-term learning! It departs from the optimum timing for review to consolidate memories. It should only be reserved for situation when burning school situation forces you to neglect your long-term planning.
If you have final drill enabled, remember that subset learning does not keep a separate final drill queue and elements that score less than Good (4) are put to the global final drill queue.
Hints and tips
Importing articles
- Importing articles from Wikipedia is easiest:
- to search for Wikipedia articles press Ctrl+F3, type in some keywords, choose Wikipedia, press Enter, and right-click on articles of interest
- to search for an article on a subject you are reading about, select a portion of text and press Ctrl+F3. Choose Wikipedia as described above
- to import Wikipedia articles from Internet Explorer, press Shift+Ctrl+W (Edit : Import web pages : Wikipedia on the main menu)
- To quickly import many articles from the web, do the following:
- find the articles (e.g. with Google),
- open them in Internet Explorer,
- in SuperMemo, use Shift+Ctrl+A (Edit : Import web pages : All from the main menu)
- To quickly search for articles on the subject you are reading about, select a portion of text, press Ctrl+F3 and choose Google
- To type your own notes in SuperMemo use Alt+N (Edit : Add to category : Note on the main menu)
- If you would like to store pictures locally on your hard disk (in the image registry), and make them proliferate in incremental reading (e.g. show up in all extracts even if the extracts do not include the picture, etc.), then you must import the pictures to image components using one of the following methods:
- to import pictures included in a single article use Ctrl+F8 (Download images on the component menu), select images and click Insert
- to import pictures from the web, use Copy on the picture in your Internet browser and then press Shift+Ins or Ctrl+V in SuperMemo to paste the picture (if the picture does not paste, press Esc a few times to get to the display mode and try Shift+Ins or Ctrl+V again)
- to import many pictures from many articles in Internet Explorer, use Edit : Import web pages : Pictures) and choose Local images only or Page of images as the import mode
- to optimize the tiling of many pictures after the import, use Components : Tile components on the element menu
- see also: Adding pictures to SuperMemo
- Instead of scanning paper books and doing OCR for the sake of incremental reading, always begin with looking for electronic equivalents. In most basic areas of knowledge, there are multiple sources of learning materials available. There are fewer and fewer cases where you need to do any scanning. These days, you can even be finicky and search for HTML texts to replace your nice PDF materials (to avoid the pain of converting PDF to HTML)
- Some texts rich in pictures and tables may be handled with difficulty by SuperMemo (the older the SuperMemo, the more difficulty you may experience). It may be very useful to learn to use HTML filters (press F6). Some of the problems stem from bugs in Internet Explorer that SuperMemo employs to display and edit texts formatted in HTML. This particularly refers to older versions of Internet Explorer (e.g. IE 6.0). It is therefore highly recommended you install Internet Explorer 7 or later to make your life easier
- If you are pressed by exam deadlines and still not too fluent with incremental reading, it would make more sense to do some of your old and new learning in parallel. For example, 30% incremental reading and 70% traditional learning. You are bound to make many mistakes in strategy and the discovery process may take longer than until the exam. At the beginning you will have a big overhead cost (strategy, material selection, formulation, learning SuperMemo itself, etc.). It would not then be surprising if your performance on the exam actually dropped at your first try! You could pick a couple of chapters that you particularly enjoy and use them in your incremental learning practice. You would then process the rest of the material using your old methods. You cannot possibly embark on a massive conversion of textbooks into SuperMemo material before you get the feel of how to do it right! It can backfire and discourage the use of SuperMemo. As always, proceed carefully and incrementally
Inflow of new articles
- SuperMemo uses 2 basic element types: topics (articles) and items (questions and answers). Those are treated differently in the review process. Topics represent what you want to know, while items hold what you know. To better understand the difference, see: Topics vs. Items
- Keep your topics/articles in check. Use your sorting criteria to make sure you get a solid dose of daily items/questions in addition to your reading. High topic overload may slow your item flow and damage the active recall process. High topic load will make SuperMemo resemble traditional reading where your retention is unacceptably low. You can decide your optimum ratio on the basis of time needed for repetitions. For example, 5:1 item:topic ratio would probably still make you spend more time on reading than on reviewing. Increase that ratio to increase your retention, reduce the ratio temporarily if you need to do a great deal of reading. If you are not sure, set items:topics to anywhere between 3:1 and 8:1. Still too hard to decide? Review 5 items for each topic in the outstanding queue.
- Tools : Statistics : Statistics : Protection can be used to inspect your progress in processing top priority material on a given day
- Tools : Statistics : Analysis : Use : Protection can be used to inspect the degree of processing of your top priority material over time
Reading
- While reading, you can display the Read toolbar on the learnbar by clicking the Reading options button (
 ). You can also choose Window : Toolbars : Read to place the toolbar in a convenient place on the screen and press Shift+Ctrl+F5 to save the current layout of windows as the default one. The toolbar may be helpful before you learn to use the keyboard to access all its functions
). You can also choose Window : Toolbars : Read to place the toolbar in a convenient place on the screen and press Shift+Ctrl+F5 to save the current layout of windows as the default one. The toolbar may be helpful before you learn to use the keyboard to access all its functions - If you do not like the large spacing between the lines when you press Enter, use Shift+Enter. Remember this trick! Many users struggle for months with line spacing only to discover this precious tip. This tricky behavior is by Internet Explorer, not by SuperMemo
- Once you finish processing the article, use Done! () on the learnbar or Done from the element menu (e.g. with Ctrl+Shift+Enter followed by all necessary confirmations with Enter). This will clean up your learning process without affecting the work you have done (all extracts and clozes will remain in the learning process). Done! deletes (1) the article, (2) its repetition history, (3) its components, etc. However, it leaves the original empty element as a source of reference and as a holder for the derived structure of extracts and cloze deletions. Done! is executed at the moment when you believe you have completed reading and processing a given piece of text. This usually means skipping all unimportant parts and extracting all important parts of the article. You repeat Done! on all topic extracts generated from the article. You will quickly discover that keeping the original articles for reference only clutters your collection, increases its size and produces an excess of search hits. Getting rid of the original is usually the preferred action. You can always get to the original article on the net using its reference link
- If you return to an interrupted article in the learning process, the cursor in the text is set on the last-processed text. That text selection is called a read-point. When leaving the article, you can also manually set the read-point' at the place where you interrupted reading. Choose Ctrl+F7 to set the read-point, or click the set read-point button (
 ) on the Read toolbar
) on the Read toolbar - Highlighting texts automatically sets the read-point
- Use Clear read-point (
 ) on the Read toolbar, or press Ctrl+Shift+F7, to remove the read-point
) on the Read toolbar, or press Ctrl+Shift+F7, to remove the read-point - Enter is the default key used when progressing through the learning cycle. When a read-point is selected and you press Enter, instead of inserting a new line, SuperMemo will automatically begin or resume repetitions. This will also be the case if you make any selections in the text. Enter will play its usual function only if there are no selections in the text. Although using Del and Enter instead of just Enter in these circumstances may seem cumbersome, you will quickly find this behavior indispensable in learning. If you still do not like this Enter behavior despite giving it a try, set Allow Read-Point Enter=0 in supermemo.ini
- If you use Delete before cursor, you may be annoyed by lack of Undo. However, if you mistakenly delete important texts (e.g. when using After instead of Before), you can find a temporary backup of the deleted text in collection's \TEMP folder (the file is named Last text portion delete with element number and delete time appended). The backup file is deleted only at Repair collection or at Garbage, i.e. it will not disappear if you quit the element
- Horizontal lines can be used to split articles. If you insert a horizontal line and call Split article, the article will be split into separate elements. Split article is also available from the Commander. To insert a horizontal line press Shift+Alt+H or type <hr>, select it, and press Ctrl+Shift+1 (or choose Text : Convert : Parse HTML on the component menu). Parse HTML (
 ) is also available on the learnbar
) is also available on the learnbar - Use Ctrl+] and Ctrl+[ to change the size of the font in the selected text
Generating clozes
- In incremental reading, you should always strive at converting passive texts into active questions. Ideally, all passive texts should be deleted when done with. All interference from "outside world" makes SuperMemo less precise. Passive texts provide little extra help in learning. At the same time, they provide interference, and should only be used to generate new clozes (or for reference)
- When you press Alt+Z, the currently selected keyword in the current topic is marked as clozed. The newly created item is not visible (i.e. you will not immediately see the answer nor the deletion brackets). You can see the newly created item by pressing Alt+Left arrow. Use that key to edit the newly created cloze (e.g. to add context clues, shorten the text, improve the wording, etc.). However, if possible, you should do such mini-jobs incrementally, i.e. on the next encounter with the clozed item
- Before you apply Cloze, you should make sure that the processed statement or paragraph is as simple as possible. You should try to use only one-sentence extracts to generate cloze deletions! Some newcomers dislike incremental learning at first. Monster cloze deletions are a chief reason for their negative feelings. Simplifying the parent paragraph to a simple statement will produce simple clozes that will require little processing. Using Cloze on complex texts multiplies the cost of re-editing when simplifying texts (in all cases where you cloze more than one keyword). If you use Cloze on a longer multi-sentence paragraph, you will have to put extra effort in simplifying the resulting items. All cloze deletions should be short enough to ensure you read them entirely at repetition time. Otherwise, your brain will tend to "deduce" the answer from non-semantic cues. This will defeat the purpose of learning! By using one-sentence extracts for cloze deletions, you will save ages on repetition time and eons on time needed to simplify clozes and converting them to the final form based on the minimum information principle
- Your work on extracting fragments, producing cloze deletions and editing them should be incremental. In each review, do only as much work on the learning material as is necessary! Extracting and editing in intervals adds additional benefit to learning and is more time-efficient. Each time you rethink structure and formulation, you hone the representation and "connectivity" of a given piece of knowledge in your memory. In addition, your priorities change as you proceed with learning. At times, you will over-invest in a piece of knowledge that quickly becomes irrelevant or out-dated. The incremental approach will reduce the impact of over-investment. Incrementalism should then be used not only while reading, but also in the follow-up processing and formulation of knowledge. See: Examples. Unless you work with top-priority material, do not generate all your cloze deletions in one go. Make it incremental. Generate a cloze today, and another one at the next review. The incremental nature of the learning process, variegated coloring of texts marked with processing styles, and a complex extract hierarchy seem to quarrel with the perfectionist nature of many. However, the purpose of incremental reading is the maximum effect in minimum time. For that reason, at extract time, you are already forming passive trace memory engrams of the extracted sentence. The optimum strategy then is not to proceed with generating cloze deletions, but to move on to other elements in the queue or to other extracts in the same article (if the high priority of the article justifies it)
- Once you finish processing a paragraph with cloze deletions, use Done! () on the learnbar or on the element menu (e.g. with Ctrl+Shift+Enter). This will clean up your learning process without affecting the work you have done. All clozes will remain in the learning process. Done! deletes the extract/paragraph, however, it leaves the original empty element as a holder of the derived cloze deletions. Once you believe your cloze deletions cover all vital keywords of the statement that forms the topic, you execute Done! again. In the end, only cloze items remain in the learning process. Note that the process of descending from the source article to individual clozes may take years. The whole process is incremental and is paced by the declining traces of memory. A single cloze generated from a short sentence often allows of retaining good memory of the entire statement for months. Except for mission-critical pieces of information, you do not execute cloze deletions on all keywords until individual keywords raise questions as to whether they can be recalled individually
- Converting to plain text: Plain text takes much less space. Collections rich in plain text are faster to back up. You can convert short pieces of HTML to plain text as long as they do not contain formatting information that may be needed to effectively remember the text. In the long run, simple plain text items might do their work better by depriving you of additional cues carried by the formatting. Leave some of your items as HTML and convert some to plain text. After some time you will probably have your own preferences as to which do their work better
- After generating a cloze, the last character remains selected. On one hand it indicates which keyword has just been processed, on the other, selections make it possible to use Enter to move to the next element in repetitions
- If you keep getting questions about the template to use at cloze, use Search : Categories to inspect the category to which you imported the article and uncheck Auto-Apply
- You can change the appearance of extracts and cloze deletions with stylesheets. See: Changing the appearance of cloze keywords
Changing the appearance of cloze keywords
This is how you can modify the default cloze style in SuperMemo:
- From the main menu, select Tools : Options
- In the Options dialog box, click the Fonts tab
- On the Fonts tab, click the Stylesheet button
- In the SuperMemo Stylesheet dialog box, select the Clozed option in the drop list at the top; then use Font, Color, and Background buttons to set individual properties of that style
Removing cloze keyword formatting
Display the HTML code behind a given cloze text (e.g. with Ctrl+Shift+F6). In the HTML code, replace class=clozed with an empty string.
| Before | After | |
|---|---|---|
| HTML | This is my example <SPAN class=clozed>element</SPAN> | This is my example <SPAN>element</SPAN> |
| WYSIWYG | This is my example element | This is my example element |
Your cloze keywords will be formatted in the same way as the surrounding text.
Mimic real life situations to combat memory interference
Some texts present knowledge in the form that is difficult to remember. Lists and sets are a good example of knowledge that does not stick to memory. Even if you perfectly know the map of Africa, answering the request: "List all countries of Africa" may be pretty hard. There are proven techniques that will help you tackle repetitive, list-rich, or boring knowledge with SuperMemo. All solutions are costly at memorization stage, but will pay handsomely in the long run due to lesser forgetting rate. The basic 2 principles are:
- gradually glue individual pieces to your overall knowledge structure
- be as visual and mnemonic as possible
Here are some specific hints:
- use a mind map: search the net for a nice mnemonic picture of the subject studied (e.g. political map of Africa). The picture will provide the basic skeleton for your memory. Like ornaments on a Christmas tree, you will hang new pieces of knowledge on this mnemonic skeleton. Use the picture to illustrate all topics and items in the studied category.
- do not learn it all at once: Add individual items gradually at a point when they acquire some special meaning. Add them when they fit snugly with the rest of your knowledge. Add them when you specifically need them or when you learn about a related subject. If you need enumerative knowledge for an exam, cram it using traditional methods, and still continue adding individual pieces in unique contexts later on when you feel they are interesting or important.
- associate with stories: if you ask an expert in the field, you will probably hear that (s)he mastered enumerative knowledge by association with individual case stories. Whatever he or she learned at school was quickly forgotten, but individual cases or problems to solve leave a good and durable imprint due to their uniqueness. Once you hit upon a story that is relevant to your hard-to-remember items, try to learn those items in the context of that particular story (e.g. hang the Cameroon up on your knowledge tree only when reading about Eto's move to Chelsea). If you encounter cases in the course of your practise, describe them shortly and use them to supply context.
- supplement with incremental reading: instead of formulating all items along the same repetitive and monotonous template, try to use incremental reading to generate cloze deletions that work on separate storylines. Ideally, you would review your topic and generate just a single subtopic (e.g. on a single country in Africa). Always choose the one that seems most obvious or most important to remember. Always try to add some supplementary material. Be sure you do not provide clues that will make you answer correctly without forming an appropriate association
- compare with experts: ask an expert in the field how (s)he remembers a given fact or association. In some cases you may be dismayed to see how poorly experts recall compulsory college material. At other times, you will see how their memory tackles the problem with ease by using a simple mnemonic. This will help you emulate real life learning at a compressed timescale without ever wasting time on trying to master what others never manage to master anyway. That's the basic difference between school learning and your efficient incremental learning: you do not cram it dry along a rigid prescription. You use your creativity to incrementally build a durable structure of useful knowledge!
Example: dealing with enumerations
If you happen to learn the geological periods, you are bound to generate nasty leeches, esp. if you are new to the subject. Using the top-down learning rule, be sure you know the eras, before you learn the periods, and before you move on to the epochs, and further down the tree of knowledge.
A typical mistake would be to start from cramming the meaningless sequence of periods. For example, clozing the Paleozoic Era sequence: "Cambrian, Ordovician, Silurian, Devonian, Carboniferous, Permian" could result in a question that is bound to cause problems: "Cambrian, Ordovician, [...], Devonian, Carboniferous, Permian". This cloze will trouble anyone who is not privy to the field. In other words, only those who come with the knowledge ready in their mind will be able to tackle this type of question at little cost! Conclusion: there is no point in learning lists the hard way unless you already know what you are trying to learn! Catch 22!
Instead of using the above approach, it would make far more sense to first anchor the Silurian period in your mind with some meaningful event. For example, the appearance of the bony fish. This way, we might start with a cloze based on "The bony fish appeared in Silurian (443-419 mn years ago)". The following question will be far easier to remember: "The bony fish appeared in [...](period)(443-419 mn years ago)". Even if the answer is the same as in the original unfortunate cloze, that question is not semantically equivalent. You will need more cloze deletions. However, working with similar sequences should always proceed incrementally and in proportion to anchoring individual periods in memory. Later on you can move on to clozing dates, epochs, and other details. All the time you should try to add new interesting anchors and work with the material in parallel to the inflow of meaningful information that is likely to stay long in memory.
Learning
- Use Ctrl+W (Tools : Workload from the main menu) to view the calendar of repetitions. Double-click a day to see which elements will be reviewed on that day. You can also inspect which elements had been reviewed on individual days in the past (switch from Workload to Repetitions mode)
- To inspect the number of today's outstanding elements, peek at the status bar which can be saved at the bottom of the screen in the default layout. You can also look at the Statistics window (e.g. with F5). The Statistics window can also be saved in the default layout (with Ctrl+Shift+F5)
- The optimum time allocation for reading (topics) and learning (items) depends on a number of factors: the subject and the importance of articles, their difficulty, fun factor, your interests, your preferences, your knowledge, your mood, your circadian cycle, etc. The optimum allocation of time can vary from seconds to hours! This is one of the factors where the power of incremental reading comes from. For some texts, you may find it difficult to reach reasonable attention levels for longer than a few minutes. Often you can retain your maximum processing power for just a single sentence or paragraph. On other texts that are highly interesting, well written, highly useful, or highly important, your curiosity and rage to master may kick in and let you go on for several hours without a break. In incremental reading, the primary criterion for time allocation is your level of concentration. You can literally lick a hundred articles in a continuous block of time and still keep your mind highly focused and alert. Some articles will be processed in depth, others will be quickly postponed. The concentration criterion is all-inclusive. It includes all factors listed above: difficulty of an article may affect your concentration, your tiredness will always reduce optimum allocations for difficult texts and increase allocations for interesting or enjoyable texts (those who help you "survive" a bad learning day)
- You can leave some low-priority material in the passive form (i.e. without generating cloze deletions). Naturally, this material will gradually become difficult to recall or entirely forgotten. The best moment for using Remember cloze is when you notice that the material becomes volatile. Do not convert the entire passage into clozes at once (unless it is very important). Pick the most important keyword and create just a single cloze deletion. When the next review of the passage comes along, you will be able to determine which other keywords must be used with cloze deletion to prevent forgetting the key information. It is very difficult to predict how many clozes you will need to generate to attain perfect recall of the whole passage. On occasion, a single cloze suffices. At other times, a single passage can require a dozen of clozes!
- The better you get, the more often you will want to resort to incremental learning. The stronger your incremental learning skills, the shorter the working period that makes employing incremental learning effective. For a proficient user, even a next day's assignment might make sense to be done with incremental learning tools. For a beginner though, it is enough to consider that it may take you a few months of practise to truly understand the flow of knowledge in incremental reading (and in your memory). This alone might make it ineffective in learning for a test that comes in a month or two
- Auto-postpone brings you closer to the ideal spaced repetition learning by reducing the load of low priority material that you cannot possibly master due to excess volume. In a sense, auto-postpone separates high priority material (spaced repetition) and low priority material (traditional learning). Without it, you are stuck in the middle of those two extremes
- You can increase the randomization of your material by adding to Randomization degree in sorting criteria (Learn : Sorting : Sorting criteria from the main menu). Randomization can be set separately for topics and items. It should help you avoid tunnel vision and the priority bias
- You can shorten or increase the interval for individual elements. If you want to schedule a given article for review on a selected day, choose Learning : Reschedule on the element menu (e.g. by pressing Ctrl+J). You can also use Learning : Execute repetition (e.g. by pressing Ctrl+Shift+R). Execute repetition works like Reschedule with this difference that a repetition will be executed before rescheduling. Choose between the two depending on whether you have seen the contents of the item and have attempted to recall it from memory. Execute repetition requires providing a grade (unless you execute it on day when a repetition has already been done).
- For items of lesser importance, reduce priority (Alt+P), increase the interval (Ctrl+Shift+R), or even increase the forgetting index. Forgetting index can be used to optimize the trade-off between the knowledge acquisition rate and knowledge retention. Giving items low priority in an overloaded collection is similar to giving it a higher forgetting index.
- The degree of damage incurred by material overload can be seen in Tools : Statistics : Analysis : Use : Priority protection. On one hand you want to increase the value of Priority protection. On the other, limiting the speed of importing new articles in proportion to the progress of learning might make your collection "get stale" resulting in less fun in learning and lesser motivation. Some older articles may be pushed away to lower priorities by overload only to be deleted later as not important enough, not good enough, or outdated
- You should never stop thinking about the value of items that you keep in your memory. See: Re-evaluation of items
- Use Spread in the browser to change the distribution of your learning material in time. You can speed up learning before an exam by compressing your learning schedule in a selected period. You can also redistribute the material in a longer period after a boring exam (for incremental review, re-learning, deprioritization, and/or elimination). For that latter job, you can choose a specific portion of the material to be served per day. Read about Mercy
- Derivation steps in reasoning/mathematics. If you are learning mathematics, you might wonder if you should commit individual derivation steps of a mathematic proof or solution, or should you just focus on the final outcome. The choice will depend on your goals. If you only need the final formula, time spent on learning the derivation steps could be better spent learning other important portions of the material. If you are not sure today what you will need in the future, you could just type in the whole derivation into a single topic and memorize the final formula. Later, in incremental reading, you will make incremental decisions whether portions of the derivation are or are not important in your work or further learning. This piece of knowledge will compete with others in the learning process and in the long term you may ultimately decide if you want to memorize the details, keep them for passive review only, dismiss/delete some of the steps, or dismiss the entire derivation as redundant (or too costly to learn). Naturally, derivation will often enhance your ability to efficiently use the formula. Hence the decision is never easy. Once you have derivation steps committed, you can always play with their priority to determine the probability you will review them well enough to make a difference to your knowledge.
- You can separate reading (topic) from review (items). However, variety is a spice of life. A random mix of reading and repetitions is a very powerful tool in overcoming the monotony of the earlier versions of SuperMemo. Interspersing topics with items provides for many of the advantages of incremental reading as opposed to traditional learning or classical SuperMemo. To review topics only (reading) choose (1) View : Outstanding, (2) Child : Topics and then (3) Process browser> : Learning : Learn (Ctrl+L). To make repetitions only (items), use an analogous method. It might be a better strategy to mix topics and items during the reading phase, and consolidate knowledge by making item-only repetitions later in the day. In the end, sticking to priorities, auto-sort, and auto-postpone will be the best least-biased long-term strategy
- Fun is the key to success: If your learning text is too "dry", not too meaningful, too wordy, etc. the fun of learning will drop. If learning is not enjoyable, it is less likely to be effective. If you dislike a specific article, perhaps a Wikipedia replacement would be fun and more meaningful? Even if this is a bit longer, you can process it pretty fast with incremental reading, illustrate with pictures, and enjoy the process
- Nurse your hunger for knowledge: You have to find the clear-cut link between knowledge and the value it brings to life. The hunger for knowledge grows as you get more educated (the more you know the more you know you don't know). So there is an excellent remedy for poor motivation: learn more and see how it can impact your and others' life
- You determine the speed of learning in incremental reading! You can determine the frequency of presentation of topics (e.g. using A-Factors, priorities, Mercy, etc.). You can determine the level of retention for items (e.g. with the forgetting index, priorities, auto-postpone, etc.). You can execute forced ahead-of-time review of any material (see: Subset review)
- You MUST NOT memorize material that you do not understand! There is some hope that by doing more learning in other areas you will at some point understand. It is far more likely though that you will build up frustration with items that mean little. If you do not understand a term or concept, you need to dig deep into why. Is it terminology? This can be easily investigated and fixed. Or is it a problem with the material itself? Perhaps you can find an alternative on the net? Perhaps you can find a nice picture on the net to illustrate the item? Obviously, each little investigation takes time, but it is better to master 10-20% of the material well, that to cram an encyclopedia without comprehension. Even if you fail an exam, those 10% can be useful in the future (e.g. if you retake the exam). In general, schools load more than students can master and this leads to lots of stress and frustration. By choosing SuperMemo, you have already made the first good step. Now you need to make order in the process and think carefully about your best long-term strategy. Comprehension is the key to success!
- If you want to grade an item Null or Bad, press 0 or 1 respectively
- SuperMemo is not yet equipped with tools to help you efficiently use your knowledge for good causes. It will boost your knowledge but... you must be vigilant: Do not spend your time on gaining knowledge for the knowledge sake! Think applicability! Luckily, as your knowledge grows, so does your ability to use it efficiently
Re-evaluation of items
You should remember that all items introduced into your learning process require endless attention in reference to their applicability, formulation, importance, logic, etc. In a well-planned learning process, it should not be necessary to review items in the periods between individual repetitions. However, when an item comes up for a repetition, you should make a quick and nearly instinctive assessment of the following:
- Do I really need this item?
- What is the honest priority of this item in the entire spectrum of my (desired) knowledge?
- Is this item difficult to remember? If so, why?
- Is it factually correct?
- Is it as simple and clear as it could be?
- Do I really need to know it now?
- Do you need supplementary knowledge to understand all ramifications of the item?
Here are some typical actions you will take depending on the answer to the above questions:
- edit the item. You will use keys such as Q, A, or E to enter a desired text field and edit it. In more complex items you will use Ctrl+T to circle between components, Alt+click to switch a component between editing and dragging modes, or Ctrl+E to enter the editing mode
- de-prioritize the item. For items that are not important enough, or you are not sure are important enough, use Alt+P and reduce their priority. You can also use Ctrl+Shift+Down arrow for minor deprioritizations
- reschedule the item. If you know the item well or for some reason want to manually increase (or decrease) the length of the inter-repetition interval, press Ctrl+Shift+R to select the date of the next repetition
- dismiss the item. If you are sure you are not likely to need the item in the future, but you would like to keep it in your collection for reference or archival purposes, press Ctrl+D. Dismissed items are removed from the learning process
- delete the item. The key Del is very useful in cleaning your collection from garbage that results from your desire to know more than your memory can hold. In editing mode or in spelling items (i.e. at times when Del plays text editing functions), you may need to use Ctrl+Shift+Del instead. Please note that deleting an element in SuperMemo will delete all its children! You may therefore wish to learn to always use safer Done (Ctrl+Shift+Enter) instead
- delay or forget the item. If you think the item is too difficult at the moment, you can postpone learning it. For this purpose, choose Ctrl+J to set a new interval or use Forget to transfer the item to the pending queue. This will give you some time to import some supplementary material that will help you understand the item
Formulation
- Use minimum information principle which says that simple elements formulated for active recall bring much better learning results than complex elements. This holds true even though one complex element may be equivalent to a large number of simpler elements. See: Minimum information principle.
- Some information may be presented as a list. Lists should be avoided. However, some are inevitable (e.g. list of nerves, list of tributaries, list of EU admissions, etc.). If you need to memorize lists, use mnemonic techniques and try to mimic real life situations to combat memory interference. See also: Learning lists
- The way you ask the question in SuperMemo may differ from the way your life asks you the same question. In other words, you may store some material in SuperMemo, but a real-life situation will trick you into being unable to recall it. In other words, you need to properly formulate the material to maximize its recall in all potential contexts
- Remember about the universality of memorized rules. For example, it is better to learn a universal mathematical formula than just the examples of its use. Examples can be used to emphasize applicability in various contexts
- You can use Parse HTML (Ctrl+Shift+1) to convert selected HTML code into formatting (e.g. try inserting <hr> or <br> and parsing it with Parse HTML). You can also use this option to remove formatting (e.g. if you want to get rid of line breaks)
- You can edit your more elaborate texts using your favorite HTML editor. You need to associate that editor with the filename extension *.HTM. For example, if you associate Microsoft Expression Web (free) with *.HTM, you can edit your texts by just pressing Ctrl+F9. If you would rather leave your associations unchanged, you can use F9 to view the file in Internet Explorer, and choose File : Edit with Microsoft Expression Web (that menu item is added to Internet Explorer by Expression Web). For more see: Open HTML files in the default HTML editor
- Background color styles are used in incremental reading to preserve the original font used in documents. However, for this to work you must uncheck the following option in your Internet Explorer: Tools : Internet options : General : Accessibility : Formatting : Ignore colors specified on webpages
To learn more about efficient formulation read: Effective learning: 20 rules of formulating knowledge
Pictures
- Important pictures should be kept in image components (not inside HTML texts). Use Ctrl+V or Shift+Ins to paste a picture from the clipboard. You can paste the picture to a new element or to an image component. Do not paste pictures to HTML. Having pictures pasted into an image component makes it easy to resize, tile, fit, or move the image, as well as to change its attributes such as stretch, transparency, display time (e.g. at answer time only), etc. Pictures pasted or imported to image components are stored in the image registry and can be searched for by their name. They can be reused in many elements. They are automatically used to illustrate all extracts and clozes generated from the article that holds the picture. They cannot be easily lost when editing texts, etc. HTML components can keep remote pictures stored on the web but, naturally, you will lose them once the picture is removed from the remote server
- Use Download with Insert or Localize in Download images on the component menu (Ctrl+F8) to transfer remote pictures to your hard disk
- Use Rename (member) (Alt+R) to give pictures meaningful names for an easy search in the image registry
- To search for a picture, use:
- Search : Images (to open the image registry), and
- Ctrl+S to search the registry (same as Search : Find texts on the registry menu)
- If you want a picture to be part of the answer (i.e. not visible at question time), mark it with Answer on the image component menu
To learn more about using pictures, see: Visual learning
References
- Hover your mouse over the Reference link button () on the navigation bar to quickly see the reference in longer extracts.
- Note that all extracts generate elements that are children of the original article. If you have problems with recalling the original context of a fragment, you can always call it back by pressing the Parent button on the navigation bar. You can also use the Reference link button () to get to the source article, or, if you have already reached it, to get to the original article on the web.
- You can edit references in the reference area (which is pink by default). You can safely delete reference fields, but you need to decide if that change should be local (for that element only) or global (for all elements using this reference). You will not be able to delete #Article, #Parent or #Category fields because they are added automatically to references (not being a part of reference). You can freely change the text of references. Illegal changes are all changes that do not comply with the reference format, e.g. lines that do not start with reference field tags, or lines that start with unknown reference field tags (e.g. #Country). If you are unsure how this process works, import a single article from Wikipedia to a newly created collection, create some extracts and play with editing to see how references are processed
- If you choose an empty selection for the #Date reference, you will mark the text with the current date and time stamp
- To see the address under a link, hover over the link with the mouse and see the status bar. If you are in the editing mode, you will need to press Esc to get to the presentation mode for this to work or you can click the link and use Ctrl+K to view, create and/or change the hyperlink
- AND-Search in SuperMemo works on texts, not on elements. This means that reference texts do not take part in AND-Search for the main body of text. This may result in false misses. In SuperMemo, texts and individual reference fields are all treated as separate texts and are all searched independently
- Converting HTML to plain text does not affect the formatting of references (i.e. plain text entries can have their references formatted by a stylesheet)
- Formatting of references can be changed via stylesheets
- You can quickly modify (i.e. set, merge, and delete) the references across a number of elements. To do that, open them in the element browser, right-click your mouse and choose:
- Process browser> : Reference : Set reference to set the same reference to a subset of elements,
- Process browser> : Reference : Merge reference to add reference fields to a subset of elements,
- Process browser> : Reference : Delete reference to remove reference fields from all elements in the subset
Your own discoveries
In incremental learning, you will quickly discover why some of your own ideas about the learning process might not be optimum. Here are some things that you will discover on your own within the first 2-3 months of intense incremental learning:
- recognition is good for your exam, but recall is vital for your professional skills in the long-term
- manually organizing the timing of review is not what suits your memory best; it is actually quite the opposite to the idea of SuperMemo, which says that you review the material at moments that help stabilize memories
- manually organizing the order of review is not what suits your memory best (even though subset review is a very useful tool in SuperMemo when preparing for an exam)
- for beginners, traditional learning might be superior to SuperMemo in a very short-term (perhaps up to 1-2 months) because of the steep learning curve. You need to learn the toolset of incremental reading before you can reap the benefits (unless you employ simple Q&A learning when SuperMemo might be superior even within a week's perspective)
- you may reach 95% recall within 1-2 weeks on condition that you do not postpone your review. However, if you dump 1,000 pages of topics into the process at once, you will simply not manage to review all that material as scheduled by SuperMemo, and your retention might hover around 60-80% depending on how much time you invested in making repetitions
- once SuperMemo learns a bit about your memory and habits (1-3 weeks), you will oscillate around 95% recall as of the first repetition (if you do not delay, and if you stick to the rules of formulating knowledge)
- you will quickly discover that multiple cloze deletions on a single paragraph are not a good idea (e.g. compare the measured forgetting index with items that have the same cloze keywords separated, or just see how thus gained knowledge works in practice)
- you can look at learning parameters in SuperMemo to see how different approaches to learning affect your progress
Additional skills
Recognizing unsuitable texts
Best articles for incremental reading are fact-rich and context-rich. You need to develop your own rules for selecting quality reading material. Nothing can substitute for your own experience. You will learn to identify texts that are hard to process and yield lower reading efficiency.
Let's consider two extremes:
- Wikipedia: Wikipedia is great because it is crowd-sourced and many authors edit only a small section of a text in total abstraction of the rest of the article. This is why even a small portion of the text (as in incremental reading) will usually contain all relevant context
- Fiction: Fiction is best read linearly and you can just use a paper bookmark in a paper book to do as well as you would do with incremental reading
Many articles fall in between Wikipedia and fiction extremes. Where Wikipedia would say "the http protocol", a typical article might just say "the protocol" (if "the" is clear from preceding passages). Some text are peppered with "as I mentioned in the previous chapter", or "go to the next section", or "the three points explained in the previous chapter", etc. Abuse of working memory in text writing makes incremental reading difficult. This means that if authors use a lot of "referential ambiguity", the texts are not good for incremental reading. Example ambiguity keywords: "the", "they", "he", "it", etc.
Many articles are also filled with irrelevant chaff (supermemo.com isn't impervious to that weakness). Too much beating about the bush without clearly stating the conclusions that are most important to the reader. "Speculative philosophy" might be a good inspirational read, but probably not for incremental reading. You need to decide.
Some narratives should just best be read passively. They may be a compilation of facts that are generally obvious. In such cases you can just read and dismiss. Or you can read and schedule another review in a month or in a year (if you worry you miss something important). Or you can try to write, in your own words, a sentence or two on what new things you have learned from the narrative. Your sentence would shortly extract the quintessence from an otherwise lengthy passage. If it is meaningful and quintessential, you shall find little trouble with locating keywords suitable for clozing.
You need to develop your own rules for deciding which articles are good for reading. The chief rule might be: import anything that looks interesting, start reading, and if you recognize tell-tale problems, justdeprioritize or delete or fish for a few highlights and then delete.
Remember that you need to differentiate between unsuitable texts and difficult texts.
Handling incomprehensible articles
In incremental reading, you will often encounter material that is difficult to understand. You will need to develop analytical skills that will help you identify the reasons for the difficulties. If the culprit is the author, delete the article. If you need to digest other pieces of your collection first, delay the article. If you need more knowledge, delay the article and import more knowledge that will be needed to boost understanding. Do not forget that some texts make an inherently poor material for incremental reading (e.g. descriptions of scientific experiments, mathematical derivations, programming examples in source code, case studies, etc.). In such cases, use traditional methods of thorough analysis, summarize results of your analysis, and use SuperMemo to keep track of your own summaries. See: Recognizing unsuitable texts (incl. example).
This is how you can approach complexity in incremental reading:
- Start reading the article from the top. Once you find a difficult fragment, analyze it, and diagnose the reasons for your comprehension problems
- If the rest of the article does not depend much on the difficult fragment, extract it, and keep on reading
- If the rest of the article cannot be understood without understanding the difficult fragment choose one of the following:
- if you need more knowledge to understand the fragment: postpone the article (Learning : Reschedule or Ctrl+J)
- if the fragment is hopelessly intricate and leaves no hope for the future (e.g. because of wrong grammar, wording, formulation, logic, etc.), delete the article, and search for alternative material
- If you decide to postpone the article with Ctrl+J, decide what new knowledge you will need before getting back to the difficult fragment. List dictionary entries, encyclopedia articles, articles on the net that you will need to process before going any further. Schedule the search for materials as separate topics or try to search for new knowledge instantly
- Estimate the earliest time when you hope you will be able to understand the difficult article and use the appropriate interval with Ctrl+J. If the article includes high priority knowledge, it is always better to err on the safe side and provide a too early review
Randomizing repetitions
You can execute outstanding repetitions in a subset. If you would like to use a random sequence, follow these steps:
- open the subset
- choose Random : Randomize browser on the browser menu (Shift+Ctrl+F11)
- choose Learn on the browser menu (Ctrl+L)
Read toolbar
You can display the Read toolbar in the following ways (at middle or professional level):
- In the learnbar, click the Reading options button (), or
- Choose Window : Toolbars : Read from the main menu
- Click Read on the toolbar dock
Figure: The Read toolbar docked at the learnbar
Toolbar buttons
- Close toolbar - hides the Read subbar, and shows the main learnbar back. Note that the button is only visible when the toolbar is docked to the learnbar. It is not shown when the toolbar is docked to the toolbar dock nor when it is floating.
- Paste article (Ctrl+N) - paste a new article from the clipboard to the current collection
- Remember extract (Alt+X) - use the selected part of the text to create a new element and introduce this new element into the learning process. This is one of the most important options used in incremental reading. Use Alt+X on a selected text to tell SuperMemo that the selection is important and that you want to better remember it in the future
- Schedule extract (Shift+Alt+X) - use the selected text to create a new topic and schedule its review on a selected day with a selected priority. Schedule extract is the same as Remember extract but you can manually select the first interval, priority, and more
- Remember cloze (Alt+Z) - create a new cloze deletion element based on the current keyword selection and introduce that new element into the learning process
Example: You can convert the following sentence:
In 1947 the UN voted to divide Palestine into Arab and Jewish states
to question:
In 1947 the UN voted to divide Palestine into Arab and [...] states
by:
- selecting the word Jewish and
- choosing Cloze (or pressing Alt+Z).
In addition to Extract (above), this is the most important option of incremental reading.
- Schedule cloze - create a new cloze deletion and schedule it for repetition on a selected day
- Task extract - use the selected part of the text to create a new task and put this element on the current tasklist
- Split article - split the article into multiple topics using various chapter markers such as headlines, horizontal lines, Wikipedia sections, SuperMemo splitmarks, etc. This can substantially accelerate decomposition of very long articles and prioritization of article chapters
- E-mail (Shift+Ctrl+E) - send the element or the selected text via e-mail (you can annotate the element or comment on the selected text)
- E-mail FAQ - use the selected text as the basis of an FAQ question, and send the answer to the question's author. Your response will automatically be added to an FAQ file of your choice. It can also produce a Wiki version. All FAQs at SuperMemo Website have been created by means of E-mail FAQ. Many FAQs at SuperMemoPedia have been created using this option as well
- Highlight - highlight the currently selected text
- Change highlight style - change the highlight style (i.e. font, font style, font size, font color, and text highlight color)
- Ignore (Shift+Ctrl+I) - ignore the selected text in reading by marking it with the ignore style
- Delete before cursor (Alt+\) - delete texts before the cursor (e.g. after processing it)
- Delete after cursor (Alt+.) - delete texts after the cursor (e.g. footnotes, external links, literature references, etc.)(SuperMemo references located at the bottom of the text are not affected)
- Set read-point (Ctrl+F7) - mark the selected text as the point from which you will resume reading the next time you return to the presented article. In incremental reading, you rarely need to use Set read-point as all extract, cloze, highlight, and other operations will automatically set the read-point for you
- Go to read-point (Alt+F7) - go to the text that has been selected as the read-point
- Clear read-point (Shift+Ctrl+F7) - remove the read-point from the currently processed text
One memory, one action
In incremental reading, you achieve highest efficiency if your process knowledge in small steps separated in time. This way you can accomplish a good memory effect at little processing effort. However, many usersfall into traps of inefficiency where too little or too much work is done on a subject in a single review.
Futile review
Futile review is an example of insufficient work done (one action, zero memory). Futile review is born in this mental scenario: you see a topic and think: I am in no mood for this material now. Let's execute Next repetition. This is wrong! You must take action or you will loop into wasting time and learning little! It is a cardinal sin to execute processing operations without actually learning anything. When a topic arrives, you may have a dozen of excuses: I do not like this one. Let's do it tomorrow. Or I am too sleepy for this one. Or this one will take too much time. If you find yourself in a loop and constantly rescheduling the same topic, or spending time rescheduling a number of topics, you are hurting the efficiency of learning! This is the time that could be spent on more productive steps.
If you do not want incremental reading to become a waste of time, you must always take some action when you see a topic. For example:
- read a sentence and delete it, or mark as ignore, or extract it
- if the article is not vital for your further progress, set low priority (e.g. 99%)
- for the material that you won't have time for in a month or more, set the interval (e.g. to 333 days)
In other words, either make tiny inroads into the text, or mark it clearly as low priority or to-be-done later. Consider also Delete or Done!
Item perfectionism
Another facet of the same problem is taking too many actions on a single piece of information. It is highly inefficient to work on colors, fonts, pictures, priorities, etc. during a single repetition. All those actions can be spread over time. Naturally, setting the right priority is one of the most important steps. Perhaps a piece of information is not important enough to ever squeeze through your crowded learning. If so, you will save tons of time on not doing colors and styles.
Here also you should remember: one memory, one action. Each time you review a piece of information, you are allowed to do an edit, font change, template change, category change, etc. However, unless you can do all your actions in a single burst of machine gun keyboard strikes, or unless some actions are associated with learning new things, you should rather limit your actions to a single step per single repetition.
One memory, one action rule demands that every operation in incremental learning should leave a trace in your memory. It also says that one operation on a piece of data is better than two operations atthe same time
Example: incremental item structuring
The following item may look like a violation of the 20 rules:
Question: Inflammation is produced by eicosanoids and cytokines. Eicosanoids include (1) prostaglandins fever and vasodilation, and (2) [...] that attract certain white blood cells
Answer: leukotrienes
However, the 20 rules were written in 1999 for classical SuperMemo. Incremental learning is incremental across the spectrum of rules and principles. In particular, formulating items and building understanding are incremental too.
According to the one memory, one action principle, the presented item will assume its final shape some time in the undefined future (or never, if its priority is not high enough). It must be processed incrementally due to the following factors:
- incremental build up of comprehension, and
- incremental reformulation that requires time.
The 20 rules say "'Do not memorize until you understand", however, understanding is also an incremental process. Converting this item to plain "What eicosanoids attract white blood cells?" might make sense only if the student fully understands and remembers the hierarchy of inflammation factors, and involved eicosanoids. If this is notthe case, carrying the context in the shape of this complex item is a form of transitional stage between a topic and an item. The item still asks the question vital for active recall. However, it also makes sure that full context is provided until the rest of the knowledge structure is firmly established in student's mind. In incremental reading, the order of reading is often chaotic, the understanding is incremental, and the effort to build a solid knowledge structure is gradual too.
In addition to the incremental buildup of comprehension, extensive edits of items are costly (esp. a total rewrite of the item to a plain question). In fact, one of the main advantages of incremental reading is the minimum need for typing. This is why we use electronic sources in the first place (instead of just books that offer no disadvantage when entire items are typed in anyway). This is why an important efficiency principle in incremental learning is to minimize edits by complying with the one memory, one action principle.
Let us see how the presented item might evolve in successive repetitions. Note that all edit steps my proceed only with solidification of related knowledge (i.e. a single repetition may actually bring no edits at all). The execution of those steps will also be somewhat dependent on item priority. High priority items will receive more exposure, more processing and will demand better formulation quality.
Take 1: original complex item

Figure: A cloze deletion related to inflammation, with a formulation that seems to violate the 20 rules. This cloze will be improved incrementally over many repetitions along the principle: "one memory, one action"
Take 2: moving a clue to the answer field
Question: Inflammation is produced by eicosanoids and cytokines. Eicosanoids include (1) prostaglandins that produce fever and vasodilation, and (2) [...]
Answer: leukotrienes (that attract white blood cells)
Take 3: removing the prelude
Question: Inflammation: Eicosanoids include (1) prostaglandins that produce fever and vasodilation, and (2) [...]
Answer: leukotrienes (that attract white blood cells)
Take 4: bare bones item
Question: Inflammation: Eicosanoids include (1) prostaglandins, and (2) [...]
Answer: leukotrienes
Learning lists
Lists and sets are difficult to remember. It is hard to remember the whole set of countries that belong to the European Union. When learning lists, you should rather decompose the problem into smaller subproblems.
Let us consider an example in which you want to memorize the entire sequence of letters in the alphabet. It won't be very effective if you use the following item:
Question: What is the sequence of letters in the alphabet?
Answer: A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z
You will notice that you frequently stumble on parts of the sequence and need to stop repetitions just to exercise the entire sequence in the traditional way (like we all learn poems by rote).
However, you can approach this in a way that guarantees quick effects:
Question: What is the sequence of letters in the alphabet between A and E?
Answer: A, B, C, D, E
Question: What is the sequence of letters in the alphabet between D and H?
Answer: D, E, F, G, H
Question: What is the sequence of letters in the alphabet between G and K?
Answer: G, H, I, J, K
etc. etc.
After 2-3 weeks of repetitions, you may take on an extra task of recalling the whole sequence after each repetition of these simplified items. This will make sure you can recite the entire alphabet quickly. You will also frequently rehearse that parts of the sequence that are harder for your memory (e.g. V, W, X, Y, Z) as opposed to those that are much simpler (e.g. A, B, C, D, E).
Practical problems with memorizing lists
You may develop a good methodology for memorizing lists in SuperMemo. However, you may later discover that the memorized lists are not very useful in real life, or worse, your memory may fail you when you undergo a baptism of fire. You already know that list should not form an answer to a question. In a list A, B, C, SuperMemo needs to separately understand your difficulties with linking A and B, B and C, etc. You can use cloze deletion to learn lists using multiple items. For example:
Parent template topic/extract:
A B C
Items generated with cloze deletion:
Item 1:
Question: [...] B C
Answer: A
Item 2:
Question: A [...] C
Answer: B
Item 3:
Question: A B [...]
Answer: C
It is important to know that Item 1 above may make you fail to answer with A to the question C if you only learn to answer Item 1 by understanding the association of B with A. In such cases, you will need even more work by formulating items: A-B (where A is the question and B is the answer), A-C, B-A, B-C, C-A, and C-B. Although you will get six items instead of one, you knowledge is likely to be more solid and you may actually spend less time on repetitions of those multiple items than on repetitions of the conglomerate A-B-C item
Lists can often be ignored
In a majority of cases, we do not need to learn lists at all. The perception that a list is worth memorizing is often a reflection of a bad habit we bring from school where lists are a frequent feature at exams.
A user of SuperMemo asked: "Could you please help me with extracting items from the following text? I am really not sure where to mark the boundaries of extracts and how to use cloze deletion?":
Changing Rates of Mental Illness
Mental illness is becoming an increasing problem for two reasons. First, increases in life expectancy have brought increased numbers of certain chronic mental illnesses. For example, because more people are living into old age, more people are suffering from dementia. Second, a number of studies provide evidence that rates of depression are rising throughout the world
This fragment is difficult to process because it is an enumeration (a list) that forms one large logical structure. However, for understanding the subject, you do not really need to remember how many factors affect mental illness. You primarily need to remember the relationship between the cause and the effect. If you ignore the enumeration, you can simply produce the following topics that will each be easy to process further:
- Mental illness is becoming an increasing problem
- Increases in life expectancy have brought increased numbers of certain chronic mental illnesses
- Because more people are living into old age, more people are suffering from dementia
- Rates of depression are rising throughout the world
If you believe that you cannot live without the enumeration, you can first extract the facts listed above, and then simplify the enumeration by deleting all superfluous information:
Mental illness is increasing for 2 reasons:
- increases in life expectancy have brought increased chronic illnesses.
- rates of depression are rising
Using Decompose
Little known but very useful function in SuperMemo can help you tackle lists.
If you are learning the names of fruits, you might see a text like this:
Examples of fruits are apples, oranges, pears, cherries, banana...
You do not want to memorize the whole list of fruits, esp. that the longer it gets the more likely you are to fail. There is no definite or complete list of fruits that would make a good memorization target. All you really want to know is that an apple is a fruit, or an orange is a fruit, etc. The list itself is rather useless. You can keep it as a reference in SuperMemo, but memorizing it would be a waste of time.
You can use Decompose to quickly achieve your learning goals in reference to fruits. Start from modifying the topic:
Apples, oranges, pears, cherries, banana ... are fruits.
Generate a template cloze:
Question: Apples, oranges, pears, cherries, banana are [fruits/vegetables]
Answer: fruits
Convert that cloze to a version that can easily be decomposed by placing list members into braces using slashes as separators:
Question: {apples/oranges/pears/cherries/banana} are [fruits/vegetables]
Answer: fruits
You can now treat the question field with Reading : Decompose on the component menu to get a series of clozes like these:
Question: apples are [fruits/vegetables]
Answer: fruits
Question: oranges are [fruits/vegetables]
Answer: fruits
Question: pears are [fruits/vegetables]
Answer: fruits
etc.

Thorough preview of articles
It is hard to formulate a simple algorithm for deciding when to preview the whole article before reading, and/or when to extract the most important fragments during a preview. After all, the article can also be read incrementally in a linear sequence. This is a case a multi-criterial optimization where many factors must be taken into account and the ultimate decision will depend on your own preferences.
Here are some criteria:
- if you need this knowledge today, you should start with a quick preview and extracting mission-critical fragments
- if this knowledge is very important and your learning process overflows with articles to read, extract-preview will increase your exposure to the article
- if the article is not very interesting, line-at-a-time reading will be equivalent to assigning a lower priority (you will just read a sentence once per week or once per month and you may never finish the article unless it gets more relevant or interesting)
- if you believe the article contains very important pieces in its body, you may want to quickly locate these and extract them for separate (more detailed) reading
- if your reviews occur in very long intervals as a result of slow reading, you may opt for shortening the interval or running a preview of the most important sections instead
- if you are reading texts from your e-mail tasklist, preview is highly recommended: not all people start their messages with the most important points and you certainly would not want to delay locating paragraphs requiring immediate action with weeks of delay
- if you import from Wikipedia, high priority articles can be split automatically (with Split in the Commander), and you can assign priorities to individual subsections
In summary, these are the most important incentives for the whole-article preview:
- high priority of the material
- indication of higher-priority fragments buried in a lower-priority text
- high interest
Unified store of knowledge
SuperMemo should conglomerate all your knowledge and your learning material. Ideally, you should just keep a single body of knowledge in a single collection. That main collection should be enriched daily by newimports of articles and multimedia from various sources. Keeping your knowledge in a single collection is vital for subset review, searching for knowledge and references, searching for pictures, statistics, progress monitoring, import defaults, etc. SuperMemo provides a rich set of tools for handling disparate areas of knowledge in a single continuous learning process. However, in certain situations, you may create separate collections for various purposes. There are two main reasons for keeping collections separate:
- collections that are not part of your lifelong learning, and
- collections that need special treatment due to various technical limitations imposed by SuperMemo or current technology.
Here are some examples of situations that justify creating collections separate from your main body of knowledge:
- project collections (problem solving, tasklists, creative elaboration): those collections serve a specific project, not your general learning. After the project is complete, they may either be archived or integrated with the main body of knowledge (depending on their nature).
- incremental writing projects, blogs, etc.
- incremental problem solving collection dedicated to a specific problem where you want to focus entirely on a single issue
- picture collections (public: family albums; private: family picture collections, etc.): if your picture database goes into hundreds of thousands of pictures, you will definitely want to keep it separate for easy backup and dedicated processing, which will often be of different nature than learning
- YouTube video collections: learning with YouTube is quite different from incremental reading, you cannot play your favorite music while learning with videos, you may give up learning when you have no access to the Internet, etc.
- video file collections (e.g. home video): those collections will usually call for different processing. In addition, they quickly grow into terabytes in size, which discourages frequent backups
- diaries and journals
- logs
- jukebox: incremental learning process can add an extra level of fun to experiencing music. Only after playing with a jukebox.kno for a few weeks you will truly understand how important priorities and intervals are in the perception of music!
- mail: you may want to separate business from family&friends and from the mail related to the current project
- tasklists and charts
- paper notes
- kid's collection: if your kids are too young to do SuperMemo on their own
- notes: on occasion you may prefer to keep your notes in SuperMemo rather than a word processor (e.g. easier startup, collection switching, better search, etc.)
- audio archive, and more
Flow of knowledge
The figure below roughly illustrates the flow of knowledge in time depending on knowledge difficulty:
Figure: The horizontal axis corresponds with the repetition number and the vertical axis represents intervals (logarithmic scale). Despite a popular belief, the semi-log scale does not produce a linear graph here. Clearly the increase in the length of intervals slows down with successive repetitions. Moreover, the graph corresponding with zero lapses (red curve), results from the superposition of items with lower and faster increase in intervals (determined by difficulty). The bell-shaped curve is determined by all contributing items (below repetition number 10) and then only by difficult items or items with low forgetting index for which the increase in the length of intervals is significantly slower (above repetition 10). To see the above graph in your own collection, use Tools : Repetitions graph on the browser menu
Incremental reading of PDF articles
PDF is a proprietary format. SuperMemo does not support PDF natively. This has always made PDF materials harder to process than ordinary HTML text imported from the web.
There are 4 approaches that are most often used to process PDF incrementally. You will need to see which one is best for your particular material. It may happen that you will need to resort to mixed strategies and use different approaches to different texts. The 4 options are:
- Converters: using PDF to HTML converters to generate HTML text that can be read in SuperMemo
- Pictures: using page snapshots (e.g. with Print Screen) and employing visual learning
- Manual: using copy and paste to copy PDF to SuperMemo page by page (or picture by picture)
- Incremental: using an incremental approach to read-copy-and-paste while working with PDF in Adobe Reader called from SuperMemo
Conversion to HTML is most convenient and least expensive. However, some converters and/or some PDFs produce HTML that is quite different than the original, and/or difficult to process in SuperMemo (e.g. requiring extra filtering, or extra manual formatting). Page snapshots are a fast way to read and import pages that are difficult to convert or are read only (e.g. manuals that require a specific page layout). Copy and paste approach is best for articles that can easily be selected in their entirety and which do not contain too many pictures. Finally, the incremental approach is most natural for SuperMemo, however, instead of using read-points, the student needs to make a note where he or she stopped reading the text.
For more solutions, see: PDF at SuperMemopedia.
PDF to HTML converters
As SuperMemo cannot host PDF files natively for incremental reading, the most promising long-term solution is the use of PDF to HTML converters. However, all converters have their limitations. The languages defined by HTML and PDF are not equivalent. Not all expressions of PDF can be expressed in HTML. This is why you need to check a few converters and see which one is best at processing your type of learning material.
Conversion
Here is a short list of converters as compiled at SuperMemoPedia:
If you are not sure which one to choose, you might use this one: PDF online (it keeps a limit of 2 MB on the size of files to convert).
Processing
Once texts are imported to SuperMemo, they may need further processing:
- filter problematic code with F6 (e.g. bulletizing tables)
- import pictures (some pictures are text-like constructs that need to be snapped with copy&paste)
- split into manageable portions (e.g. with the help of Split: Split the article in the Commander)
- convert portions of text to plain text with Ctrl+Shift+F12 (in cases of most unfriendly formatting)
Using MS Word
Some students use MS Word as an intermediary stage in conversion to HTML. However, as much as the conversion of PDF to HTML is never complete and accurate, there are differences between PDF and MS Word that make lifedifficult. At the moment of writing, there aren't any tools that would reliably convert PDF to MS Word format. Pasting from Adobe Reader to MS Word yields poor results (e.g. texts in columns lose or mix portions of texts). If you own MS Word, you can give it a try, however, using converters or other methods will probably work better.
Using OCR
Some users swear by OCR. See: Using OCR to convert PDF for SuperMemo.
PDF with visual learning
You can convert PDF to pictures and employ the tools of visual learning.
Here are the steps:
- convert PDF to pictures either by saving as JPEG, or by using page snapshots with Print Screen
- paste pictures to SuperMemo or import pictures from a local drive
- as pictures are not searchable, it is important to copy&paste a part of article (if possible) that could later be used in search and review. For example, abstracts of scholarly articles with necessary reference tags (#Title, #Author, #Source, etc.)
- use visual learning to process the imported materials. Pictures will need to be trimmed (e.g. (1) Alt+click, (2) marquee selection of the interesting part, (3) press Esc, and (4) choose Permanently cut/crop the zoomed/trimmed image file). Use visual extracts (Alt+X) to focus on smaller portions of imported articles
- annotate the pictures or write down summaries to further process most important portions with incremental reading. Without the use of cloze deletion, imported material may quickly be forgotten.
This method of reading PDF is analogous to incremental reading of paper materials.
See more at SuperMemoPedia: PDF and Visual Learning.
PDF copy and paste
If convertion of PDF to HTML is not satisfactory, you may need to resort to old plain copy&paste. Some PDF texts paste whole chapters pretty well with little extra text/code (e.g. page headings). Some PDFs respond well to Ctrl+A (for selecting all text) and Copy with Formatting (right click). Usually, Adobe Reader will not let you do multi-page selections that would paste to SuperMemo fast and nicely. You may even get annoyed with your attempts to copy a multi-column portion of a single page. You will get one column selected, middle of the second, and the ending of the third. Other double-column texts will paste as a mix of both columns per line. Sometimes pasting multi-column texts is not possible. This means that you will often need to go from page to page, or even column to column, and repeat copy&paste. That can take ages. Similarly, pictures do not copy as part of HTML. So you need to copy&paste pictures separately. Here again, when Adobe Reader will not let you copy pictures easily, you can just use Print Screen, paste to SuperMemo and trim&crop in SuperMemo (see: Visual learning). Tables are usually best processed in the form of pictures as they usually import poorly to HTML. Some PDF documents do not even allow of selecting texts. In those cases you will need to resort to PDF visual learning too. Sometimes you may just give up and read the article straight without bothering to do it incrementally, or look for alternative texts, or just give up reading altogether. You can also read the article using traditional methods, and copy to SuperMemo only the portions that you would normally extract within SuperMemo.
After pasting text from Adobe Reader to SuperMemo, it will often be jagged, disrupted, wrongly formatted, etc. Converting short passages to plain text often dramatically improves readability. The shortcut is Ctrl+Shift+F12.
For more, see: PDF Copy and Paste
Incremental PDF
If you want to work incrementally with PDF articles, you can use the following strategy:
- Save your PDF files to a dedicated folder
- Import them regularly with File : Import : Files and folders
- Define a PDF template with a large HTML component and a tiny binary component for holding PDF (use that template as the default for the import category, or apply it after import to all PDF articles)
- When reading is scheduled for the PDF element, click the binary component and jump to the page where you last finished reading (to automatically go back to the last view pages, in Adobe Reader, check Edit : Preferences : Documents : Restore last view settings when reopening documents)
- Paste all important fragments of the PDF document to the HTML component (if texts cannot be selected, use the Print Screen option, paste the picture, and use visual learning tools to extracts individual fragments)
- Paste figures to SuperMemo by clicking a selected picture, right-clicking, and choosing Copy Image in Adobe Reader or Print Screen. Use visual learning tools to process larger pictures (trimming, zooming, extracting, etc.)
- Process the pasted texts in parallel with reading the PDF document (esp. if they are very important). Alternative, start incremental reading in HTML only when you finish reading the document in PDF
Incremental reading of paper articles
If you have many notes taken from paper journals, or you must read paper articles, you can use a few methods to employ incremental reading in that process. Working with paper will never be as effective as working with electronic material. However, you can still triple your performance with the benefits of incremental learning.
Here is an exemplary algorithm for processing paper notes:
- before getting down to processing, search the net! Many noteworthy articles have already been published online. That saves lots of time
- if the text is of general nature, you might find a better equivalent (e.g. at Wikipedia)
- create a dedicated PaperNotes.kno collection for easy backup. It might grow to a huge size! You can use a dedicated processing time slot for your paper notes
- very short notes or very important notes, you can type by hand. The advantage of typing is that it can shorten the texts, give them more meaning, and have them instantly searchable in the collection
- the rest of texts you can import as pictures or process with OCR (e.g. use a pen scanner to pick the most valuable pieces from the book)
- use a digital camera to quickly snap paper pages. A scanner yields better quality but is too slow
- copy the pics to the hard disk
- use File : Import : Files and Folders to import all pictures at once
- use visual learning and the tools of incremental learning to prioritize and process the imported material (the extract option is particularly useful)
A user of SuperMemo wrote a few words about his experience with OCR in Studying Law with SuperMemo.
See also:
Philosophy of incremental reading
Advantages of incremental learning
In incremental learning, you learn fast, you acquire massive loads of knowledge, retain memories for life, remember almost all that you have learned, understand things better, develop harmoniously in all directions, enhance your creativity, and all that while having incredible fun! If that sounds too good to be true, please read more below or just give it a solid try.
Massive learning
Incremental learning offers a possibility of studying a huge number of subjects in parallel. In traditional reading, very often, one book or academic subject must be completed before studying another. With incremental learning, there is virtually no limit on how many subjects you can study at the same time. The volume of processed knowledge can be staggering. Only the availability of time and your memory capacity will keep massive learning in check.
Lifetime memories
As incremental learning is based on spaced repetition, all memories that you form while learning will be indefinitely protected from forgetting. See: General principles of SuperMemo. Only SuperMemo makes it possible to implement incremental reading. Incremental reading requires continual retention of knowledge. Depending on the volume of knowledge flow in the program, the interval between reading individual portions of the same article may extend from days to months and even years. SuperMemo (repetition spacing) provides the foundation of incremental reading, which is based on stable memory traces that would not fade between the bursts of reading
High retention
In incremental learning, the review of the learning material is governed by a spaced repetition algorithm known as the SuperMemo method. The algorithm ensures 95% knowledge retention by default. That fraction can be increased at the cost of higher cost in time (i.e. more frequent review). Retention can also be reduced to increase the overall speed of learning. In heavily overloaded collections, 95% retention figure refers only to top-priority material. To save time, low priority material may be reviewed less frequently, resulting in lesser retention.
Comprehension
One of the limiting factors in acquiring new knowledge is the barrier of understanding. Building knowledge in your brain is like assembling a jigsaw puzzle. Some pieces cannot be placed in the puzzle before the others. Some pieces capitalize on others. There is no point in memorizing facts about Higgs boson before you learn what the standard model is and that, in turn, should follow the general understanding of particle physics which itself requires some ABC of physics. In incremental reading, if you encounter texts related to Higgs boson you can manually delay it until the time you hope your Physics ABC will provide the ground for understanding the boson. In traditional reading, you would just waste your time on reviewing Higgs boson material just because you would not have tools to effectively reschedule and reprioritize your reading in the middle of a longer article. Traditionally, your decision to skip the material would provide no definite way of coming back to the skipped material in the future. With incremental reading, you waste no time on reading material you do not understand. You can safely skip portions of material and return to them in the future. You become the master of the conscious knowledge building process. You can gradually build understanding of complex phenomena.
All written materials, depending on the reader's knowledge, pose a degree of difficulty in accurately interpreting their meaning. This is particularly visible in highly specialist scientific papers that use a sophisticated symbol-rich language. A symbol-rich language is a language that gains conciseness by the use of highly specialist vocabulary and notational conventions. For an average reader, symbol-rich language may exponentially raise the bar of lexical competence (i.e. knowledge of vocabulary required to gain understanding). Incremental reading makes it possible to delay the processing of those articles, paragraphs or sentences that require prior knowledge of concepts that are not known at the moment of reading. The processing of the learning material will only take place then when the new information begins to slot in comfortably in the fabric of the reader's knowledge. You can then gradually proceed through this material and gradually build the understanding from basic or simple facts towards details or more complex components of knowledge. You will build understanding, resolve contradictions and ultimately creatively discover new truths about the learned material. Over time, you will optimize the structure of knowledge in your mind in terms of coherence, integrity, and representation. Incremental reading will make it possible to tackle the hardest material that might otherwise seem unreadable.
Uniform progress
Instead of focusing on a single subject of study, the student will review dozens of subject areas in a single day. Instead of monopolizing his or her knowledge with a single area of expertise, he or she will harmoniously deepen all facets of his knowledge in proportion to needs and/or interests. The growth of the knowledge tree will also be guided by the present level of understanding of individual subjects, in proportion to the growth of the supporting knowledge and specialist terminology. Instead of growing a few thick branches, the knowledge tree will grow twigs in all possible directions while still adding bulk to the trunk and main boughs. Incremental learning is inherently incapable of producing medical experts who have never heard of the Kuiper Belt, or astronomers who have no idea what constitutes a basic healthy diet. SuperMemo helps you prioritize the acquisition of knowledge in various fields. It also helps you fine-tune the balance between specialization and general knowledge. See also how SuperMemo prevents tunnel vision
Creativity boost
The key to creativity is an association of remote ideas. By studying multiple subjects in unpredictable order, you will increase your power to associate ideas. This will immensely improve your creativity. Incremental reading may be compared to brainstorming with yourself. SuperMemo will throw at you various articles, paragraphs, statements and questions in a most unexpected order. In the long run, the greatest creative advantage comes from knowledge permanently stored in your memory (as opposed to knowledge that requires Google). It is only a matter of creative effort and invested time before different pieces of knowledge can be associated to form new quality. This will also provide your brain with an entertaining form of mental training that will be highly appreciated in all forms of professions based on intellectual performance.
With incremental mail processing, it is also possible to mesh your learning, creative writing, and creative problem solving with a creative mail exchange with other people. This may appear helpful in collective problem solving or in complex projects when you need to strike a balance between focused individual work and pulling the team brains together. This process is called incremental brainstorming. Incremental brainstorming is slower, but it does not need synchronization (circadian rhythm, time zones, motivation, etc.), and you do not need to interrupt each other's work. Incremental brainstorming will never replace face-to-face interactive collaboration, however, it has many advantages associated with incremental learning (creativity, prioritization, attention, meticulousness, long-term viability, etc.). It may provide an excellent knowledge-based supplement, or be your best creative collaboration tool when working at a distance (esp. via different time zones). The creative process is unpredictable, and when you hit your best ideas when the rest of the team is asleep, it makes a good sense to strike the iron while hot: employ creative elaboration and send your idea out.
For more on the employment of incremental learning in the creative process see:
Consistency (resolving chaos and contradiction)
Contradiction and chaos in your learning material comes from bad sources, from errors, from disagreements in science, or from the fact that you start the process from importing a set of unrelated or even chaotic articles describing a studied complex problem.
If your learning material contains contradictory information, your brain will quickly alert you to this fact. In classical learning, you would often relearn new facts that would contradict earlier learned facts. Then you would relearn the older version again and this wasteful cycle might repeat more than once. In SuperMemo, the same process can take place; however, there will be two mechanisms that will turn chaos and contradiction into a self-limiting condition. The first mechanism relies on high retention of knowledge in SuperMemo that will often make you instantaneously spot the contradiction: Wait a minute! I have already learned this fact and the answer was different! Unfortunately, even SuperMemo isn't hermetic to contradiction (your retention actually never reaches 100%). The second mechanism is the convergence of contradictory material in time. If you, for example, learn two different answers to What is the size of human population?, say, 5.5 billion and 6 billion, you will naturally provide a wrong answer to one of these questions. Once you relearn it the new way, you will provide a wrong answer to the other question. Inter-repetition intervals for these two contradictory items will get shorter with each relearning cycle. The repetitions of contradictory items converge in time. Sooner or later, the red alert will be raised by your brain. You will quickly resolve the difference and delete one of the items. Similar process will affect hazy or incompletely specified information. Your knowledge will grow in consistency with time.
In scientific research, acquiring engineering knowledge, studying a narrow topic of interest, etc. we are constantly faced with a chaos of disparate and often contradictory statements. By introducing the chaos of new research into SuperMemo, you will gradually locate contradictions and strive at building better and more consistent models in your memory. Incremental reading stochastically juxtaposes pieces of information coming from various sources and uses the associative qualities of human memory to emphasize and then resolve contradiction. You will quickly lean towards theories that are better supported by research findings. Those supported poorly will be less firm and will often cause recall problems. Naturally, it may happen that you wish to learn contradictory statements too. For example, the opinions of dissenting scientists. In those cases, SuperMemo will help you emphasize the need of rich context. You will label individual statements with their proponent names or with the school of thought labels.
Stresslessness
Observers and new users of SuperMemo believe that complexity of incremental reading must make it stressful. Some report that even reading about incremental learning is stressful. However, even though complexity always leads to a degree of stress or confusion, in the long-term, the opposite is true: SuperMemo helps you combat stress. Stressless learning is one of the greatest advantages of incremental learning. All the advantages listed in this section contribute to the sense of fun and relaxation. However, SuperMemo's ability to combat information overload might be the chief factor. Conversely, low stress levels have a miraculous impact on the effectiveness of learning.
Not everyone is stressed with information overload. There is a precondition for experiencing stress of having too much to read or too much to learn: obsessive hunger for knowledge, fear of not being able to keep up, pressing need for new knowledge, etc. This precondition is met in a great proportion of the general population according to a number of studies, and is actually less likely in younger individuals, including students, who are shielded from stress by their less crystallized motivation for learning.
The term Information Fatigue Syndrome has been coined recently to refer to stress coming from problems with managing overwhelming information. Some consequences of IFS listed by Dr. David Lewis, a British psychologist, include: anxiety, tension, procrastination, time-wasting, loss of job satisfaction, self-doubt, psychosomatic stress, breakdown of relationships, reduced analytical capacity, etc. The information era tends to overwhelm us with the amount of information we feel compelled to process. Incremental reading does not require all-or-nothing choices on articles to read. All-or-nothing choices are stressful! Can I afford to skip this article? For months I haven't had time to read this article! etc. SuperMemo helps you prioritize and skip articles partially (by decision) or opaquely (i.e. behind the scenes). Oftentimes, reading 3% of an article may provide 50% of its reading value. Reading of articles may be delayed opaquely, i.e. not by stressful procrastination but by a sheer competition with other pieces of information on the basis of their priority. In incremental reading, instead of hesitating or procrastinating, you simply prioritize.
If you happen to open a dozen of tabs in your web browser, you will often be stressed about the optimum course of action. You might be late for sleep, or late for work, and yet you do not want to lose the information. In SuperMemo, you just import&prioritize. Or just import. Nothing is lost. You will encounter the imported material as soon as your learning time allocations permit. Similarly, you can clear your 1,000 pieces mail Inbox in a few hours with all pieces of mail well prioritized and scheduled for review.
Once you know you can rely on SuperMemo in presenting review material for you, you can eliminate the stress and anxiety related to having too much to study or too much to read. You will never manage to read or learn all that you would hope for, but you will at least not lose sleep over planning and scheduling. SuperMemo is a promise of the best use of your potential. With this conviction, you can devote all your energy to comprehension, analysis and retention of the learned material.
SuperMemo helps you take away a big deal of information overload stress. In a typical IFS stress therapy, you will see that scrupulous notes, ordering one's desk, planning one's work, keeping a calendar of appointments, etc. all have a strong therapeutic value. SuperMemo does exactly the same: it helps you keep a scrupulous and well-prioritized record of what you want to read and takes away stressful chaos from the process of acquiring information and learning the collected material. SuperMemo eliminates disorder and the ensuing uncertainty that often characterizes wild searches for information on the net.
Attention
Human brain has an in-built limit on the attention span. We all get bored with things. This is particularly visible in kids. Limited attention helps maximize the learning input. This is why most toys have a short lifespan, and other kids' toys seem always more interesting. The same is true of reading. Even the best articles can become taxing if they get too long. Millions of people do a daily channel zapping on TV. This absurd activity is driven precisely by the craving for dense action and information variety. A gripping movie goes "too slow" for a typical channel zapper. This is why he or she prefers to watch three movies at the same time (even though the coherence of the plot of each will suffer). Incremental learning is a perfect remedy to the limited attention span. Even a single unlucky paragraph in an article may greatly reduce your enthusiasm for reading. If you stumble against a few frustrating paragraphs, you may gradually develop a dislike of reading a particular article. You may even become fed up with reading for the entire evening.
In incremental reading, once you sense any sign of boredom or distraction, you can jump to the next article with mostly positive side effects (expressed mainly in better memories produced by spaced learning). Unlike in channel zapping, you won't miss any information. Just the opposite, you will maximize attention per paragraph. Your attention to the same piece of information may depend on your mood, amount of prior reading, today's interest that may depend on the piece of news you heard on the morning radio, etc. With incremental reading, you can fit your best attention to each individual piece of reading. You can change the approach depending on your circadian status (i.e. the time of the day, mental energy, etc.). You can deprioritize articles that undermine attention. You can split intimidating articles into more manageable portions. The boost in attention is one of the main reasons why incremental reading is more fun than ordinary reading.
Consolidation
Everything we learn must be reviewed from time to time in order to be remembered. If you read an article in intervals, you already begin the consolidation of memory which may save you lots of time. In traditional reading, you would need to read the whole article, and then to review the article later several times. With earlier releases of SuperMemo, you would need to read the whole article, and then only review the most important parts of the article in SuperMemo at intervals determined by the program. Now you can begin the consolidation-review cycle already during reading! Incremental reading combines the process of extracting pieces of valuable knowledge with memory consolidation. This pre-consolidation will often dramatically reduce the number of repetitions required before your material gets to be reviewed in long intervals of months and years. By the time you convert parts of the material into clozes or question-answer items, you will already have it well-consolidated. This consolidation will be based on solid context, a degree of redundancy (that helps retention), and an easy-to-remember formulation based on cloze deletion. Extracting pieces of information from a larger body of knowledge provides your items with all the relevant context. This slow process of jelling out knowledge produces an enhanced sense of meaning and applicability of individual pieces of information. Semantically equivalent pieces of information may be consolidated in varying contexts adding additional angles to their associative power. In other words, not only will you remember better. You will also be able to view the same information from different perspectives.
Prioritization
You always have a long queue of articles to read, and there are always more articles to read than you can ever hope to remember. In incremental reading, you can precisely determine the priority of each article, paragraph, sentence or question. Evaluating articles and prioritizing them is difficult because you cannot do a good evaluation without actually reading a part of the article in question. In incremental reading, you can read the introduction and then decide when to read the rest. If an article is extremely valuable or interesting, you can process it entirely at once. Other articles can slowly scramble through the learning process. Yet others may ultimately be deleted. The prioritization will continue while you are reading the article. If the evaluation of quality or content changes while reading, so will the reading-review schedule.
Prioritization tools will ensure that important pieces of information will receive better processing. This will maximize the value of your reading time. This will also reduce the impact of material overflow on retention. You will always remember the desired proportion of your top-priority material. While the lesser priority material may suffer more from the overflow and be remembered less accurately. Priority of articles is not set in stone. You can modify it manually while reading in proportion to the value you extract from a given article. The priority will also change automatically each time you generate article extracts. It will change if you delay or advance scheduled reading. The priority of extracts is determined by the priority of articles. The priority of questions and answers produced from individual sentences is determined by their parenting extracts. Multiple prioritization tools will help you effectively deal with massive changes in your learning focus. With the prioritization tools you can always determine your learning focus in numbers!
This is one of the most important things about incremental reading: efficient fishing for pieces of golden knowledge!
Speed (of reading)
Incremental readers can beat speed readers in the speed of reading! This is true even for relative beginners with little or no speed-reading training. The caveat: all that is possible at the cost of delayed comprehension. In speed-reading, you always need to worry about the comprehension level. High comprehension is where speed-reading skills are vital. However, in incremental reading, you can quickly skim through less important portions of the text without worrying you will miss a detail. The skimmed fragment will be scheduled for later review. You can optionally determine when the review will happen and at what priority (low priority review may be delayed further, often automatically). You can quickly jump from paragraph to paragraph, get the overall picture, mark fragments for later reading, mark fragments for detailed study, etc. This speed-reading method, with a bit of training, is stress free. You will eliminate the greatest bottleneck of speed-reading: fear of missing important pieces of information. When you come back to the skimmed fragments in the future, they may have already become irrelevant or less important. That is one of a savings in time generated by incremental reading. You always focus on top priority material and you spend little time worrying about things that are left for later reading. Incremental reading is speed-reading without the loss of comprehension. Once you speed-read the entire article, you can slowly digest it again from the very beginning in the incremental reading process. Needless to say, speed-reading is not a patch on incremental reading when it comes to long-term retention. Memories are always subject to forgetting. Whatever valuable information you gather while reading may be forgotten at any time. Pieces that would be retained without SuperMemo (e.g. through regular use), produce minimum workload. Other pieces will allow you to never need to come back to the article in question again. In conclusion, all knowledge that you need in the long-run, should be best acquired via incremental reading. Traditional reading can still be used for entertainment, temporary knowledge (e.g. how to install a sound board), curiosity (e.g. news), etc. This is not to say that speed-reading skills are not useful in incremental reading. If you are already a solid speed-reader, you can add to your speed and comprehension with the help of incremental reading. In the process, you will hone your skills further and become even a faster reader.
Speed (of formulating items)
Cloze deletion is the fastest tool for converting texts into items. In addition to massive imports, you can introduce your own rough notes into SuperMemo and later gradually convert them into well-structured knowledge. Less important material may remain unstructured and, as such, less well-remembered. You will see how passive notes gradually fade in your memory and how their individual components will need to be reinforced by formulating specific well-structured items. You will make such reinforcement decisions on the one-by-one basis depending on the importance of the fading material and the degree of recall problems. Naturally, due to a typical learning overflow, you will always neglect some portions of the material. This is how you will gain additional speed understood as the time invested per item. You will generate items faster, re-formulate them with greater ease, and save additional time by neglecting less important material. This is prioritization via formulation. Less important material will remain in a less processed and messier state characterized by lower retention.
Meticulousness
With well-prioritized stream of information, you are served knowledge in smaller chunks. This makes it possible to truly focus on most important pieces and discover things that would never get noticed in the mass of voluminous learning. Good attention brings meticulousness and creative discovery. In other words, this is a marriage of prioritization, attention, and creativity advantages with a new twist: noticing things that are hard to notice in massive learning.
Training
With massive incremental reading, you will hone a set of skills that are vital for efficient learning. By repeating the same procedures over and over again, day in and day out, over the months and years, you will become a master of processing and retaining knowledge! If you want things well done, do them often. Here are some example of skills that will get a boost and change your learning:
- Recognizing suitable texts at a glance of an eye. Some texts are great for efficient reading, some are full of chaff and waffle. The more articles you need to preview fast and prioritize, the faster you can do it and more accurate you become. This is an exercise in expert pattern recognition.
- Formulating knowledge efficiently. In terms of learning efficiency, the difference between well-formulated and ill-formulated items may be as high as 1:10 or even 1:100. Some items are mnemonic. Others are confusing. Some require 5-6 repetitions in a lifetime. Others permanently reside among leeches that come back for review and waste your precious time.
- Mnemonic skills. The more you try to remember, the better you know how to remember things fast and for long. Mnemonic skills can be developed in dedicated courses. They can also improve with each single item you formulate and memorize.
- Speed-reading skills. Fast reading is a hallmark of incremental learning. Traditional speed-reading is very different from speed-reading with SuperMemo. You nearly never need to worry about missing information. Incremental reading carries none of the burdens of a typical hit-and-miss speed-reading. There is no limit on the speed of skimming. Mastery of keyboard is as important as the eye saccades. The more you skim, the better you skim. The more you hurry, the more you skim. Incremental learning accelerates your hunger for knowledge, and the speed at which you devour it.
- Semantic skills. The language is a jigsaw puzzle of words and phrases played on a set board of grammar. Understanding the language is vital for speed-reading where the structure of a sentence needs to be parsed in a fraction of a millisecond at a single glance. In incremental reading, correct formulation of clozes will often require minor rewording. Like in a puzzle, you will need to shift a word from here to there, remove sections of sentences, insert context, change the tense, remove referential ambiguity, etc. Mastery of the grammatical sentence skeleton and the semantics will increase with every and each new cloze polished for long-term memory.
- Prioritizations skills. New students, however smart, are often totally blind to the priority of knowledge. They are unable to judge the extent of their present and future knowledge. They find it difficult to differentiate gold from garbage. Seemingly precious knowledge becomes garbage if it does not pass the priority test that ensures it can ever be mastered. The lifetime capacity of the human brain is limited. Without understanding the limits, newcomers to incremental learning will often embark onto a futile quests for mastering details that would steal room needed for memories that are essential to one's existence (professional and beyond). With every passing month and with the constant increase in the size of your knowledge and your collection (i.e. also "knowledge to-be"), you will better understand your ultimate limits. Your knowledge selection skills will keep improving for years to come.
- Editing and SuperMemo skills. SuperMemo is complex. It takes months to fully explore. SuperMemo is also keyboard-oriented. The list of keyboard shortcuts is overwhelming. Only with the mastery of the keyboard and SuperMemo itself can you become a true pro of incremental learning who can whiz through dozens of articles per hour. You will edit dozens of little pieces of texts to optimally formulate your questions. Speed-reading and semantic skills, combined with editing skills will help you instantly mold the texts in your collection to suit your long-term goals.
Knowledge database
Once your collection grows rich in materials from various domains, you can use it before you use Google to search for information about a subject within the material that you already want to learn. The search results will not be as rich, but they will be far more focused on the areas of your interest. While doing search&review, you will be able to reduce the future workload in many areas. This is fun!
All-in-one archive
Once you become proficient with SuperMemo you can use it as an all-encompasing archive of all your media files. Those files do not need to be part of the learning process, however, you can combine archiving functions with the incremental process (e.g. when annotating your family photo album collection). SuperMemo may be a great way to get rid of those dusty paper documents, tape recorder cassettes, CDs, photo albums, school notebooks, etc. You can archive this in dedicated folders on your computer and import it all to SuperMemo. Incremental processing of archive has many advantages. For example, while annotating family pictures from two centuries ago, you can fill in the gaps in information by simple face recognition that may rely on a degree of learning or creative juxtaposition of photographs from different sources in close intervals. Incremental audio can also convert your jukebox SuperMemo into a stream of music with a maximized fun factor. There are millions of ways of sorting tracks on your media player device, by filename, by date, by annotation, by priority, by recent viewing... all that does not compare to the incremental review process. This is because the quality of your experience when processing music or photos is based on the same forgetting mechanisms that affect learning. You want to see or listen to some things more often than others, but not too often. Forgetting is the key to experiencing music or imagery or videos again and again with a heightened degree of fun, pleasure and, last but not least, learning.
Fun
The sense of productivity might be one of the most satisfying emotions. This is why incremental learning should be highly enjoyable. This only magnifies its powers. To experience the elation of incremental learning, you may need a few months of focused practice. You will first have to start with the basic tools and techniques. Then you will need to master knowledge representation skills. Finally, you will need a couple of months of heavy-load incremental learning to perfect the details and develop your own "incremental learning philosophy". You will also need to grow your collection as size matters for the fun of learning. Last but not least, incremental learning requires good language skills, some touch-typing skills, and patience (SuperMemo will often want you to go against your own intuition). Although the material is originally imported from electronic sources, it always needs to be molded, shortened, provided with context clues, restructured for wording and grammar, etc. The skills involved are not trivial and require practice.
If you have used SuperMemo and/or spaced repetition, you may have concluded that learning with SuperMemo is boring due to its repetitive nature. Those who can compare the classic SuperMemo with incremental learning will testify that incremental learning is by far more fun. In contrast to classic SuperMemo, where you focus on the review of the old material, incremental reading interweaves the old with the new. Novelty adds to the fun and efficiency of learning. Incremental learning is by far more challenging and colorful than typical repetitions. In addition to review and reading, you can import rich graphics, audio and video to spice up your learning process.
In the end, you risk becoming seriously addicted to incremental learning. The statement "I do not read books" should no longer be considered in a negative light! As long as you keep incremental learning in rational check, it will benefit you and others around you.
Disadvantages of incremental learning
Most of disadvantages of incremental learning come from factors that are a disadvantage in nearly all human pursuits: opportunity and overhead costs. However, there are also disadvantages that come from the fact that incremental learning is not for everyone. Poor selection of knowledge may result in wasting time on low-quality learning. Moreover, incremental learning may lead to frustration, stress, addiction, compulsive use, and other undesirable effects on user's psychology.
Here is the short list of disadvantages to consider:
- opportunity costs: each time you learn with SuperMemo, you are not doing something else. You might be neglecting your creative pursuits, other people, your children, your own health, etc. Incremental learning makes sense only if it is done in the right proportion to your other activities. That proportion will depend on your skills, goals, profession, lifestyle, personality, and more. You need to strike the optimum balance on your own. It might be just a few minutes to polish your English or professional knowledge. Or it might be a few hours if you are a medical student. You always need to keep opportunity costs in mind and keep a score of costs and benefits.
- overhead costs: there is no way around a steep learning curve in incremental learning. You will be thwarted by limitations of software, and the overall complexity of the concept. You will wonder why some solutions in SuperMemo have been set upside down against your best intuition. You will keep improving your skills, and strategies over long months and years. Even mastering the basic techniques will take a lot oftime. You should be aware of that difficulty before you embark on the process that is bound to cause some stress and frustration at the beginning. At the same time, you should find hope in the fact that for a pro, the overhead costs are negligible. All extra operations are semi-automatic while the learning process proceeds largely uninterrupted in student's mind. While keystrokes are issued, knowledge is actively being processed by the memory system. All operations have been optimized for pro use. Once you get to a pro level and follow the recommended strategy, overhead cost disadvantage will cease to matter.
- learning garbage (GIGO): if your selection of learning material is poor, or your formulation skills inadequate, you risk wasting lots of time on learning things that you do not need or that do not bring a tangible memory effect. This is why you must read 20 rules of formulating knowledge, keep knowledge selection at the front of your mind, and be honest with your priority queue.
- frustration and stress: incremental learning is not for everyone. It requires a certain level of proficiency with the language that may be hard for some to reach. It requires a mind that is somewhat abstract-enabled. Did you do well in math? Or science? These are good omens. If incremental learning is not fun after a few months of determined study, you need to re-read this entire article with utmost attention. Otherwise, your incremental adventure will not bring fruit.
Incremental learning must be fun to work!
Incremental learning is not for everyone
Incremental learning is powerful. We believe it might spell a revolution in learning. Its present incarnation will reach only a small fraction of society. This is why:
- Most of people will never arrive to this website. A great part of this planet do not have access to the Internet. Of those who are privileged enough to be able to use Google or Wikipedia on a regular basis, most are too busy with work, family and other pursuits. The rest are busy with Facebook, Twitter, games and other "blessings" of the Internet.
- A significant fraction of the users of the Internet realize that the web offers incredible self-help opportunities. Many of those will realize that their memory can be improved, and that their learning can be advanced to a new level with some help from the net or software. However, the language barrier is the first big sieve. The best materials about learning techniques have been published in English. Language divisions result in a global inequality in the access to information. You can read about SuperMemo in a couple of major languages. Perhaps you might learn about incremental reading too. The article you are reading at the moment will take months or years to percolate to non-English areas of the net.
- For anyone interested in learning, it does not take long to find out about spaced repetition. The term was quite exotic when first used in the context of SuperMemo in the mid 1990s. In those days it could only be found in a couple of scientific publications. However, it was SuperMemo that helped popularize the concept, which now has entered the popular culture. Those who seek better memory will quickly be informed that spaced repetition is the way. They will get they introduction to spaced repetition from SuperMemo freeware, or an array of other excellent free spaced repetition applications, some of which use SuperMemo algorithms. The fact that the newest SuperMemo is a commercial product will prevent many potentially excellent students from ever going in the direction of incremental learning. This must made be clear then. At the moment of writing, SuperMemo 2004 is freeware and supports incremental reading. It might be missing the priority queue, but this will matter only much later in the process when you build a collection of unmanageable size. In SuperMemo 2004 you can do Import, Extract and Cloze. That's the core of incremental reading!
- Among users of SuperMemo, only a fraction will ever become interested in a complex concept of incremental learning (probably still below 5%). A typical newcomer is more likely to drop out altogether than to move on to the next level. The chief culprit is the incompatibility of SuperMemo with the human nature and the modern lifestyle. Stressful and busy lives do not help in forging new paths and acquiring new habits. It is not just that humans like to live in their comfort zones. It is also that the pressures of the modern dog-eat-dog society are pretty effective in stifling higher inspiration, lifelong learning, creative pursuits beyond one's job, etc. Those issues are inherent (human nature), or systemic. As such they cannot be easily remedied.
- Some users might hold a relatively positive opinion about incremental reading, but will excuse their lack of commitment by technological limitations of SuperMemo. For example, "unless you give me a Mac version, I won't go there", "I hate Internet Explorer", "Your interface comes from Windows 98 era" or "I will come back if you have a mobile version". Incidentally, there is an inherent incompatibility between mobility and incremental learning. Mobility correlates with multitasking and low attention (interaction with others, arriving mail, phone calls, browser pop-ups, etc.). The power of incremental learning lies in balancing creativity with attention. As such, incremental learning is inherently immobile (unless you understand mobility as a transfer between two or more peaceful and static environments). In addition, without a standard-size keyboard, incremental reading might feel like paddling up the creek.
- Among those users of SuperMemo who get down to reading about incremental reading, a large proportion will come with a preconceived goal: proving that incremental learning is not really worth the investment of time. "Negative reading" is more likely to occur in a bad state of mind: low-spirits, irritation, or reading outside one's optimum circadian brainwork bracket. This preconception may be largely subconscious and based on a defense mechanism: proving that incremental learning is a weak concept is easy, should save one a great deal of investment in mastering the concept, and prevent the need to leave one's comfort zone. Discovering that incremental learning is a must will simply augur long hours of plodding through the documentation that is notorious for its poor readability index. The presented article is harder to read than 70% of articles at Wikipedia. The ultimate judgement is strongly correlated with your present state of mind. You are more likely to say "Incremental learning is full of fluff" or "Incremental learning goes against human nature" than to say "I have discovered a new great technology that will change my life". You might be just seeking affirmation of your preset frame of mind: "Incremental learning must be a hoax or at least a waste of time", or simply "Incremental reading is not of much use in my particular profession". It is easy to find the desired confirmation. Imperfections in this article will provide a rich material for dismissal. A perfection is not achievable. Prejudiced mind will always find a way to misinterpret. Naturally, if you are enthusiastic about incremental learning at your first encounter, this is a very good predictor of your ultimate success.
- Having passed all this rich obstacle course, you are now bound to be in a tiny group of people who arrived at this point. The good news is that you might be part of a special elite. People with fertile minds who are open to new challenges, motivated well-enough and self-disciplined enough. Naturally, you might have equally well come here exhausted with your failure in learning, in hope of finding a remedy to your recent bad exams results. Whatever the answer, the road is still very long. Even with a brisk mind and great enthusiasm, you may still drop out at later stages.
- When reading about incremental learning, you might hit another major obstacle: "This is more convoluted than I thought!", or "The whole idea of priorization makes me nauseous", or "The toolset may be rich but is it natural?". You can get discouraged either by incomplete understanding of the concept, or the incompatibility of the concept with your personality.
- If you have already decided to try incremental learning, and you have SuperMemo 16 installed, you may get an unpleasant shock. SuperMemo 16 is not user friendly! It has been optimized for pro users and only simplified enough at lower levels (File : Level) to make it somewhat palatable for a novice. You can overcome this impression only with a firm belief: incremental learning works and it is worth the investment of my time. After a year, you may love the solutions you hated at first in SuperMemo. User unfriendliness and complexity will make many give up in the first days or weeks. Those dropouts rarely return! We are guilty here too. New solutions are never perfectly encapsulated and/or interfaced. You will get your neat iPad and Android version only when incremental learning is more popular, which is not soon.
- The dropout rate in the first weeks is still high. Some of the main problems: importing unsuitable text, difficulty in parsing the text with extracts, losing context of extracts, comprehension problems (not related to SuperMemo), clozing texts that are too complex, difficulty in formulating items, excessive time spent on styles and templates, learning overload, confusion, problems with SuperMemo (e.g. layouts), lack of sense of progress, etc. Without clear gratification, many users come to the conclusion that the cost is greater than the benefits. They are not wrong. It is not easy to get a return on your investment in a month or even longer. Few users start their learning swiftly on a wave of solid enthusiasm!
- Many of the advantages of incremental learning rely on the size of your learning collection. The value of search&review increases with the size of the collection. At the beginning of the process, when collection is knowledge-poor, you may feel like laying the first brick of a large pyramid on a vast boring desert. The greatest fun can be found at the top of the pyramid, when you can see the extent of your knowledge in a good perspective. This metaphor should not imply your pyramid will ever stop growing. You keep adding stone blocks to the sides. The pyramid keeps growing high and wide for lifetime.
- The extent of failure does not only cover the dropouts and the never-has-beens. Even long-term users may enter a never-ending struggle with item formulation, complex material, priorities, overload, etc. The later you start, the longer the transition from pain to fun. Old habits die hard. There is one clear litmus test for success: once incremental learning is fun, you know you do things right. If you have not reached the level of fun after a couple of months of trying hard, you need to re-think your strategies. For example, you may need to start from reading this article cover-to-cover again.
- If you happen to be a happy user of incremental learning, your knowledge will keep growing fast, and your hunger for learning will keep increasing at an ever faster rate. This makes you a part of a very tiny elite. This also imposes an obligation. It is time to help others reach your level!
Big picture in incremental learning
A frequent reservation voiced by skeptical observers is that dismembering texts into little units will result in an inevitable loss of the ability to see things from a distance in their entirety. The question is: Does incremental learning produce a loss of the big picture? What the skeptics fail to appreciate is the power of spaced repetition that stands behind SuperMemo. The SuperMemo method ensures high retention of once-mastered knowledge. This means that there is minimum disintegration of the coherence of knowledge once it is understood and well modeled in student's mind.
The main advantage of SuperMemo is that you convert lots of disparate pieces of information into a solid model of reality that lives in your memory. All these pieces can be dispersed randomly in your collection like pieces of a jigsaw puzzle, however, they fit into a coherent entirety that stays firmly intact in your mind. In other words, incremental learning is reductionist at the level of knowledge processing, but is holistic at the level of memories stored in your brain.
The big picture worry comes from the fact that in traditional education, students rely heavily on their short-term memory. They cram a single subject intensely before an exam only to forget most of that knowledge in the following months unless the subject is reviewed in later courses. It is true that short-term memory can act as a glue that holds the big picture in memory. However, it is the short-term memory and the weakest long-term memories that are gone first. With that in mind, it is only natural that you might worry that if you start intermingling more than a few courses, you will end up with chaos and confusion. It is not the case with incremental learning. New memories, once established, are gradually reinforced to permanently enter the long-term storage. All incremental learning does is to help you focus on a small portion of the material at any given moment.
In traditional (unspaced) education, the big picture is maintained with the glue of short-term memories. As such it is volatile, and subject to forgetting. In incremental learning, the big picture has a lasting value!
Worrying about the big picture in incremental reading is as if you worried that you might forget the structure of your family just because you meet too many members at the same time at a big family occasion, or that you might forget your name when focusing too much on spelling its individual letters. Once the big picture resides in your long-term memory, you can play with details to your heart's content. Today, tomorrow, or in a couple of years.
Incremental learning can make you smarter
User of classical SuperMemo, T. Sz. wondered:
If I use incremental learning for a couple of years. How will that affect how I am perceived by others? Will they see the difference? Will I be smarter and appear smarter? Will I be able to shine with knowledge in social circles? What do people say after 20 years of using incremental learning?
Incremental learning is just a few years old. For example, incremental reading was introduced in 2000. The essential concept of the priority queue was introduced only in 2006. Without the priority queue, massive learning may lead to massive chaos. Incremental video was born in 2009. So you won't find users with 20 years of experience.
Incremental learning is faster
Despite the young age of incremental learning, it is easy to theorize about its power. This is because learning incrementally isn't much different in its ultimate effect as other forms of learning (e.g. extensive reading, studying for the university, research, etc.). For that reason, the results will be comparable. The main difference is that you will get to the levels of higher knowledge much faster (assuming sufficient skills). This way, someone with a few months of intense incremental learning, may get the knowledge and act not much different than a university graduate. Naturally, incremental learning will not substitute for laboratory practice, problem solving, discussions with friends, and professors, etc. So there will be differences. You can then ask: how does the university make you into a better person?
No amount of learning can eliminate ignorance
If you hope that incremental reading will make you a universally knowledgeable and smart, you are wrong. Human knowledge is vast enough for a 2-year-old to know things that a PhD does not know (esp. if he is trainedfor the trick, e.g. to answer "What is the capital of Burkina Faso?").
Incremental readers are different
Incremental reading is more likely to be less focused and more general. At the university, you may learn extensively on a specific subject, while in incremental reading you are more likely to stray to multiple related areas depending on your interests and the encountered gaps in knowledge. Your priorities will reflect your individual profile and your knowledge may be far more customized to your own needs and passions. All in all, an incremental reader will not differ much from a well-learned person. The main difference may come in personality because only a few have the mental characteristics needed to get interested and then sustain the incremental reading process. Thus incremental readers may appear more knowledgeable just because of their natural curiosity or even obsession with knowledge. This quest for general knowledge may result in short moments of amazement with the gaps in knowledge exhibited by other people. In September 2013, scientists announced that Voyager 1 entered the interstellar medium. A panel of high-IQ journalists on a respected news channel discussed that historic moment. One of the journalists mentioned that Voyager 1 was launched in the 1990s and has now left the solar system. The other journalists nodded. This is where an obsessive incremental reader may stumble and realize he or she is indeed a bit different.
Nobody likes a smart aleck
It is not how others perceive you that matters, but how you change your thinking and the ability to solve problems. In most cases, few people in your surroundings care about your problems and your goals. The knowledge you obtain for those goals will be of little interest to others (beyond a narrow circle of close friends). If you ever attempt to show off at parties, you will rather be politely dismissed as an annoyance. Being a smart aleck is universally perceived in a negative light. If you shine with your knowledge in a relevant context (i.e. not for the sake of shining), the perception will be different. We all love the doctor that can provide an accurate diagnosis at a glance and instantly come up with a solution to your health problem. However, chances are rather slim that you will be able to show off your specialist knowledge at a party (unless it is a professional party of your colleagues in the field).
Reward in higher awareness
The greatest advantage of incremental reading may show in the areas of general knowledge. These are the areas that most of people neglect due to a simple lack of time and lack of sufficient pressure or motivation. Astudent may need to study for his geography course, a medical researcher may need to read dozens of papers, but they both may have too little time or need to refresh the ABC of physics that might otherwise be useful in understanding things that happen around them. An obsessive incremental reader might therefore reach a sort of higher level of awareness. If you hear about a chaffinch for the first time in your life, you might likely say "I have never seen that bird". However, you might then be amazed if you see the bird a few times in the course of the following week.
With a narrow focus, few people are able to point to the galaxies that are likely to collide with the Milky Way. Knowledge and understanding of similar facts and processes may seem to have little application to daily activities, however, it does seem to change how people view their place in the universe. Ignorance is blind. Knowledge makes you see things that others do not see. That should be sufficient reward.
Smart learning makes you smarter
As explained in Roots of Genius and Creativity: Smart and dumb learning, smart learning will help you get smarter. However, bad learning practices can result in a monumental waste of time. SuperMemo helps you eliminate the problem of forgetting. As such, it can also help you remember time-wasting garbage. The main rule of smart learning is: learn what is highly applicable. Learn things that change your life. Learning things that help you change the life of others. Rules are better than facts. You can employ probability or statistical formulas in dozens of contexts. If you memorize phone numbers, it won't make you much smarter.
Incremental learning can make you dumber
We believe that incremental learning is the acme of learning in 2013. However, it can also make you dumber. If you take on heavy learning, you are bound to suffer from serious memory interference. This means that you will also forget much faster, esp. the things that you do not keep in SuperMemo. Instead of looking smarter, to the outside world, you might appear more forgetful and even absent-minded. You might forget events, promises, encounters, jokes, movies, and all those little memory things that we take for granted. Incidentally, this forgetfulness is also produced by Facebook, Twitter, and the like. In this chaotic modern world, we hardly ever have time to stop and ponder important things. These days you can buy a shower cabin or a sauna with speakers built in. It's a matter of time before you can engage into a conversation with your toilet. Perhaps you already chat with your Facebook friends while sitting on the toilet? This means that the last preserves of peaceful thinking and creativity are in danger of being swamped with information overload. This makes us smarter in a different way. However, without your rational intervention, it may work against your long-term success. The same is true about incremental learning, you must stay vigilant and learn only things that are highly relevant and applicable to your goals and your position in society. Turn off your phone in the night, leave your MP3 player at home when you go for a jogging, and keep your incremental reading in check and order.
Understanding your own ignorance
Incremental learning helps you quantify your knowledge. If you do incremental learning, this might be your most distinguishing feature: you know what you do not know and why. You better understand the limitations of human memory and its value!
Knowledge that makes you smarter
Smart and dumb learning
Not all knowledge is of great value. Memorizing all tributaries of Amazon make take precious time from other areas of learning. Unless you are an expert on Amazon, rain forest, geography, Indian tribes or related areas, you would rather not want to begin your incremental learning experience from that Amazon exercise.
Your learning efforts must be based on high applicability of newly acquired skills and knowledge. If you memorize the whole phone book, your problem solving ability will increase only slightly (mostly through the beneficial effect of memory training on the health of your brain). On the other hand, a simple formula for expected payoff may affect all decisions you make in problem solving and in life in general. It can, for example, save you years of wasted investment in lottery tickets. Millions of people are enticed with huge lottery jackpots, yet they would never agree to give up their whole income for life in order to get it back at retirement in one-off payment, which is a frequent probabilistic payoff equivalent of taking part in lotteries. Using the terminology defined above, you will find most benefit in mastering and understanding highly abstract rules of logical thinking and decision making.
To accomplish smart learning, you will need to constantly pay utmost attention to what material you decide to study. You must avoid short-term gratification at the cost of long-term learning. It may be great fun to learn all Roman emperors and details of their interesting lives and rule. However, unless you study with a big picture in mind (e.g. in an attempt to understand why civilizations thrive or fall), you may benefit less than by struggling through less entertaining but highly applicable formulas of operation research, which might, for example help you optimize your diet, investment, daily schedule, etc. In other words, you cannot be guided by just the fun of learning but by your goals and needs. In time, you will learn to see the link between long-term learning and long-term benefits. You will simply condition yourself to love beneficial learning. Hard study material can still provide instant gratification.
While you focus on your goals, you cannot forget about the overall context of human life. You cannot dig solely into studying car engines only because this happens to be your profession. This would put you at risk of developing a tunnel vision. You might spend years improving a liquid fuel engine efficiency while others would leap years by getting involved in lithium batteries or hydrogen engines. One of the main reasons for which companies go bankrupt is that their leadership fails to spot the change. As corporate darwinism eliminates short-sighted teams, future society will witness more and more intellectual darwinism. To understand the trends and the future, you need to study human nature, economics, sociology, history, neurophysiology, mathematics, computing sciences, and more. The more you lick, the stronger your predictive powers and your problem solving capacity and the creative strength.
Should we learn "trivia" such as "Which year was the Internet born?". The concept of trivia is highly relative! To a child in a kindergarten, the birth of the Internet is rather meaningless. At this stage of development, the child may find it difficult to grasp the concept of the Internet itself. Many parents will wait until the primary school before showing a web browser to their child. The value of putting the date on the birth of the Internet probably develops only in the context of an effort to understand the history of technological development. In this context, 1969 may be as important as the name of Gutenberg. Only when multiple events of the 1960s and the 1970s dovetail together, the commissioning of ARPANET becomes meaningful. When we figure out that we landed the man on the moon before making the first connection via the net, 1969 looms larger. If we dig deeper, we may find it inspiring to know that when Charley Kline tried to log in on October 29, 1969, the network crashed as he typed the letter G. Imagine, you work on commissioning a major installation that you have worked on for several years. You know that the installation implements revolutionary concepts yet it keeps on crashing. You are about to lose heart. This may not necessarily be an emotional event, after all you also need to apply probability to deciding when to give up blind-alley pursuits even after years of investment. The juxtaposition of the small letter G and the groundbreaking concept of the interconnected world will help you see the big picture. If your concept is great enough, you will go on through another 100 crashes in hope of diagnosing the reason. That perseverance may seem to have little to do with "being smart", but it will make you into a winner (given a bit of luck).
Listen to other people's advice and valuations. The younger you are the more you should listen. In the end though, it must be you who determines the criteria for sifting golden knowledge from trivia. Only you can measure the value of knowledge in the light of your own goals.
Remember that not all knowledge can easily be formulated in a declarative manner. Remember then to use the power of your own neural networks: solve problems, practice your skills, compute, abstract, associate, etc. You and others may not be able to see or verbalize some rules but your brain will extract them in the course of practice. Once the rules have been developed, try to formulate them and write them down. This can be of benefit to you and others.
Knowledge that assists problem solving
Problem solving in artificial intelligence can be used to mimic those mental faculties of a human being that we associate with intelligence and creativity. There are many approaches to problem solving such as deduction, induction, abduction, reasoning by analogy or probabilistic methods, neural networks approach, searching in state space, and more. And even though some of these can generate false conclusions or uncertain responses, they can all be expressed by means of deductive methods such as those used in theorem proving in mathematics. Deduction proceeds from axioms or premises towards true formulas or assertions through logical derivation using valid inference rules. The better the selection of assertions and the selection of inference rules, the broader the reasoning capacity of an expert system or human brain. Rich inferential knowledge stored in our memory makes us fast in thinking, creative, intelligent, efficient in problem solving, etc. Yet we need factual knowledge as the raw processing material for derivation. Eventhe creative vein and inspiration can be expressed in terms of multithreaded derivation and backtracking well formalized in logic programming. No magic fluids or reflections of the soul are involved here. Just a plain network of firing neurons recovering the encoded patterns of facts and rules. See also: Roots of creativity and genius.
To boost your problem solving capacity you need to master a great deal of inferential knowledge. If you learn about specific classes of problems to solve, you may need to choose between memorizing the outcome of inference or its individual steps. Both equip you with a formula for transforming knowledge into new quality. Learning derivation steps is costly. At the same time it can equip you with highly abstract derivation rules. You need to balance cost and benefit. We cannot blindly assume that it is better to derive answers to problems than to simply memorize the answers. In problems with multiple instances, we will tend to learn the derivation. For example, it is easier to learn how to derive the third power of X than to memorize all useful pairs: argument-result. On the other hand, most of people memorize the multiplication table at the time when they could still derive the result from bit-operations on binary numbers. Memorizing some 40 or so combinations seems more practicable, esp. that derivation always takes time and we make use of the multiplication table thousands of times in a lifetime. Here memorization saves hours and days in the lifetime perspective. Brain armed with rich factual and inferential knowledge will associate the most remote ideas and derive the most unexpected conclusions. Through a conscious control over this rich reasoning process, we have built the present civilization.
Knowledge that assists creativity
Creativity is based on association of ideas. It is helpful to be born with a creative brain that keeps spewing new ideas in all circumstances. However, creativity can also be assisted. When you master a great deal of facts and rules in areas adjacent to the problem that you try to creatively solve or elaborate upon, your creativity gets enhanced. If you employ incremental learning, the association of random ideas will be a norm throughout the process.
All innovation in the history of science and technology is based on association. Forgetful memory can be helped with external sources of knowledge and each major scientific breakthrough is based on a series of smaller steps, many of which will be based on hours of search, trial-and-error and experimentation. The brain armed with extensive knowledge is more likely to come up with the needed associations. As in problem solving, inferential knowledge is also particularly valuable in creative efforts. The rules that you know, help you derive new truths, and associate these with all your current knowledge.
Two ideas do not come together to produce a great invention unless they sit in the same head. They either have to be called up at the same time or one has to come unexpectedly from the outside:
- Archimedes stepped into a bath and immediately associated the fact with all he knew about weight and buoyancy. Thousands of Greeks at his time failed to make the link. This was not solely because of their less lively minds. It was mostly because of their lack of understanding of hydrostatics
- Isaac Newton is said to have been hit by an apple that produced an immediate use of his knowledge of physics and mathematics to enhance his three famous laws of motion published in Principia by the laws of gravity. Even though the story cannot be verified, it makes for a good example of creative association
- James Watt is rumored to have watched a kettle boil to combine this inspiration with his knowledge of engineering to improve upon the Newcomen steam engine. This association changed the industry upside down in the course of the hundred years that followed
SuperMemo can help you be creative not only by combining various pieces of knowledge in your mind. It can help you generate new ideas while making repetitions! Creative associations do not come from the mere existence of two pieces of knowledge in your brain. Those two pieces of knowledge have to light up at the same time. Only this way can your brain make a connection. Strangely, a repetition related to genetically modified tomato can light up memories related to tomato juice, cucumbers, genetic disorders, take-home dinner, flu or even the silent Mars Polar Lander. If your collection combines knowledge pertaining to different subject domains, the stream of new ideas and unexpected associations coming to your mind may surprise you!
Incremental learning vs. human progress
Incremental learning has a potential to boost your knowledge and boost mankind's potential to solve major problems of the day. However, in the long perspective, the role of human learning will be lessened by the development of artificial intelligence.
Knowledge and history
Throughout the ages, knowledge was the cornerstone of human progress. From Stone Age to Information Age, in pain, we have built a tiny oasis of civilization in ruthless expanses of the evolving universe. The history of the mankind is made of billions of individual lives that keep on sparking and fading. Born of self-preservation instincts imprinted by evolution, history books paint a picture of a constant string of wars, conflict of interest, loss and gain of influences, lust for power and submission to weaknesses of human nature. On the other hand, the greatest achievement of the evolution, the rational mind, kept on contributing to new findings, discoveries, technologies and philosophies. Progress has always hinged on discovering new truths and preserving them for posterity in form of stories, solutions, tools, books, and other carriers of information. Knowledge is the basis of human power, yet it constantly struggles with two forces that regularly diminish it: death andforgetting. We can preserve knowledge in books and other forms of information storage. However, this knowledge translates to value only then when it is used by the creative power of the human brain. The limitations of the human brain will remain a bottleneck of progress for many years to come. We will develop artificially intelligent knowledge processors not earlier than in a decade or two.
Knowledge and death
Death poses an ageless challenge to educating new generations. Years of hard work needed to gain knowledge on professorial level are obliterated in a single act of death. Newborns need to go through years of education before they are able to access, read, and comprehend this text. They all have to struggle with basic literacy skills, lessons of safe sex and teen pregnancy, lessons on superiority of altruism over egoism, the difference between wise and not-so-wise choices, existential questions, etc. Although constant reeducation may contribute to gaining a fresh perspective in each generation, it is also painfully wasteful. As yet, there is no efficient remedy to the death of knowledge. All we can do is to attach more weight to healthy lifestyle and health research. Those two promote longevity of knowledge in a single generation.
Knowledge and forgetting
Forgetting is a natural process that makes it possible to efficiently use the limited memory space of the brain. We forget to dispose of knowledge deemed less important in order to make space for knowledge of higher importance. Currently we have only a limited control over what we remember and what we forget. Today, the most important tool that we can use to prevent forgetting is practice. We can minimize time needed for practice by using spaced repetition (i.e. learning technique based on computing optimum intervals between repetitions). Spaced repetition is the key to maximizing knowledge within a single human lifetime.
Immortal knowledge
Artificial intelligence is our best hope for approaching immortal knowledge. It can nearly eliminate the problem of death (except for the heat death of the universe or factors that we cannot foresee today, e.g. the collapse of space, and the like). Artificial intelligence can also eliminate the problem of forgetting (at least within the bounds of the available storage). Some forgetting is needed to shape crisp associative knowledge, but that is a welcome phenomenon that leads to more applicable knowledge. Despite great hopes we might have about artificial intelligence, the best path towards immortal knowledge must still rely today on the use of the human brain. This is why we believe that incremental learning is so vital for further human progress.
Incremental reading is an extension of traditional book reading
Someone remarked: "If Gutenberg was a blessing then incremental reading might be a curse!". Is incremental reading an attack on traditional books? If you read in pieces and with endless interruption, does it not destroy the storyline?
Whether incremental reading is a curse or a blessing depends on the way it is employed. There is no sharp transition between traditional reading and incremental reading. In the simplest case, you can use incremental reading exactly in the same way as you would read a book. Partitioning of texts and interruptions are not compulsory. You can read the entire text from top to the bottom without a single interruption. This would make sense if you needed a storyline for context, and did not want to bother with committing it to long-term memory. If you do take breaks or skip portions of texts or change the natural sequence of reading, it all happens in situations that have their counterparts in the world of books:
- Interruptions: you can read an entire book in a single evening, but very often you take breaks and read a book in portions on a daily basis. You may even put it back on a shelf in a busy period and return after a few weeks
- Multiple subjects: it is not unusual to read more than one book in parallel. You may pick one that matches your mood for a given evening, or read portions of different books on the same day
- Changing the sequence of reading: many readers are tempted to peek at the end of the book for its ending. Or browse back to earlier chapters to check some details that failed to register in prior reading
- Deleting portions of the book: deleting portions of the text in incremental reading is analogous to dropping them from your memory through forgetting once you read a book. The book is still on the shelf, the original electronic article may still exist in your archive, but your collection or your memory retain only highlights that may get sparser as weeks go by. Years after the original reading you may retain only single quotes or golden thoughts. The rest is gone
In other words, in extreme cases, there may be no difference between traditional and incremental reading. Gutenberg's blessing is safe. If you believe interruptions or multiplicity of subjects are beneficial, you can employ them at greater ease that it is the case with book reading. At the other extreme, you may wish to take on thousands of independent articles, make interruptions a norm, focus your reading only on portions that you deem most important, etc.
A rule of the thumb is: use traditional reading when you read stories or you read for enjoyment. Use incremental reading to process learning material, textbooks, notes, or scientific literature that you need to remember for life (or at least for many months).
Knowledge acquisition: Areas of optimization
There are seven main areas where the learning process can be enhanced. Incremental learning plays a role in each, however, the first two areas will benefit only through your growing experience, and ability to quantify your progress:
- access to knowledge: with the advent of the world wide web, we all have information literally at our fingertips. Searching for knowledge with Google is fast, easy and accurate. Wikipedia is the biggest encyclopedia in human history. Access to knowledge is no longer a bottleneck of human learning. It virtually became a non issue! Web's quality and role will for continue increasing exponentially as more and more people appreciate its potential and contribute to its growth. There are still many complementary sources of information that compete successfully with the Internet. However, it is only a question of time before you will be safely able to rely on the Internet as your sole source of information. The great benefit of reading the web, as opposed to reading the books, is that the hypertext nature of the web enforces a very compact and usually self-explaining nature of individual articles. A jump to a randomly selected page in an average book will leave you confused due to the context-dependence of the material. On the other hand, it is less likely the same confusion will trouble you in a random jump to a selected page of an equivalent material placed on the web. Web authors usually put more effort to add contexts to the page (at least in the form of hyperlinks). In other words, it is easier to build quality knowledge by reading single pages of the web than by reading single pages of paper books. We are getting closer to the ideals of incremental life-long learning as opposed to thorough-review learning which for many ends with the end of school years. In the busy days of modern society, few can afford a thorough review of their rusty knowledge in individual fields. It is much easier to fix the gaps incrementally: today an article on the structure of the atom, tomorrow an article on a healthy diet, etc. And all that strictly adjusted to individual's interests and professional priorities
- selecting knowledge: you will face the need to fill the gaps in your knowledge in many more areas than your time permits or your memory makes possible. You can ask SuperMemo to help you scrupulously note down and prioritize all areas of knowledge that need an enhancement! In SuperMemo, you are the master of what you learn and what you neglect. Your ability to select valuable information will grow in proportion to the acquired knowledge. Incremental learning helps you quantify your knowledge and extrapolate into the future. This will help you be more selective in choosing your learning materials.
- reading: this is the first stage where knowledge makes an actual intimate contact with the brain. Traditionally, it is streamed into memory in a more or less linear manner (i.e. paragraph after paragraph). Incremental learning helps you delinearize this process and optimize reading by enhancing knowledge selection and prioritization concurrently with reading. For example, you should be able to say "This paragraph can be processed later" or "This paragraph requires utmost attention right now" or "This paragraph can be skipped for good even if I decide to read the article again" or "I want to read this paragraph again in three days and in more detail" or "I want to mark this paragraph with lower priority and come to it only after all higher priority paragraphs have been processed", etc.
- representing knowledge: the way in which you present knowledge will affect comprehension and retention (i.e. how well you remember). Things that are simple are easier to understand. Things that are simple are also easier to remember. Many people do not realize the degree to which simplicity can affect learning. Many people doubt that even the most complex material can be presented in a very simple way. Einstein noticed that "it should be possible to explain the laws of physics to a barmaid"
- remembering knowledge: SuperMemo helps you eliminate the problem of forgetting. You will base all learning on spaced repetition that SuperMemo pioneered a quarter of a century ago. SuperMemo produces immense savings in time by scheduling review of the studied material only then when the review is necessary (see: Introduction to SuperMemo)
- life cycle of knowledge: knowledge in your collection and in your memory keeps on evolving and maturing. This will involve continual rewording, reprioritizing, and re-associating pieces of knowledge. You will often give up portions of knowledge that become outdated or lose their high-priority status. You will apply the rules of knowledge representation that will make knowledge easy to remember. Your knowledge will also become more associative in time. In other words, it will become a more suitable ground for making intelligent choices
- using knowledge: knowledge translates to value when it is properly used. In the long-run, skills discussed in this article will indirectly help you become more creative and skillful in using your own knowledge. Not surprisingly, your skills needed to efficiently use knowledge are also part of knowledge itself and tend to grow spontaneously as your knowledge increases
Cost-Benefit Analysis
Cost of knowledge
Each piece of knowledge stored in SuperMemo adds to the total cost of learning in terms of time. If knowledge is well-formulated, we can estimate that a single element will be repeated from 8-20 times in a lifetime. If a single repetition time falls in the range from 3 seconds to 15 seconds, we could conclude that the expected lifetime cost of a single item ranges from 24 seconds to 5 minutes. SuperMemo has a statistical measure called Cost. It measures the total time cost of a single memorized element. In a well-managed long-term learning process, this cost is usually estimated at 2-3 minutes/item in a 10-year bracket. This is then more than the theoretical prediction due to the fact that each collection contains a small subset of so-called leeches which dramatically increase the average cost/item (note that leeches can easily be detected and removed from the learning process).The rational criterion for deciding if a piece of knowledge should be memorized by means of SuperMemo is to judge the benefits of having the given piece constantly available in memory. If the benefits do not seem to add up to more than 10 minutes, the student might simply not add an item to SuperMemo. With a dose of practice, this analysis becomes a semi-automatic process, and should painlessly blend with your life
The cost-benefit criterion is: if costs of not knowing a piece of knowledge is greater than the cost of repetitions in a given period of time, add this piece of knowledge to SuperMemo (otherwise do not addit, or relegate it to lower priority).
Cost
Cost of a single well-structured item in lifetime ranges roughly from 24 seconds to 5 minutes. At any given moment it may be approximated for a 30-year bracket, by multiplying Future repetitions (in element data) by Avg time (in learning statistics). SuperMemo displays this value in the element data window. If your item is ill-structured (i.e. difficult to remember), this cost may bloat! To eliminate ill-structured items use leech analysis.
Benefit
Each piece of knowledge in your collections should be associated with a tangible benefit. Only you can accurately guess the value. For example, the value of memorizing the opening hours of your gym in a given time might be approximated by multiplying (1) the probability you will choose wrong hours by (2) the time-cost of missing the gym. For example, if you believe that the probability is 25% and the cost of choosing wrong hours is 40 minutes, the cost of knowing the opening hours is around 10 minutes. In such a case, memorizing the opening hours will be cheaper than missing the gym. However, if the probability is sufficiently low or the time loss sufficiently small, you should not add opening hours to SuperMemo. For example, if the probability is 10% and time loss is 3 minutes, you are not likely to recover your learning investment! There are naturally less clear-cut cases in-between. If you are not sure if you should add a piece of knowledge to SuperMemo, add it with sufficiently low priority. With overflow tools (e.g. auto-postpone, auto-sort, etc.), you can drag along less valuable pieces of knowledge at little cost.
Priorities
You will quickly realize that there are awfully many pieces of information that pass the cost-benefit criterion. You cannot ever hope to learn all this information. This is actually optimistic. This means that with a good selection of knowledge, you can gain far more than just a few minutes on memorizing the gym hours. You may gain untold hours by learning things that transform your life. Your best tool in making sure you always focus on the most beneficial material is to use the priority queue. If you have too many items to remember, those of lower priority will get a less meticulous treatment and will carry a higher probability of forgetting. However, this also means that they will benefit from the spacing effect and you will learn more of such items at higher speed (despite lower retention).
Selecting knowledge
The Library of Congress holds 10 terabytes of printed materials. Global knowledge resources can be measured in petabytes (10005 bytes). All digital information has already reached zettabytes (10007 bytes). Only a micro-fraction of those resources can be mastered by an individual in a single human lifetime. Even a single copy of the Encyclopaedia Britannica goes in detail far beyond what a single human being can encompass in a lifetime! The actual speed of learning and lifetime learning limits can be measured with SuperMemo (see: Theoretical aspects of SuperMemo).
The microscopic capacity of the human brain has not prevented it from building the present civilization as we know it. The human power comes from:
- collective effort - a billion heads is more than one
- specialization of labor - all collective tasks are subject to top-down functional decomposition and a single brain usually only needs to process a fraction of information at a time
- knowledge selection skills - the associative power of the human brain combined with the selective nature of forgetting help us retain memories that are actually most useful in problem solving
Incremental learning is a great way to combat forgetting. However, forgetting plays an important role in our lives. It runs a valuable garbage collection on knowledge we acquire daily. If the power of forgetting is diminished (as it is the case in incremental learning), your responsibilities in the area of selecting knowledge increase manifold!
SuperMemo will help you eliminate forgetting! At the same time, it will increase your responsibility for selecting knowledge that is truly important and applicable. If used without care and attention, SuperMemo may actually waste your time by helping you remember reels of garbage trivia
A piece of information that occupies just several bytes of your hard disk may carry a relative value that my translate to a net gain of millions of dollars as well as a net loss of millions of dollars. It may also carry no value whatsoever. For example, a sentence written in French "SuperMemo vous aide a mémoriser et apprendre diverses informations comme une langue, des chiffres, etc." may be of nearly zero value for someone who does not know French. At the same time, an item related to a Heimlich maneuver can save the life of a family member. We know that the expected payoff equals the value of the payoff multiplied by its probability. Therefore, the low probability of a family member choking and the probability of actual successful application of the maneuver make the value of "Heimlich item" a fraction of the value of the human life. At the same time, even minor errors in medical knowledge of a physician can actually cost somebody's life and carry substantial negative value!
Frequently, you will find more benefit in memorizing the three best things you have learnt today than in memorizing a whole monothematic article to the last detail!
Readers are leaders
You must have heard it from your parents or teachers that "Readers are leaders". Harry Truman added a pessimistic twist to that claim: "Not every reader is a leader, but every leader is a reader". That qualification tells you that reading is not a panacea, and that making reading smart is vital. With the advent of the web, Wikipedia, blogosphere, and other sources of knowledge, access to information is easier than ever. This also means that information becomes more overwhelming. There are always too many things to read. And it is hard to select from a myriad of essential sources. This is no longer a world with a hundred books of which you needed to pick five. Now you literally have thousands of menu options for a single meal. Old bookworm dilemmas are now even more painful. Search the web for solutions for book selection, and you will literally find dozens of blogs with advice. However, most of the advice is based on volatile skills that are hard to master. You need to become an expert in book selection, in speed-reading, in skimming, in skim-or-read decisions, in highlight-and-review strategies, in margin notes and in underlines. For traditional massive reading mastery (without SuperMemo), you would need to go for the extreme: reading in the toilet, reading on the train, reading on your mobile phone, making use of your dead time, etc. You would need to ruthlessly control youremotions with "not to read" decisions, or "not to finish" decisions, or "not to re-read" decisions, etc.
If you master incremental learning, you will not solve the problem of information overload. However, you will systematically address all issues that pester massive readers. Once you embark on the only rational reading road, you will free your mind from all the dilemmas and stresses involved in reading. Incremental learning helps you focus on learning itself!
As for the bathroom time, incremental learning can free that for creative thinking. After all, you also want to ponder your own ideas, not only process other people's output.
Incremental reading solves all major dilemmas of massive readers! Incremental readers are leaders.
Does incremental reading slow down mastering complex subjects?
Could incremental reading slow down or hamper learning complex subjects such as quantum mechanics? Is complex knowledge based on just "remembering passages" or does it go well beyond it. Any form of interruption or delay while working on many things in parallel can potentially slow down this process. Many people believe that incremental reading is good for cramming, but not for serious learning, esp. when complex subject matter is concerned.
Example Opinion 1: tackling quantum mechanics
Here is an example opinion of someone who never tried incremental learning:
I believe that incremental reading (IR) may slow down or hamper learning complex subjects that require deeper understanding -- as opposed to superficial remembering. From what I'm told, in IR, the student spends but a few seconds on a passage related to one subject, and then jumps to another, completely unrelated subject. Such switching among disparate subjects makes it difficult, if not impossible, to engage in deeper thoughts and thus to discover deeper truths beyond the superficial remembering of passages. When I read, I look for concepts and methods that underlie the necessarily descriptive language used to convey them, and I try to imagine their applicability in my other pursuits. In other words, discovering deeper truths requires deeper thoughts. The latter are difficult to reach if only a few seconds are spent on a subject at a time. As a practical aside, technical papers in hard sciences and engineering are peppered with notational inconsistencies among different authors, different research groups, and different journals. The same symbols may mean different things in different scientific papers. Similarly, different authors may use different symbols to denote the same quantity. Sometimes the differences are gross and easy to spot, and sometimes they are only subtle. When reading one paper at a time, the reader familiarizes him/herself with the terminology and notation, and can follow the line of reasoning while recognizing the subtleties. Having a few dozen (or hundreds!) articles read in parallel, frequently switching among them, creates a nightmare scenario of confusion where the meaning is lost in the jungle of various notations and subtle terminology differences. This makes it impossible to follow the line of reasoning in any one of the papers. Below are a couple of (imperfect) metaphors that may convey the sense of loss when trying to apply IR to learning complex subjects and to discovering deeper truths:
- If you are a wine connoisseur, imagine that you are only allowed to smell the wine, but that you are not allowed to drink it, or even to put it in your mouth. How good would your knowledge of wine be? With practice, you would probably learn to distinguish various wineries, age, etc. You may even be more efficient at it, and be able to do it in record time. Yet, I venture a guess that you would feel something missing, that you would feel somehow cheated, that you would feel that you don't know all that there is to know about wine. And rightfully so. Same with IR. You just 'smell' the knowledge, but you never 'taste' it. It may be enough if your goal is to learn a foreign language. But some areas require that you dig deeper if you want the real insight, the real truth.
- Physical exercise. A well-rounded routine has both cardiovascular and resistance training elements to it. IR is like having only the high-intensity cardio. Sure, if you stick with cardio, after a while you will be able to deliver a small package across town in record time -- and that may be all you aspire to. However, it will not give you the upper body strength to help move a 400-kg optics bench. Same with IR: you may impress your audience with the breadth of your knowledge, but you will have to leave the heavy intellectual lifting to others.
The above reasoning can easily be proven false. We can imagine two extremes:
- all learning is done using traditional textbook processing with all the academic arsenal of teachers, practise, reasoning, interaction, labwork, and more
- all learning is purely incremental with no breaks for free thought, calculations on the margin, walking around, conversation, etc.
It easy to show that both are flawed. For example, traditional learning is deprived of spaced repetition, while pure incremental learning may be seen as deprived of conversation or lab practise. Clearly, the optimum falls somewhere in the mix between the two extremes. Incremental learning is a supplementary tool in well-rounded education. It is not supposed to monopolize your day and your thinking. It should not be seen as a replacement, but as an enhancement. As such, it is up to you to find your optimum.
Incremental reading is all you want it to be. It can be speed-reading, cram-reading, or mass-reading. It all depends on the priority criteria which you choose. For that reasons, it would be best described as a reading management technique. As such it is indispensable independent of the complexity of the studied matter. On one hand, you can speed-read articles faster than in conventional speed-reading and yet leave vital paragraphs for future review. On the other hand, you can meticulously dismantle individual paragraphs and convert them into classical questions-answer knowledge that will stay with your for ever. In addition, you can freely manipulate the volume of the material flowing into the reading/learning process. You can focus on a hundred most important articles or you can opt for thousands. Naturally, in the latter case, your time allocation for individual articles will be minute. For example, if you import 10,000 articles to SuperMemo, you might end up with 50,000 to 100,000 extracts within a year of 1-hour daily reading. In such circumstances, low priority articles will indeed linger for months in the process. Naturally, this is exactly the purpose of incremental reading: focus on what is important without neglecting anything that falls within your area of interest. If your focus changes, you can use search and navigation tools to speed up the review of most important portions of your reading material.
Incremental reading is universal in textbook learning. Whatever complex concepts you need to analyze, and whatever computations you need to make on the margins, you can do in parallel with incremental reading of the textbook (assuming you have an electronic version). An old rule says: whatever you need to remember for life (or at least months), process incrementally (to improve memory, boost understanding, and save time in the long term). Whatever you need at the moment, for the sake of understanding the subject, process in bulk (non-incrementally). By combining the two, you can get the most of your learning.
Metaphorically, a pencil is a useful tool that can enhance your life. You will not want to replace your computer with a pencil, or use a pencil while cooking. However, you can still enhance your life by having the pencil handy. Needless to say, we believe, incremental reading is far more useful than a pencil.
The presented reasoning is not only wrong, it is also based on a few misconceptions about incremental learning:
- It is not true that, in incremental reading, you spend only a few seconds on each topic. The time depends on your needs. It may be a few seconds or it can be an entire day (e.g. before an exam, when doing research, or when being consumed with one's learning passions)
- It is conceivable that an incremental reading novice would suffer from the lack of knowledge of the toolset and get lost in the process thus making it more confusing than it is the case with standard textbook learning. Weighing up pros and cons should always consider an ideal case in which the student truly understands the methods of incremental learning. This often takes months of use. The learning process should begin with easier concepts and easier subjects before more complex subjects can be tackled.
- Some research papers are less suitable for incremental reading. Papers that require a vast use of working memory or a large investment in short-term memory are not suitable for incremental reading. Incremental reading is useful each time you study knowledge with lifetime application. Research papers with complex methodology and rich in new specific symbols and notations are not suitable. You should read such papers in your own way and leave just a few notes ("deep thoughts") in SuperMemo. Use your working memory while it lasts and dump it right after reading. Naturally, for massive learning, you will target texts that produce a minimum discardable burden of short-term memory, i.e. are well-written with concise formulations focused on lifelong value.
- For novices, knowledge acquired with incremental reading may not taste as sweet as for a professional. In the latter case, the "taste" may be exquisite due to a well-established contextual knowledge and solid semantic context that relies strongly on long-term memories. A seasoned incremental reader will have a totally opposite feelings about the wine metaphor. Not only will incremental reading allow of sensing the intricate fabric of the full spectrum of volatiles. Instead of just a single evening, the taste, aroma and pleasure will last a lifetime!
- The effects of incremental reading will always depend on the goals. If the goal is to impress some audience, it will likely be accomplished. However, if the plan is to do some "heavy intellectual lifting", incremental reading will provide a rich toolset to enhance that process and provide you with solid long-term knowledge grounding needed for the job.
Example Opinion 2: struggling with basic physics
Here is another example opinion of someone who tried incremental learning but found it difficult:
I think incremental reading is either very difficult or impossible to use when learning some concepts of physics. For example, I have the following text about the Earth and the Sun, how would you handle this with incremental reading?
The Earth is moving very very slowly away from the Sun. This happens for two reasons. The first is that the Sun is constantly losing mass because of the solar wind. As the mass of the Sun decreases its pull on the Earth decreases and so the Earth moves slightly further away. The second reason is to do with tidal forces. In exactly the same way that the Moon is slowly moving away from the Earth, the Earth is very slowly moving away from the Sun. In the Earth-Moon case the Moon pulls on the Earth creating tides and slowing the Earth’s rotation very slightly, making the day longer. This action has a reaction - the Moon's orbit is speeded up. If something travels faster it must move outwards to remain in an orbit and so the Moon slowly drifts away from us at a rate of 3.8 centimeters per year. The same situation happens with the Sun but the Earth’s influence on the Sun is much smaller than the Moon’s influence on the Earth. The result is the Earth’s tiny tiny drift away from the Sun
The example isn't much harder to process than other pieces of knowledge suitable for incremental reading. For success in similar cases one needs an encyclopedic text or a degree of editorial effort to dismantle portions of more elaborate prose. The presented example poses two obstacles:
- Implicit enumeration. The text mentions two reasons why the Earth moves away from the Sun but it does not name them in an explicit sentence. One needs to read the entire passage to find out the second reason.
- Explaining by analogy. The effect of tidal forces on the Sun is explained by describing similar forces created by the Moon. You cannot extract the "second reason" without including and understanding the "Moon example context".
Here is how the presented text would be handled with incremental reading (note the editorial effort as well as the need to entirely rephrase one of the sentences):
Some authors make incremental reading very difficult by assuming a great deal of knowledge on the part of the reader or, as it is the case here, loading student's working memory with a great deal of data rather than building knowledge gradually (i.e. from the ground up). In the discussed example of quantum mechanics, the basic vocabulary needed to process any meaningful text is pretty extensive and capitalizes on manybranches of physics and mathematics. In addition, good understanding of all concepts requires a great deal of mathematical practice that goes beyond linear reading.
Incrementalism and interruption are not compulsory
If you love to go through texts from cover to cover without a stop, and always find it hard to stop reading a book before sleep, you may still benefit from incremental reading.
There are no incremental readers who did not begin from misgivings about interruption. Paradoxically, the stronger your misgivings, the better candidate for a good incremental reader you might be!
A popular misconception is that there are impatient people who are predisposed to be incremental readers - let's call them sippers - and those who love to devour knowledge in large chunks - let's call them gulpers. The truth is that all creative individuals are of a gulper nature. Incrementalism is both a skill and a habit all gulpers may learn over time.
Nobody loves SuperMemo as of the first day. It may take a few weeks to notice its power. And still, as we do not have sensors of the speed of forgetting, you need a dose of rational mathematical appreciation of what SuperMemo does to your brain. You cannot easily sense the power of knowledge and how fast it is being undermined by forgetting.
Incremental reading takes far longer to be appreciated than SuperMemo itself. To employ SuperMemo, you need to learn only two operations (Add new and Learn). For incremental reading, you need a toolset that keeps growing and improving over the years of use. Yes! Even after a few years of learning, you will discover new ways you can speed up your own learning with incremental reading. It may take a year before you might notice first signs of addiction to incremental reading. A benign form of addiction, mind you, with few negative side effects.
The paradoxical tendency of "gulpers" to become good incremental readers comes from their hunger for knowledge. The fact that you cannot stop reading is a powerful expression of this hunger and it is the primary driving force that will help you become an addictive reader. What you might be missing still is the understanding of the power of incremental reading and the hunger to "switch for more". Incremental reading will help you develop a hunger for maximizing the value of information you are processing at any given moment.
You can begin incremental reading today without ever having to stop reading an article that you find fascinating.
In incremental reading, interrupted reading is a norm, but is NOT compulsory!
You can read all articles from front to back and only use incremental reading tools for prioritizing articles and extracting most important sentences and converting them to clozes. In other words, you do not need incrementalism to achieve solid retention of knowledge. An ordinary web surfer has only two alternatives when encountering an article that seems worth reading: (A) Fascinating, let's read, and (B) Not fascinating enough. Perhaps I will read some other time. In contrast, an incremental reader can determine the priority of the article and always read only the articles from the top of the current priority list (perhaps with a user-defined degree of randomization). Moreover, at any time, he or she can say: Interesting, but not as much as I thought. Let's downgrade the priority and come back later (if ever).
A gulper is driven by a natural neural mechanism that underlies all human progress: curiosity. The same mechanism can be used to magnify incrementalism: curiosity of what article or paragraph comes next. Once you develop a healthy incremental reading process, you will add another natural neural mechanism: impatience. Impatience is also a buttress of progress. We do not like long stretches of low efficiency. We like instant gratification of success and the bigger the success the better. In incremental reading, you are constantly driven by curiosity and yet you itch-to-switch as soon as the text you are reading does not bring sufficient value-per-time. The healthier your incremental reading process, the more value per second you can extract. You will develop a sense of the realistic average value stream, and each time you fall below that expectation, you will add up to the incremental nature of reading (even if the fault is yours, not the text author's, e.g. when the gaps in your knowledge produce poor comprehension). By combining curiosity with impatience, you can convert from a gulper to a sipper. And still you will be able to read top-quality articles top-to-bottom without interruption. Incremental reading helps you prioritize by content instead of reacting to transient evaluative impressions.
You will notice that incremental attitude is a habit you grow as your technical and parsing skills improve. Rarely will you delete lower quality articles, but these will fade in priority and may indefinitely linger in the process. As a result, you will maximize the educational effects of every precious second you spent on learning.
As an incremental reader, you might gradually develop a dislike of old-style books (as opposed to importable e-books and articles). If you choose to read a book, it is as if you said: "this is the most important reading material in the whole world". Then the whole series of paragraphs in the book are considered the most important paragraphs to read in their precise sequence as they appear in the book. You give the author of a book God-like powers to stream information into your brain in a flawless, omniscient, and omnipotent way.
Gulpers and sippers are not biologically different! The conversion from one to the other goes via the understanding of incremental learning, mastering SuperMemo toolset, honing the skills, self-control, rationalization of the learning process, and gradually pumping up the average value of knowledge streamed into one's memory.
Incremental learning for perfectionists
If you are a perfectionist, you may initially have problems with accepting the chaos of incremental learning. You may wonder why you should leave your cloze deletions unfinished before they look perfectly adorned with fonts, stylesheets, and pictures.
If you give incremental learning a more determined try, you will understand that the opposite is true: perfectionists should love incremental learning! Your perfectionist nature should accept the overriding rule: maximum quality knowledge in minimum time. It is not the beauty of clozes in your collection that counts, but the beauty of knowledge in your mind. For a skillful student, incremental learning is based on a set of perfectly-formed strict and rigid rules that guarantee the maximum speed of knowledge acquisition. It is true that some of these rules can make you uneasy at first. If you see a sentence that qualifies for a cloze, the rule is: execute the cloze deletion and defer worrying about its exact formulation to its first repetition. The mere choice of the cloze keyword will leave sufficient traces in your memory to qualify as a repetition. In such circumstances, perfecting the formulation of the cloze will become art for art's stake. A higher level rule is: minimum work for maximum memory effect. Therefore, you will improve the formulation of the cloze as soon as you proceed with the first repetition. And again, you will do only as much work as it is necessary to successfully complete a single repetition act. Again you give up details and frills. Ultimately, your cloze will become perfectly formulated, perfectly prioritized, and perfectly placed in your knowledge tree. Alternatively, it will be deleted or left lingering in your "to do" subset. It is the perfect rules of incremental learning and the perfect learning results that should feed your perfectionist needs, not the perfect "look" of your learning material.
Many people tend to hold the world wide web in contempt calling it the "human information garbage dump". This attitude makes it hard to utilize the web as the "goldmine of human knowledge". Tim Berners-Lee created "perfect rules" (HTML, HTTP) for knowledge dissemination by the populace. We can adapt our own "perfect rules" for mining the web. Incremental learning uses "perfect rules" to convert web data into golden knowledge. As a perfectionist, you should not worry about the chaos of the web or chaos of your collection. What really matters is the perfect golden end-result: wisdom!
Finally, if you still cannot live with imperfectly formulated clozes, nothing prevents formulating them perfectly. The formulations may be more satisfying to your perception, but you will, naturally, learn at a slower rate.
Incremental reading is not an attention destroyer
In incremental learning, it is very important to make the right choice of the learning material. Many texts or videos are unsuitable for incremental processing. SuperMemo user who never tried incremental learningwrote:
It is possible that article structure and quality do matter that much in incremental reading because the real learning bottleneck is the human brain (speed of cortex plasticity)? What if you can only absorb X items of knowledge each day -- if you try to do more, you do something bad to your brain? Here's one idea: If you overload your brain with new stuff, it won't have the time to form meaningful connections between the things you know, so your knowledge may be reduced to the ability to answer gameshow-like questions.
Solving any significant problem requires periods of prolonged concentration. I fear that an information addiction (200 new tidbits per day) leads to attention deficit. Your brain is used to getting something shiny and new every 15 seconds (a new tweet, new funny pic, new headline, etc.), so when you tell it to work on one thing for 4 hours, it doesn't listen. I think I was able to concentrate more on one thing in times before Web surfing.So, to put a tabloid spin on it, incremental reading could be the ultimate attention destroyer!!!
There is a lot of truth in the above reasoning in reference to attention, memory bottlenecks, "meaningful connections", etc. However, comparing SuperMemo to Twitter or Facebook as used by Internet junkies is very inaccurate! The reward in incremental reading is based on quality learning, not "something shiny or something funny". Naturally, nothing prevents "shiny/funny" things to be imported to SuperMemo. This is why the nature of the ultimate reward will also depend on one's personality and self-discipline.
When employed along the recommended rules: incremental reading should dramatically increase the attention (as explained in Advantages of incremental learning).
Learning speed bottleneck
Cortex plasticity is indeed the bottleneck in the learning process. All speed-reading and speed-learning efforts may go to naught if you do not employ spaced repetition, which ultimately determines the speed of establishing long-term memories. Remember that in incremental reading, the volume of the material may be very high, however, the ultimate number of items entering the learning process, in the ideal case, is relatively small (usu. 10-20 per day, not 200!). It simply takes lots of time to fish for golden knowledge that will bring best value in the long term.
Overloading memory and the role of sleep
The existence of the memory bottleneck is the direct consequence of the overload concern. You can overload your learning process with excess information, however, you are unlikely to "overload your long-term memory". The processes of forgetting and garbage collection executed in sleep have evolved precisely to prevent this problem. However much you try to learn excess facts, forgetting will clean up the excess, and memory optimization in sleep will ensure you develop all necessary "meaningful connections". Naturally, this will happen only if you get all sleep that you need (i.e. avoid using alarm clock, sleeping pills, staying up late, etc.).
For more see: Neural optimization in sleep
Learning vs. problem solving
It is true that solving problems requires high concentration. However, in the ideal world, you should devote separate time slots to (1) learning and (2) problem solving. In Covey's terminology, your learning boosts the Production Capacity, while your problem solving time is your Production time. Naturally, you can marry the two slots when problem solving occurs in conditions of information deficit. Incremental reading is an ideal tool for such situations. You can combine the inflow of new information with creative efforts and problem solving while retaining maximum focus on the problem at hand. This is explained inAdvantages of incremental learning: Creativity. You can optimize the degree of monothematic focus by using various tools of incremental reading, esp. Search&Review as well as branch review.
See also: Incremental problem solving.
Internet addiction
Internet distractions can be focus destroyers when working with SuperMemo. However, this is more a matter of self-discipline than an inherent problem associated with SuperMemo. It is up to you to decide if you wish to stray to Facebook or Twitter. Incremental reading may encourage a degree of straying (e.g. to import supplementary material from Wikipedia and/or dictionaries). The whole concept of the priority queue was developed precisely to counteract the cost of such straying. In incremental reading you stray, import, prioritize and... forget (about the excursion to the web). You may visit 20 pages, but instead of wasting time, you import and prioritize. You are back onto your focused path in minutes. The whole process can be under your rational control and the web may become an ally rather than an enemy. Metaphorically speaking, an Internet junkie is constantly distracted with shiny titbits, while incremental reader focuses on fishing for golden knowledge.
Incremental reading boosts attention
Incremental reading increases attention by letting you focus on a manageable portions of knowledge without feeling overwhelmed, without straying, without getting stuck on harder material, without worrying that you might miss important pieces when speed-reading, etc. Your best way to experience that improvement is to try incremental reading. However, you should know that the effects will not be instant. You will need to invest a lot of time in learning the tools, and then even more time in honing your strategies and learning about your own memory and reasoning. Few incremental readers become truly enthusiastic in their first months of learning.
Article quality matters in learning
In incremental reading, you will quickly develop skills needed to instantly differentiate between high quality articles and articles that are full of fluff and wasteful prose. You will indeed fish for catchy headlines, meaningful sections, minimum off-topic commentary, etc. Article quality will determine your ability to employ speed-reading, and to quickly prioritize your material. This has nothing to do with instant gratification obtained from social media, instant news, and other net distractions.
Can you really read thousands of articles at the same time?
A visitor to supermemo.com commented on incremental learning claims:
That skepticism is understandable, and yet we stick with the original claim: you can indeed read thousands of articles at the same time. This is because reading can be understood as a process or as anact. No one can make a sane claim of multiple reading acts at the same time. In incremental reading, only one article receives a laser focus at any given moment of time. Few students read more than 50 articles in a single day, and they rarely read them all in their entirety. However, they may easily read or skim a few thousand articles in a month, and keep hundreds of thousands of articles in the incremental learningprocess. In that sense reading thousands of articles at the same time is an accurate if somewhat enticing description.
To understand incremental reading, you need to understand SuperMemo (or repetition spacing in general), as well as the effects of intermittent reading on memory. Reading in chunks without the help of the underlying learning process based on spaced repetition indeed makes little sense. However, once you master and understand the techniques of incremental reading, you will get the effect opposite to the one expected: not only will you not lose the track of the big picture, you will keep a lasting, durable and coherent memory image of whatever you found important in the processed articles.
In a well-managed incremental learning process, the big picture is retained in a state of better coherence than it is the case in traditional learning.
Incremental reading vs. memory interference
You may have read about interference in learning. When students learn two things one after another, they perform worse than in cases where they focus on one thing. This might sound like a reason to disqualify incremental reading as an effective learning method.
It is true that interference can ruin learning. If you read about a subject without fully understanding it and follow it with another subject that is confusingly similar in nature, you will indeed perform worse intests. However, this effect is much less pronounced if the first subject is studied with solid comprehension. Incremental reading makes it possible to read only as much as you understand. Then it encourages long-term retention by producing cloze deletions. Finally, it periodically rediscovers weaknesses in the learning process and fills the gap. When well executed, incremental reading produces an opposite effect. It minimizes interference by forcing you to resolve contradiction in your material. It ruthlessly punishes all cases of incomplete understanding. In classroom conditions, you can get a foggy pass at subject A, then worsen the fog by digging into subject B. In incremental reading, SuperMemo will force you to jump from A to B and back to A until the two form a harmonious body of knowledge withminimum interference and maximum connectivity. Note that the same research on interference produces diametrically different results when the interfering topics are subject to continual re-reading. Re-reading is frequent in SuperMemo and multiple active repetition of cloze deletions is a norm. The outcome of the experiment may also be obscured by adding a degree of novelty to old reviews which greatly improves attention. Better learning follows in the wake.
Why Wikipedia is better than Encyclopedia Britannica?
Wikipedia is better
- every month Wikipedia is richer and mainstream articles show an ever-decreasing error rate
- Wikipedia is better for incremental reading due to its structure determined by crowdsourcing
- some articles cannot be found in Britannica (e.g. search for "SuperMemo" or "incremental reading")
Britannica is hard
Due to its style, Britannica is often not suitable for incremental reading. It is pleasant to read, it explains things, it digresses, it provides examples, however, it is not fact-packed and context-rich like crowdsourced Wikipedia.
Try working the following text with incremental reading. The text was taken from an article about sleep from Britannica:
In addition to the behavioral and physiological criteria already mentioned, subjective experience (in the case of the self) and verbal reports of such experience (in the case of others) are used at the human level to define sleep. Upon being alerted, one may feel or say, "I was asleep just then," and such judgments ordinarily are accepted as evidence for identifying a prearousal state as sleep. Such subjective evidence, however, can be at variance with both behavioral classifications and sleep electrophysiology, raising interesting questions about how to define the true measure of sleep. Is sleep determined by objective or subjective evidence alone, or is it determined by some combination of the two? And what is the best way to measure such evidence? More generally, problems in defining sleep arise when evidence for one or more of the several criteria of sleep is lacking or when the evidence generated by available criteria is inconsistent. Do all animals sleep?
This piece begins with an ominous context-buster: "already mentioned". It poses interesting questions. However, it will take a while for an incremental reader to find cloze keywords that would answer the most essential question of long term learning: What do I really want to remember for life from the passage I have just read?
Simple English Wikipedia is dangerous
Many users believe that Simple English Wikipedia is better for understanding problems than Wikipedia itself. However, simplified terminology leads to terminological imprecision. Even though the language is simpler, the problems presented may get a superficial or misleading treatment. Simple English Wikipedia might be an advantage if you want a short story of the Chinese Empire as opposed to a lengthy Wikipedia dissertation. However, if you try to understand complex economics or quantum physics, relying on simpler texts may backfire. Very often, you should rather struggle with complex terminology by importing supplementary material. Going the easy way may take you astray.
Incremental reading vs. the books
Incremental reading of electronic materials is superior to reading books or reading in the browser (given the same quality of the study material). All basic reading, bookmarks, and highlight methods start falling apart once the volume of books or articles increases beyond a certain level.
Without SuperMemo, you won't easily prioritize, sort, organize, schedule, re-prioritize, search&review, etc. The whole SuperMemo "engine" in the background is the most important component in the process. For a larger volume of material, when reading in the browser, you will probably be just 5-10% as effective as with incremental reading (in the long run).
In incremental reading you can use the following tools:
- article prioritization
- article scheduling
- article sorting
- read points
- cloze deletions (simpler, faster and more accurate than multiple copy, paste and edit)
- extracts that leave the trace of prior work, set read-points, schedule, and prioritize most important pieces of information
- search&review
- article auto-split, auto-scheduling and auto-prioritization
- many more
Incremental reading is likely to reduce your tolerance for:
- texts with low information content (high prose, low fact)
- poorly structured texts
- texts with referential ambiguities
- texts with low context reference
- texts with poor information anchoring (needed for speed-reading)
Incremental reading will sharpen your skills in:
- text selection
- text prioritization
- semantic/structural processing
- mnemonic processing
- speed-reading
Incremental learning vs. the news
You will rather not want to use SuperMemo to process news!
Donald Rumsfeld claims to live by the rule: "First reports are always wrong".
News carries knowledge that is usually valid in a short term only. Incremental learning is useful only for long-term memories. The greatest benefits of trying to process news with incremental learning is to realize how transient news is, and to moderate the craving for news by making it "old news" through the incremental approach.
These are the main reasons why news is a poor candidate for your learning material:
- knowledge that comes with the news is incomplete. If you hear "breaking news", you know this is about news that is "broken". It is incomplete and inaccurate. If you ever think of retaining it in your memory for long, come back to Wikipedia in a week, or in a month, or in a few years. The news becomes most useful when it becomes history. Most of the time, however, it all gets forgotten by the next "news cycle"
- knowledge that comes with the news is contradictory. If you happen to incrementally juxtapose news with old news, you will realize the extent to which people change their minds as new information becomes available. That evolution in thinking and opinion is probably the most interesting part of news.
- knowledge that comes with the news is scant. What was news yesterday might still be news today with some tiny change in the angle. News is repetitive and monopolized by single "hot" issue. If you watch news once a week, you will rarely miss anything important for your long-term perspective
- knowledge that comes with the news is trivial. Breaking news might be devoted entirely to a plane crash, or a bomb explosion. Unless you or your close ones are directly affected, you hardly ever become a better person by being intimate with the details of the tragedy. Understanding plane crashes or bomb explosions in general is far more relevant. A National Geographic documentary might be a better source of such knowledge. Unless this is your first ever encounter with crashes and bombs, you rarely learn anything of major significance. Your ability to change the world will better be enhanced with other sources of knowledge. Your optimization in this area will also help build a future with fewer bombs and fewer crashes.
News may have more value for you at younger ages when you still need to learn a lot about the world, or when you are trying to learn a new language and want to understand the news broadcast from another country. In such cases, use news mostly as the source of indications of what supplementary material should enter your learning process for you to comprehend the news better.
Unless you study journalism (and need to understand the process), or political sciences (incl. the impact of news on the public), or you just live and die by being up-to-date, you should limit your craving for news and focus on knowledge with long-term applicability.
Example: how breaking news breaks the news
Consider this funny episode from CNN that illustrates the obsession with "breaking news". On a sunny Sunday of September 22, 2013, Fareed Zakaria spoke about Angela's Merkel impact on Germany, and Europe:
Merkel has taken important steps to help Europe's struggling economies, spending tens of billions of dollars directly and indirectly on them. On the other hand, Merkel has imposed austerity on much of Europe, which has been excessive and counterproductive. Her argument is that it is the only way to get governments like Greece and Italy to become more competitive. Now here's the irony...
Now here is a real irony. The intelligent commentary was interrupted by the breaking news related to Angela Merkel herself. The viewer did not get a chance to learn about the historic role of the German leader. Instead he or she got a 2 min. "deal" to watch Angela Merkel vote in a federal election. Three full minutes of relaxing silence and a chance to admire Angela's dress and body language in this historic moment.
Ah yes, if you cannot stand similar interruptions and want to learn about the historic role of Angela, see Zakaria's transcripts at FAREED ZAKARIA GPS: Not the Time for Big Sticks; Interview with Bill Clinton; Will Germany's Merkel Practice What She Preaches?
Minimum information principle
Minimum information principle says that your items should be as simple as possible and always ask a single simple question. Conglomerating information in [[Glossary:Spaced_repetition|spaced repetition] results in slower learning. For example, you may be tempted to formulate items like this:
Question: What was decided at the Council of Trent, beginning in 1545, and how long did the Council go on?
Answer: The basic beliefs of the Catholic Church; 18 years.
Two separate memories should be separated in SuperMemo due to the fact that they nearly always will require different timing of repetitions. If you can always activate the same mental pathway in thinking about the Council of Trent ("neurons firing together" in the same pattern), your particular item has a good chance of surviving long in the process without a memory lapse. However, once you build a large database of similar items, and you review your sizeable material under the pressure of time, your review will always tend to strip redundant pieces of information. Overtime, your nice item will be reduced to the bare bones of information that will often fail its primary test: applicability in real life. It may happen, that despite zero memory lapses, in 2-3 years, someone will ask you about a Council of Trent in a new context and you will be amazed that you won't be able to reasonably answer the question despite having all the necessary pieces of information included in your item. Two memories of different difficulty might be compared to two different planes of different flying characteristics. The difficult piece (e.g. 18 year duration of the Council) might be compared to a slow flying plane. The easy piece (here the reference to the Catholic Church) might be compared to a modern jet. Review of the conglomerated item might be compared to flying both planes at the same speed. In an extreme case, this might be impossible. The compromise speed might be too high for a slow plane, which might disintegrate beyond a certain speed limit, while the faster plane cannot slow down enough without stalling. In our memory, forgetting is equivalent to forgetting, while stalling is caused by the spacing effect. By doing complex and repeatable reasoning at each repetition, you might act as if handling both planes using remote control. However, this is always difficult and requires lots of focus and deliberation at repetitions. Your brain has natural defenses against such "enforced repetitive reasoning". It is designed to be "intellectually lazy" and thus energetically efficient. Practice shows that incremental reading produces many more items. However, those items are usually much easier to remember. In the end, you spend less time on reviewing 5-10 items than you would spend on an item that would conglomerate information and suffer repeated memory lapses or very short intervals.
In the course of the evolution, the brain developed strategies for abstracting away from the details and retaining only the most essential, useful and frequently used information. Those strategies are great forsurvival, but aren't as good in reaching our educational goals. Council of Trent is a typical example of knowledge we wish to have, but that is pretty expensive. This is because, for most people, it does not get reinforced in run-of-the-mill conversations, TV shows, daily applicability, or at water cooler at work. The situation might differ if you, in particular, read a lot on the subject matter. This might help the memory establish itself in an efficient manner. Incremental reading makes it possible to root such difficult-to-retain knowledge firmly in the context, and still make sure that individual repetitions focus on a very specific and cheap-to-retain memories.
This is how the same paragraph might be processed with incremental reading, and paradoxically cause a significant saving in time in the long run:
Question: The Council of [...], which began in 1545 and lasted for 18 years, made decisions about the basic beliefs of the Catholic Church
Answer: Trent
Question: The Council of Trent, which began in [...](year) and lasted for 18 years, made decisions about the basic beliefs of the Catholic Church
Answer: 1545
Question: The Council of Trent, which began in 1545 and lasted for [...] years, made decisions about the basic beliefs of the Catholic Church
Answer: 18
Question: The Council of Trent, which began in 1545 and lasted for 18 years, made decisions about the basic beliefs of [...]
Answer: the Catholic Church
Question: The Council of Trent, which began in 1545 and lasted for 18 years, made decisions about [...]
Answer: (the) beliefs of the Catholic Church
Question: [...], which began in 1545 and lasted for 18 years, made decisions about the basic beliefs of the Catholic Church
Answer: The Council of Trent
In the end, if you are sure this item works for you, check its performance in the course of the next few years. If you pass the interval of 2 years without a lapse, you can say that this particular item indeed works for you. In that case, there is no disagreement between you and the 20 rules. It is just that for most people, this item is pretty likely to generate a lapse within 2 years even if reviewed at correct timing. Depending on the item difficulty, the number of repetitions in the first 2 years might be as low as 3 or well above 20. If your default forgetting index is 10%, this translates to a span from 70% chance of retaining the item to the totally unacceptable 90% chance of forgetting! This last number is little understood and little realized by the users of SuperMemo, and should always make you think a lot about the rules of efficient formulation of knowledge.
Examples: Incremental reading in action
The following examples have been collected from various articles published at supermemo.com. They illustrate how electronic texts can be converted to cloze deletions, and how formulation problems are solved at the level of articles, extracts and cloze deletions.
Example: Cloze deletion
Passively processed ideas in the form of sentences rarely leave a durable trace in your memory even if they are reviewed regularly. Very often, as soon as after 2-3 months, you will notice that at review time, you actually do not seem able to recall that you have ever had a given sentence in your collection. You will quickly discover that you need active recall in order to remember. Active recall is a process in which you must answer questions. For example, you may be presented with a picture of Charles Darwin and be asked to recognize his face. In the long run, you need to replace passive review with active recall. Otherwise, your memory of the fact will not be permanently consolidated.
The fastest way of converting simple sentences into active recall material is to use a cloze deletion. Using cloze deletion, you work with simple declarative sentences like:
WW1 was precipitated by the assassination of Archduke Francis Ferdinand of Austria-Hungary by a Serbian nationalist in 1914
Those sentences are converted into question-answer pairs that can be used in actively stimulating your memory for best recall:
Question: WW1 was precipitated by the assassination of Archduke Francis Ferdinand of [...](country/empire) by a Serbian nationalist in 1914
Answer: Austria-Hungary
Question: WW1 was precipitated by the assassination of Archduke Francis Ferdinand of Austria-Hungary by a Serbian nationalist in [...](year)
Answer: 1914
Question: [...](war) was precipitated by the assassination of Archduke Francis Ferdinand of Austria-Hungary by a Serbian nationalist in 1914
Answer: WW1
Example: Extracts and deletions
Example text (submitted by a student)
After the discovery of Pluto, it was quickly determined that Pluto was too small to account for the discrepancies in the orbits of the other planets. The search for Planet X continued but nothing was found. Nor is it likely that it ever will be: the discrepancies vanish if the mass of Neptune determined from the Voyager 2 encounter with Neptune is used
Example processing
There are many ways in which the processing of texts can be done in incremental reading. The example below is just one of the ways.
Extract 1 and 4 clozes: Pluto and orbit discrepancies
Pluto is too small to account for the discrepancies in the orbits of the other planets
- Question: [...](planet) is too small to account for the discrepancies in the orbits of the other planets
Answer: Pluto - Question: Pluto is too [...] to account for the discrepancies in the orbits of the other planets
Answer: small - Question: Pluto is too small to account for the [...] of the other planets
Answer: discrepancies in the orbits - Question: Pluto is too small to account for the discrepancies in the orbits of [...]
Answer: planets
Extract 2 and 1 cloze: Planet X
Pluto was too small to account for the discrepancies in the orbits of the other planets. The search for Planet X continued but nothing was found
- Question: Pluto was too small. The search for Planet X continued and [...] was found
Answer: nothing was
Extract 3 and 5 clozes: Voyager and Neptune
Pluto was too small to account for the discrepancies in the orbits of the other planets. The discrepancies vanish if the mass of Neptune determined from the Voyager 2 encounter with Neptune is used
- Question: Pluto was too small. The discrepancies [...] if the mass of Neptune determined from the Voyager 2 encounter is used
Answer: vanish - Question: Pluto was too small. The discrepancies vanish if the new [...] of Neptune is used
Answer: mass - Question: Pluto was too small. The discrepancies vanish if the mass of [...] determined by the Voyager 2 is used
Answer: Neptune - Question: Pluto was too small. The discrepancies vanish if the mass of Neptune determined from the [...] encounter with Neptune is used
Answer: Voyager 2 - Question: Pluto was too small. The discrepancies vanish if the mass determined from the Voyager 2 encounter with [...] is used
Answer: Neptune
Example: Processing an article
Reading the article
Let us have a look at an example of a very short, self-containing article, posted in April 1999 on the CNN website. This short article can be read in minutes and can serve as a positive incentive towards adjustments in your diet.
Antioxidants may slow aging process, study says April 5, 1999 Web posted at: 9:39 p.m. EDT (0139 GMT) From Correspondent Linda Ciampa -- Research at Tufts University indicates that a healthy diet fortified with certain fruits and vegetables may slow down and even reverse the aging process. Foods rich in antioxidants -- such as blueberries, strawberries, spinach and broccoli -- have what doctors call high ORAC (Oxygen Radical Absorption Capacity) levels. Middle-aged rats who were fed a high ORAC diet in the USDA-sponsored study experienced less memory loss than those given a normal diet. Some of the older, slower rats became as lively as their younger peers after taking antioxidants. "We prevented both some brain and some behavioral changes that one normally sees in these rats when they hit 15 months of age," said USDA researcher Jim Joseph. Antioxidants are effective in destroying free radicals -- cell-damaging compounds that can help cause cancer and heart disease and speed the aging process. "It's pretty well accepted that aging is due to the production of free radicals. So anything we can do nutritionally to provide additional antioxidants is likely to protect us in the process of aging," Joseph said. That fact already has prompted many to eat a diet rich in antioxidants. "I look at it as sort of a savings account. I'm benefiting today from eating right, but I'm also going to have it in the future," said 30-year-old Cori Alcock. "As I age and grow older, I'll have good health as well."#Title: Antioxidants may slow aging process
#Author: Linda Ciampa
#Date: April 5, 1999
#Source: CNN
Extracting the essence from the article
In the course of reading, you should select the most important sections of the article. The article introduces some facts related to healthy diet and adds a lot of redundant explanations. For your review, you are only likely to need the core message which usually makes up a fraction of the entire text. Please have a look again at the same text with four most critical sections emphasized (numbering is not needed and is used only for your convenience for further reference):
Research indicates that a healthy (1) diet fortified with certain fruits and vegetables may slow down and even reverse the aging process. (2) Foods rich in antioxidants -- such as blueberries, strawberries, spinach and broccoli -- have high ORAC (Oxygen Radical Absorption Capacity) levels. Middle-aged rats who were fed a high ORAC diet in the USDA-sponsored study experienced less memory loss than those given a normal diet. Some of the older, slower rats became as lively as their younger peers after taking antioxidants. "We prevented both some brain and some behavioral changes that one normally sees in these rats when they hit 15 months of age," said USDA researcher Jim Joseph. (3) Antioxidants are effective in destroying free radicals -- cell-damagingcompounds that can help cause cancer and heart disease and speed the aging process. (4) "It's well accepted that aging is due to the production of free radicals. So anything we can do nutritionally to provide additional antioxidants is likely to protect us in the process of aging," Joseph said. That fact already has prompted many to eat a diet rich in antioxidants. "I look at it as sort of a savings account. I'm benefiting today from eating right, but I'm also going to have it in the future," said 30-year-old Cori Alcock
Improving the wording of extracts
Once you extract important fragments from an article, you may need to reformulate individual fragments to make sure they are fully context independent, free of redundant information, easy to read, and formulated in such a way that the beginning of the fragment serves as the introduction to the latter phrases and not vice versa. Please have a look at the example from the healthy diet article. We selected four important fragments and these fragments (presented on the left in the table) were reformulated to become fully-independent pieces of information (on the right). Please note that two fragments have generated more than one reworded fragment and that one fragment was deleted as it appeared to be redundant upon closer analysis.
| The original fragment pasted without change from the CNN article | Modified fragment: shorter and easier to read (sometimes split into more than one part) |
|---|---|
| Extract 1 | |
|
|
| Extract 2 | |
|
|
| |
| Extract 3 | |
|
|
| |
| Extract 4 | |
| After a closer scrutiny, the fragment on the left seems to be redundant when compared with the one listed above. We can delete it from the set |
Generating cloze deletions
We can now convert items generated earlier into active recall items based on cloze deletion:
| Original extract | Cloze deletions generated from the extract |
|---|---|
| Extract a | |
|
|
| |
| |
| Extract b | |
|
|
| |
| |
| Extract c | |
|
|
| |
| |
| |
| |
| |
| |
| Extract d | |
|
|
| |
| |
| Extract e | |
|
|
| |
| |
| |
Although we have generated 20 cloze deletions from the original 5 extracts, it is important to stress that reviewing this much of the learning material will ultimately cost you less time and the memory effect will be better! Note that cloze deletions meticulously test your knowledge of all important semantic aspects of the learned article.
Converting cloze deletions to plain questions
After you extract fragments and formulate active recall questions, you should continue to constantly reevaluate the importance of individual pieces of information, their wording, delete less important pieces and move them for later review, etc. Examples of reformulated cloze deletions can be found below. Note that Clozes 4-6 and Cloze 20 have been split further to eliminate set enumeration (it is easier to independently associate cancer or aging with free radicals than to list all health problems caused by them)
| Original cloze deletion | Reformulated active recall item |
|---|---|
| Clozes 4-6 | |
|
|
| Cloze 12 | |
|
|
| Cloze 17 | |
|
|
| Cloze 20 | |
|
|
Example: Rewording texts
Wordy articles may require some rewording of sentences before cloze deletions can be generated.
For example, the following texts puzzled a user as it appeared to be hard to process incrementally:
In 1892 the Russian botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease, even after being passed through a porcelain filter known to retain all bacteria, contained an agent that could infect other tobacco plants.
In 1900 a similarly filterable agent was reported for foot-and-mouth disease of cattle.
Before you begin learning, you can save lots of time by looking for articles that are properly structured and written in a concise language that will help you save lots of time. For example, Wikipedia is an excellent source. As it is edited by many people in an incremental manner, it is highly context-independent. In comparison, Britannica is wordy, full of pronouns, definite clauses, and various context references.
Where Britannica might say (fictitious example): "Over the next five years, he struggled to obtain a patent for his invention", Wikipedia might say explicitly "In the years 1883-1889, Edison struggled to obtain a patent for a filament of carbon of high resistance". This context-independent style can save you hours of parsing and re-editing.
In the presented example, the first sentence is causing trouble because the author tried to tell you far more than you might wish to process in one go.
One strategy is to start with monster clozes, and simplify them incrementally while learning. However, you could save lots of time with another strategy, in which you split the sentences into more manageable portions. Unfortunately, in this case, some editing will be necessary in the beginning. You will also need to carefully parse the meaning of the passage. You could, for example, separate who and what components of the sentence
who: In 1892 the Russian botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease contained an infectious agent smaller than bacteria.
what: In 1892, Iwanowski showed that the sap from tobacco infected with mosaic disease even after being passed through a porcelain filter known to retain all bacteria, contained an agent that could infect other tobacco plants.
From those two mini-topics, you can generate several clozes that will cover the essence of the passage:
Question: In [...](year) the Russian botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease contained an infectious agent smaller than bacteria
Answer: 1892
Question: In 1892 the [...](nationality) botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease contained an infectious agent smaller than bacteria
Answer: Russian
Question: In 1892 the Russian [...](specialty) Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease contained an infectious agent smaller thanbacteria
Answer: botanist
Question: In 1892 the Russian botanist [...](name) showed that the sap from tobacco plants infected with mosaic disease contained an infectious agent smaller than bacteria
Answer: Dimitri Iwanowski
Question: In 1892 the Russian botanist Dimitri Iwanowski showed that [...](what?) from tobacco plants infected with mosaic disease contained an infectious agent smaller than bacteria
Answer: sap
Question: In 1892 the Russian botanist Dimitri Iwanowski showed that the sap from [...](type) plants infected with mosaic disease contained an infectious agent smaller than bacteria
Answer: tobacco
Question: In 1892 the Russian botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with [...](disease) contained an infectious agent smaller than bacteria
Answer: mosaic disease
Question: In 1892 the Russian botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease contained [...] smaller than bacteria
Answer: an infectious agent
Question: In 1892 the Russian botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease contained an infectious agent smaller than [...]
Answer: bacteria
Question: In 1892 the Russian botanist Dimitri Iwanowski showed that the sap from tobacco plants infected with mosaic disease contained an infectious agent [...] than bacteria
Answer: smaller
Question: In 1892, Iwanowski showed that the sap from tobacco infected with mosaic disease even after being passed through a [...](type) filter, contained an agent that could infect other tobacco plants
Answer: porcelain
Question: In 1892, Iwanowski showed that the sap from tobacco infected with mosaic disease even after being passed through a porcelain filter known to [...](property), contained an agent that could infect other tobacco plants
Answer: retain all bacteria
Question: In 1892, Iwanowski showed that the sap from tobacco infected with mosaic disease even after being passed through a porcelain filter, contained an agent that [...](property)
Answer: could infect other tobacco plants
The above questions are only a rough beginning. Only during learning will you be able to identify holes in these items. You will see where they cause trouble, why they may be hard to remember or what questions are imprecise or confusing. You will fix those deficiencies incrementally while learning.
Example: Conglomerating information
A frequent sin committed by new users of SuperMemo is to create "monster items" that include many bits of information. Those items should tackled by treating all bits individually.
Example of a monster item
Question: a rod-and-tube element temperature sensor consists of:
Answer: a high expansion metal tube containing a low expansion rod. The rod& tube are attached on one end. The tube changes length with changes in temperature, causing the free end of the rod to move
Suggestions
This is a typical case of combining a number of items in one with a detriment to the ability to recall the combined item. The suggestion here is to split the item into a number of simpler items that reproduce the same information in student's memory:
Question: What are the two parts of a rod-and-tube temperature sensor?
Answer: rod and tube
Question: What is the expandability of the tube in rod-and-tube sensor?
Answer: high
Question: What is the expandability of the rod in rod-and-tube sensor?
Answer: low
Question: How is temperature indicated in the rod-and-tube sensor?
Answer: tube moves relative to the rod
Question: Where are rod and tube connected?
Answer: On one end
etc. etc.
Example: Evolution of knowledge
Changes to individual pieces of knowledge will take place in steps upon successive reviews. Here are exemplary steps that show a complete evolution of a single article into a finished item based on active recall:
- Imagine that you find an article on the net, e.g. The criticism of global capitalism, and you decide to read it and remember it for ever
- You import the article to SuperMemo
- You read the article (e.g. once its turn comes up in incremental reading)
- While reading, you extract most important paragraphs. One of these, let us say, refers to Kuznets hypothesis
- The extracted paragraphs will live separate lives in SuperMemo and will be scheduled for separate review, i.e. independent of the review of the parent article. The extracted paragraphs in the parent article will be marked as processed. Once all paragraphs in the parent article are processed, you will terminate the review of the parent article and keep on reviewing only its components (e.g. selected paragraphs)
- Upon the first review, usually after a few days, you read the extracted paragraph again and analyze it as to how it should be processed further. You may decide to postpone it, remove it from the learning process, shorten it or extract the most important sentences that you want to remember
- If you decide to extract a single statement in reference to Kuznets hypothesis it will again be marked as processed in the original extract and will assume a separate review cycle in SuperMemo
- Upon the first review of the extracted sentence, you make further decisions as to its further life in SuperMemo. Let us say, this is the wording of the Kuznets sentence:
Acc to Kuznets hypothesis, growth (from the low income levels associated with predominantly agrarian societies) would first lead to an increase, and then to a decrease in income inequality
- In order to capture the essence, you would probably decide to shorten the above sentence to the following form:
Acc to Kuznets hypothesis, growth would first lead to an increase, and then to a decrease in income inequality
- At the same time, other parts of the same parent article might establish a memory trace that would say that Kuznets hypothesis has been based on relatively weak empirical data. Moreover, recent research clearly indicates that the hypothesis is false (growth actually seems to equally benefit both the poor and the rich). You could then enhance the extract with words controversial or even recently falsified. For example:
Recently falsified Kuznets hypothesis claimed that growth would first lead to an increase, and then to a decrease in income inequality
- Upon the next review of the same sentence, you may decide to convert it into a number of cloze deletions. This conversion will be incremental, i.e. you may decide to first create a cloze deletion asking about the name of the controversial hypothesis and only later ask about its actual meaning (the meaning is relatively easier to remember and shall survive longer in your memory without active recall). Your cloze deletion could then look like this:
Question: Recently falsified [...](name) hypothesis claimed that growth would first lead to an increase, and then to a decrease in income inequality
Answer: KuznetsThis cloze deletion would again assume a separate life from the original sentence in which the keyword Kuznets will again be marked as processed. This is the original Kuznets sentence with one keyword marked as processed:
Recently falsified Kuznets hypothesis claimed that growth would first lead to an increase, and then to a decrease in income inequality
- The same sentence will generate a few separate cloze deletions that will be processed independently. Upon the first review of the cloze deletion created in the previous point, you may decide to simplify it in accordance with the rules of formulating knowledge in learning:
Question: Recently falsified [...](name) hypothesis claimed that growth would first lead to an increase in income inequality
Answer: Kuznets - Upon the next review, you can, but you do not have to, convert the cloze deletion into a standard question-answer item:
Question: What is the name of the hypothesis that falsely claims that income inequality initially increases with growth?
Answer: Kuznets hypothesis - The above question-answer pair is probably as simple as it can only be. Certainly, it is simple enough to be relatively easy to remember. This item will be repeated in intervals determined by SuperMemo. You can decide how well you want to remember it. By default, it will be remembered with 95% probability of recall and require 5-15 repetitions in lifetime. The establishment of durable memory traces in your memory, completes the life cycle of this particular piece of knowledge. The only thing that remains is the memory-sustaining review in intervals ranging from months to years (as determined by SuperMemo)
- Once you convert all important keywords from the Kuznets hypothesis into separate cloze deletions, you will remove the parenting paragraph from the review process. You will no longer passively review the original declarative hypothesis. You will continue repeating individual clozes and that will ensure your perfect recall of the hypothesis for as long as you deem necessary
Example: Building comprehension incrementally
It is not unusual to generate a cloze that will keep causing problems. It is not the subject in question, but the complexity of the sentence that seems to send the brain into a panic mode. You may keep re-reading bad clozes and get the impression that at each re-reading the understanding decreases (instead of growing).
Here is an example of a bad cloze taken from a real learning process. It caused 5 lapses in succession, and needed special treatment to make it palatable and useful.
Question: Companies or other groups are issued emission permits and are required to hold an equivalent number of [...] (or credits) which represent the right to emit a specificamount
Answer: allowances
With some experience, you will quickly notice that the problem resides in the poor quality of the chosen text. Your first red flag should come with "companies or other groups". Unless you are an insider to the subject, you will instantly wonder what "other groups" means. If you look at the essence of your question, you will notice that "other groups" does not add to the core of the question and can easily be skipped. After some analysis, you can make an effort to formulate a straightforward question, however, it is easier and more cost-effective to take an incremental approach (as long as you keep understanding the question, which may not be the case with you).
As soon as you notice that "other groups" are out of place, you can simplify the cloze:
Question: Companies are issued emission permits and are required to hold an equivalent number of [...] (or credits) which represent the right to emit a specific amount
Answer: allowances
You may also notice that allowances and credits are synonymous (acc. to that particular question), and you may not need to tax your memory with both terms. You can therefore make the question easier:
Question: Companies are issued emission permits and are required to hold an equivalent number of [...] which represent the right to emit a specific amount
Answer: allowances/credits
During the next repetition you may wish to simplify the question further. You can now start feeling confident that the question will stick to your memory. If that makes you feel better, you will have made a big step towards better recall:</p>
Question: Companies hold a number of [...] which represent the right to emit a specific amount
Answer: allowances/credits (emission permits)
Some time in the future, you might take yet another incremental step:
Question: [...] represent the right to emit a specific amount (by companies)
Answer: allowances/credits (emission permits)
Finally, you may realize that you question is actually a definition of a term (credit/allowance). As such, it does not even need the cloze. You may also notice that the definition misses an important context point. The original question spoke of carbon emissions (which is probably indicated by the Wikipedia references that provide the context of the question).
Question: (What is the name of) the right to emit a specific amount of CO2 (by companies)?
Answer: (carbon) permits/allowances/credits
With the above definition, learning should finally be easy and fun. Remember that it is a frequently used standard to separate synonyms or equivalent answers with a slash ("/"). This means that any answer will do permits, allowances, or credits. You do not need to list them all and you do not need to remember about semi-obvious carbon prefix.
Interestingly, it can easily be found that the text comes from May 7, 2010 version of Wikipedia. It was red-flagged with "clarification needed", which instantly tells you that you are not the only one who got an issue with the paragraph. In such cases blame the author and search for better texts. In this particular example, the Wikipedia text was improved just 2 weeks later, and the current version of Wikipedia holds a better version (Aug 2013).
Example: Unsuitable texts
Not all texts are suitable or easy to process with incremental reading. You will not want to process a literary novel with incremental reading. You may still prefer to read it on paper in a bathtub. Examples of texts that are difficult to process are: flowery materials, materials rich in explanations and metaphors, programming code, case studies, mathematical derivations, experimental research documentation, etc. Incremental reading is easiest for encyclopedic materials. Materials that are not suitable will often include a valuable message; however, you will often be better off by phrasing it on your own and processing your summary with incremental reading. For example, you would not want to memorize the Linux source code. However, you could find some specific facts or regularities in the code, describe them shortly and then learn the description incrementally (perhaps with snippet code illustrations).
Example 1: Texts that are too general
Here is an example paragraph that caused learning problem to a user of SuperMemo:
A good enterprise architect should enable the right balance between the needs of the organization for an integrated IT strategy, permitting the closest possible synergy across the extended enterprise, and allowing individual business units to innovate safely in their pursuit of competitive advantage.
The user wrote:
I have no problem understanding this phrase (synergy across business units must be balanced against freedom to innovate within business units), and I constructed two cloze deletions from it for either side of the balance, and when presented with either question I can fill in the blanks. Yet, I was in a discussion recently defending a synergy position, not realizing that it might jeopardize innovation, not even realizing I had this SuperMemo question pointing it out to me. In other words, even though I can answer the question in SuperMemo, it is not something that stuck in my memory, i.e. the synergy is not associated with freedom-to-innovate and vice versa (maybe it will after this mail). So, I suspect that I am only able to answer the question based on recognition of the question or some such, and not on recognition of the association. I figure that a better way to associate the two would be to ask something like "what must be balanced against each other" but this question would be so general in nature that it would create serious interference with other questions that deal with other aspects of enterprise architecture that need to be balanced against each other. Or I would have to make it more specific, again risking to give away the answer in the question, which would also not cause the association to form.
Can you identify a problem here?
In similar cases, you need to pause to ponder what kind of questions you want to be able to answer having read the passage. If the questions are too general or too obvious, you just need to trust your own intelligence and creativity to be able to answer them on the basis of your experience and more specific questions in the given area of knowledge.
In this case, keywords such as "synergy" or "innovate" might provide a hazy way to capture the meaning of the passage. However, very general texts are not suitable for treatment with cloze deletions. You may waste unnecessary time on re-reading the entire passage at question time, or waste time on simplifying the passage to capture the essence. In school jargon, you might call similar passages "waffle". They may carry an important message, they may help the flow of text, they might be explanatory, but they do not yield material suitable for memorization. In the extreme case you can juxtapose Wikipedia-like "IT = Information Technology" with obvious "waffle" that cannot be clozed: We should be nice for other people.
In all sorts of exams, you will always need to tackle lots of "waffle". You will also meet teachers who demand fluent "waffle" performance. However, this is not the type of knowledge that will make you a better expert or a better person. If you meet "waffle", pause to think if there are questions that truly flow from the text, or if the text is too general to be handled with SuperMemo. In your case, you might do better by perhaps adding some meatier passages on enterprise synergy or constraints on innovation or... Actually, you are the best person to find supplementary material that will help you better understand the underlying issues.
If waffle bothers you, try to find a Wikipedia equivalent. Due to the nature of crowdsourcing, Wikipedia lends itself perfectly to incremental processing. Once you get the hang and feel the benefit, you will quickly learn to spot text and passages that are less suitable and provide less benefit when processed with incremental reading.
Example 2: Unsuitable text from supermemo.com
Here is another example that comes from supermemo.com. The text itself is not bad, but it resorts to metaphors that should serve as explanations, not as learning material suitable for generating cloze deletions.
Intelligence as processing power: the raw nimbleness and agility of the human mind. When you see a smart student quickly learn new things, think logically, solve puzzles and show uncanny wit, you may say: This guy is really intelligent! See how fast his brain reacts! The student has a fast processor installed and his RAM has a lightning access time. He may though still need a couple of years to "build" good software through years of study. IQ tests attempt to measure this sort of intelligence in abstraction of knowledge. The difficulty of improving processing power by training comes for similar reasons as the fact that programming cannot speed up the processor
The above text is metaphorical. It reiterates the same message a few times using different words in an attempt to find a metaphor that will strike a cord with the reader. Consequently, it is enough you extract only the core message. For example:
Intelligence as processing power: IQ tests attempt to measure this sort of intelligence in abstraction of knowledge
You could also add:
Intelligence as processing power: The difficulty of improving processing power by training is similar to the fact that programming cannot speed up the processor
Once you learn the above 6 cloze deletions (marked by 6 clozed keywords), you will most likely be able to recall that it should be very difficult to train for an improved score in an ideally designed IQ test.
Incremental reading: Summary
- If you are serious about learning, you must learn incremental reading! Without it, you might be missing the best part of SuperMemo!
- Incremental reading makes it possible to read thousands of articles in parallel without getting lost.
- Use Extract (Alt+X) and Cloze (Alt+Z) to extract the most valuable pieces of knowledge while reading. Use the keyboard for maximum speed. However, if you are new to SuperMemo, you can also use the learnbar or the Read toolbar buttons for the job.
- Standard repetitions and incremental reading should be intermingled. This serves variety and creativity. Auto-sort repetitions will sort your repetitions, introduce a tiny degree of randomness, and ensure a steady, moderate, and prioritized inflow of new articles into the learning process. Read more about the priority queue
- You can control the timing and priority of review in incremental reading by modifying intervals (Shift+Ctrl+R or Ctrl+J), priority (Alt+P), and the forgetting index (e.g. Shift+Ctrl+P).
- Use read-points (Ctrl+F7), good titles (Alt+T), reference labels (Alt+Q), and manually inserted context clues to minimize context recovery overhead (i.e. the cost of recalling the correct context of individual questions).
- Auto-postpone will automatically delay the review of the excess of low-priority material. Use Postpone to manually handle the overload or define the postpone criteria.
- Do not forget to review 20 rules of formulating knowledge to make sure you do not waste hours on badly formulated material.
What do people say about incremental reading?
Incremental learning has its followers and its hardline critics. The following two sections present both sides of the story.
Incremental reading in the eyes of its users
Here are a few excerpts from blogs that speak of incremental reading.
Dealing with information overflow
At bobo23.net you learn the following:
You want to read your favorite blogs, you get e-mail newsletters every day, you have websites you check regularly, newsgroups, mailing lists, forums, interesting Wikipedia articles – a lot of digital input you want to keep up with. But unless you make reading on the computer your full time job – you can’t. So how to select the really important stuff out of it?
[...]
This is where the concept of Incremental Reading comes into place. Sometimes you only want to read about a specific topic, sometimes you just want to read a bit of a complicated article or just read about anything randomly to build new connections / enhance creativity. You can all do that with incremental reading and do not have to worry to miss something. Sooner or later (you can influence that) it will appear in your incremental reading process.
[...]
You collect all the information you want to process and store them in one place. Then you review all the articles (or any other kind of information) randomly or by category. You can highlight important parts, set a reading point (bookmark), extract fragments and generate Question-Answer items for later repetitions.
To read the entire entry, visit bobo23.net: Incremental Reading - Dealing with Information Overflow
Len Budney on incremental reading
Len Budney wrote the following:
Incremental reading is another amazing innovation of Supermemo. I haven't seen or heard about such an idea anywhere else!
[...]
You are gradually digesting the article into smaller and smaller pieces.
When those pieces have become truly bite-size, you can convert them to real flash-cards. With a single click you can create "fill in the blank" type flash-cards, or you can create a normal question-and-answer flash card. When the nugget of information is converted to a flash card, you can "Forget" that piece of text: you've digested it all the way down into facts that you won't be forgetting!
I use the incremental reading feature for reading long, complicated documents, and it's world's better than any other method I've tried. (And with a PhD in Mathematics, I've certainly studied my share of documents!) It forces you to read the important bits very carefully--but still saves you time by helping you to ignore the less important bits. I can't recommend it highly enough. In fact, I'd give my left arm to get a Palm application which supports incremental reading!
Visit Len Budney's blog to read the article: Incremental reading
How to supercharge your language learning
In his blog tmwbuckley writes:
Incremental reading is a fairly misunderstood feature of SuperMemo. Incremental reading entails importing your reading material into a flashcard. This can be a huge Wikipedia article for instance, or an entire eBook. Whilst reading, if you encounter a word you’re unfamiliar with, you can highlight the sentence or paragraph it sits in and make it into an entirely new flashcard automatically, ready for you to review later on. By highlighting, pressing Alt+X to extract the segment – you will see the section become blue, meaning this part has been extracted to another flashcard. [...] Incremental refers to reading the content in small chunks over time, until you’ve read all the material and extracted the information you want from it. You can mark where you’ve reached in the reading material up to using the ‘set the read point’ tool on the Read toolbar, so next time you see the article/chapter/whatever, SuperMemo will display it visibly instead of you scrolling down. [...] Once you’ve finished reading the flashcard, and extracted all of the juicy goodness from it, you can delete it using Shift-Ctrl-Enter. This command is different to pure delete, because it will retain all of the flashcards you created from it, whereas delete will cause you to lose these. Which would be a pain in the derriere. SuperMemo, using it’s super-duper algorithm, will schedule the review of these items for you. [...] Incremental reading represents a powerful chimera of extensive and intensive reading. And this can be used with anything – news stories, blog posts, Wikipedia articles.
For the entire article, see: Incremental Reading – How to supercharge your language learning
Taking note: Incremental Reading
In a blog devoted to note taking, MK is skeptical when writing about incremental reading.
MK introduces the process with these words:
The student extracts the most important fragments of individual articles for further review. Extracted fragments are then converted into questions and answers. These in turn become subject to systematic review and repetition that maximizes the long-term recall of the processed texts. The review process is handled by the proven repetition spacing algorithm known as the SuperMemo method.
MK then voices the reservations:
The basic idea is that you "break down" a larger document into smaller chunks in order to learn them by heart. Nothing wrong with that, but this method will not allow you to read thousands of articles at the same time. Nor will it necessarily lead you to understand the big picture.
Here is the blog entry from MK: Incremental reading
Big picture
The issue of the big picture has been raised over and over by observers who are not intimate to the incremental learning process. See: Big picture in incremental reading
Reading thousands of articles at the same time
As for the phrase "reading thousands of articles at the same time", we will continue using that catchy phrase. It should be pretty obvious that we do not mean the same "moment of time" but the same "period of time". We do not envisage a user with a thousand of monitors, nor a user photoreading thousands of articles flashing in front of his eyes in a second. We, naturally, mean having thousands of articles in the learning process, which, in heavily overloaded collection, may mean that an article will never actually gets read due to scoring too low in priority. For more see: Incremental reading marketed dishonestly
The way of the ronin: About incremental reading
The way of the ronin blog says:
What have I been doing instead of updating this blog? Mainly modifying and improving the system which I use for studying and starting a new project based in the incremental reading technique.
[...]
What I want to speak about it’s my user’s experience after using Anki for a whole year in a regular way and SuperMemo for half year (still doing it) also in a regular way.
[...]
SuperMemo has a very complex interface which most of the times makes potential users think twice before buying it.
[...]
After one week or two of using it I got used to it’s interface. In fact, I realized It was quite intuitive.
[...]
What about schools then? Don’t they use the same methods over and over again for years and decades? If all this was true wouldn’t it mean that they should adapt their system to each of their students -which of course they don’t-?
Read more in Anki vs. SuperMemo
How to incrementally read anything
LittleFish in his blog writes:
When I first started using Supermemo, it appeared that Incremental Reading was a valuable feature, but I never really used it. Once I began experimenting with Incremental Reading (Successfully) and adopting the Incremental Reading mindset when I look at learning material, I am now fully convinced of its superiority for nearly all of my intellectual needs. It is light years ahead of its time, and like the core concepts that power Supermemo, eventually it will likely be utilized on almost every level of the educational system (However many years that takes).
[...]
Visit the blog: Supermemo Adventures: How to Incrementally Read Anything
Luis Gustavo Neves da Silva on memorization
Luis Gustavo writes about cramming and wisdom:
'When I learned how to use SuperMemo, one of my first reactions was to show it to everybody around. I was very enthusiastic about the program and its underlying principles. However, I was very disappointed to find out how many people would say: "This is a cramming tool", "This is just memorizing", "This has nothing to do with reasoning or intelligence".
[...]
I believe that in our culture we have even developed a sort of fear of memory as a human weakness that would allow us to be manipulated, and even dehumanized. Just take a look at our pop culture. How many movie protagonists' memories are being erased, changed or manipulated.
[...]
Teachers seems to see no limit in piling up new material in front of the kids and if someone's memory fails ... its all his or her own fault or negligence.
[...]
When asked to explain the reason for believing that memorizing is harmful, the supporters of "reasoning" would come up with a confusing and conflicting mix of words such as memorizing, data, information, knowledge and even wisdom. Looking up these words in a dictionary, you will find a lot of circular references, each word being related to or defined by the use of the others.
Read more: It's more than just memorizing
Incremental reading diagram
bababan.net writes:
I have produced this simple diagram of the incremental reading process. The explanation on the SuperMemo web was too long and too scientific for me, I needed something simple & handy. Hopefully it will also help you to jumpstart into incremental reading with SuperMemo. It only includes the core functionality, for all the bells and whistles, more explanation
Note that the diagram uses old icons, old terminology and old keywords.
Criticism of incremental reading
Incremental reading is useless
Critics of incremental reading are not too numerous or vocal. The credit probably goes to the fact that this technology is relatively new and not too popular beyond SuperMemo insider circles. Nearly all criticism comes from those who never used incremental reading themselves. As such, it hardly ever addresses the substance of the technology. Some of the criticism seem to address the technology in general (e.g. the Internet, the web, computer software, etc).
For example, Emil K. wrote the following criticism of incremental reading:
- Information on the internet is often unreliable
- It will take a lot of time to find a 100% reliable information on the web
- The slow internet connection augments the amount of squandered time dramatically
- Software maintenance wastes more time
- It can be used only when there is a computer available - mostly at home.
I believe that my method is better than what you propose:
- Read a book that has been proven excellent by time and by ratings of others who have spent THEIR time exploring the book.
- Instead of some software and internet, use a pen and a notebook to scan the book for important information and copy down for later examination/memorization.
Also, copy down the source and the date so that when creativity comes, the sources are reliable - it will be a disaster to waste plethora of time on a research only to find out in the end that the sources did not have any statistical significance. Magazines like Nature and Science already publish the worthiest of all research articles. Books by Feynman, Borh, Dirac, and Einstein are already the best in the field. Thus, my letter is a cogent polemic that refutes SuperMemo.
Observer's Opinion: Why I would not use incremental learning?
Here is an exemplary opinion of an observer who is focused on problem solving and short-term goals. For this observer, lifelong learning is understood as "I learn what I need right now". Naturally, this approach is missing an important factor: learning in anticipation.
Massive learning
I do not care about massive learning. I solve problems. I learn as much as I need to solve the problem. After the problem is solved, I go to another. I do not care about long-term knowledge. I am technical. Knowledge in my field goes out-of-date in 2-3 years.
Lifetime memories
I do not care about lifetime memories. I learn for short-term projects. My memory is good. I am a good problem solver.
High retention
As I learn for short-term, my retention is always high (within the scope of my needs).
Comprehension
I understand my texts well enough. If something is unclear, I look for better texts.
Uniform progress
I do not care about learning "nothing about everything". I learn stuff that I need here and now. Why waste time and memory space on memorizing British monarchs. That's good for kids at school, not for a real problem solver.
Creativity
I am creative enough. Thank you. I do not need to mix up domains of knowledge in hope of some elusive Nobel-winning discovery. I solve problems. I keep all my knowledge in my head. I put the pieces together when I need them. I do not have problems with creativity.
Consistency
I instantly recognize contradictions when reading about the materials of interest. I work for short-term projects, keep all my knowledge in memory, and instantly know if something fits or does not fit the model. This is a non-issue!
Stresslessness
I love my job. I do not consider it stressful. Just the opposite. I think struggling with complexities of SuperMemo might give me a heart attack!
Attention
I am passionate about my job. I do not force myself to learn boring stuff. My attention is excellent.
Consolidation
I do not work on projects that drag for years. I do not need to consolidate. I learn what I need, solve a problem, and move on.
Prioritization
I prioritize by what I need at the moment. I need A, I read A. I need B, I read B. In problem solving, rarely do you need to read dozens of articles at the same frame of time. You read what you need and fix things.
Speed (of reading)
I read fast enough. I have no idea how interrupted reading could be faster than normal reading or skimming.
Speed (of formulating items)
I do not need items.
Meticulousness
I am very meticulous. I do not need help in that department.
Training
The training in skills that one is supposed to develop with incremental learning is irrelevant. The skills are either of little value for me, or I get them in the course of my work anyway.
- Recognizing suitable texts - all texts are suitable if they lead me to a goal. I Google, I read, I solve. Period.
- Formulating knowledge - why waste time on formulating anything? I read and work. I need no intermediary time waster.
- Mnemonic skills - all those mind maps sound like a monumental waste of time.
- Speed-reading skills - my speed of reading is fast enough for my needs.
- Semantic skills - I develop these in the course of normal reading too. I agree. The more you read, the better you get at understanding what you read.
- Prioritization skills - I do not prioritize my reading. I read and execute.
- Editing and SuperMemo skills - SuperMemo is one thing I really do not need.
Fun
I am not sure how adding complexity to your life with the concept of incremental learning can be more fun than just doing great things, doing them well, and having people praise your for the good you have accomplished.
SuperMemo user's opinion: Why I do not use incremental reading?
Here is an exemplary opinion of a user of SuperMemo who understands incremental reading, and still has many reservations:
I have been using SuperMemo for 19 years now (with occasional breaks). I understand the concept of incremental reading pretty well. I read about it a lot. Many times I thought of trying it. However, I am still not convinced that I should embark on this journey. Please see my story. I will gladly hear your opinion. Am I mistaken or am I different, you think? Or is the incremental reading picture a bit too rosy?
Learned read-only mentality
I started making repetitions years back with a goal to improving my English. To do that, I relied on learning with a ready-made Advanced English collection containing 40,000+ words and phrases. The learning material was comprehensive (far exceeding my needs), and the default learning process efficient enough to quickly propel me into good command of the language. Encouraged by the results I kept exploring the program but rarely took advantage of the ever-expanding gamut of SuperMemo's new advanced options. It seemed as if I hadn't really really needed them to get the results I wanted (at least in the English language department). All I did was make outstanding repetitions, memorize my daily quota of new words and phrases, and, occasionally, add a piece of vocabulary or grammar which wasn’t originally in the collection.
Incompatibility of my profession with incremental approach
As for my other learning needs, they start with my professional life which happens to be computer programming. And it seems like an area of knowledge which is not particularly well-suited for declarative learning. Furthermore, Dr Wozniak himself admits learning materials for programming are not suitable for processing with incremental reading. In other words, I seem to be unable to realize the promise of incremental reading in my life’s vocation thus leaving me less determined to explore it for other domains.
Stress factor
I believe that I have achieved a pretty good mastery of SuperMemo over the years. It does not mean though that SuperMemo still isn’t able to throw a curve ball every now and then. Take the Spread priorities feature for instance. When I first checked it, I was greeted with 0!!! against the yellow background in one of the fields: Step. I tried to change the value but no matter what I did I kept coming back to square one. As it turned out, it was SuperMemo’s way of telling me there aren’t enough priority positions for the subset I selected. SuperMemo may lack in the implementation department, even though it tries to address this, many times, at great length, in the documentation. In other words, with enough persistence you can find your way around the program. This journey of discovery may be stressful but nowhere near as much as the whole idea of incremental reading if you give it a careful thought. In fact, the more I read about it (at an attempt to dispel my doubts), the more stressful it becomes. Particularly, the entire prioritization stage seems overwhelming (to the point of nausea). The advantages you so diligently describe may all be true (although some are far from obvious and/or instant). Most of those advantage will hold only as long as you set the priorities right. But the entire process seems like a wild goose chase to me (not only because the priority queue is relative in its design). It would be interesting to know how much the student actually spends on priorities in the course of a daily learning session. For example, take a priority scale. In its relative variation (i.e. when expressed as percentage), it ranges from 1 to 100 which is simply too wide (the creators of the ABC analysis recognized that long time ago). I remember reading somewhere SuperMemo novices find it hard to grade yourself on the 6-piece scale. This now seems like a breeze as compared with giving a priority to a piece of knowledge. I understand the intention for more granular control but it is simply mind-boggling. To make matters worse, there are a number of processes (both manual/conscious and (semi-)automatic/unconscious) that erode your painstakingly set priority hierarchy. I do not mind when it actually changes but what if I accidentally stumble against an item whose priority I set as important, it still remains important, but somehow ended up in the later stages of the priority queue (and, from all what I have read, it is more than a remote possibility). When I read the article, I am often reminded of the following quote by Margaret Thatcher: "I do not know anyone who has got to the top without hard work. That is the recipe. It will not always get you to the top, but should get you pretty near." It holds a great promise but it is far from guarantee. I believe, I recognize really well how complex incremental reading actually is, and having that clearly in mind, I conclude your advantages section offers even less in the form of guarantee. You can invest a whole lot of time, and in the end SuperMemo will only make you realize how dismal you are at managing it all (because, make no mistake, you need to carefully manage it). The toolset may be rich but is it natural? Furthermore, it all depends on the correct input. Your advantages include uniform progress. Yeah, right. Developing tunnel vision when you import and process a large number of articles related to a single topic is as much if not (considering our human deficiencies) more likely.
Comment: You need to try incremental approach to get a good feel
In the section: Incremental learning is not for everyone, you can read about personality factors that may conspire to make you fail with incremental learning. It is hard to make a prediction on the basis of your text. The fact that you studied incremental reading is a very good predictor of success. On the other hand, the fact that the mere concept of priority queue can generate stress, tells you a lot about your personality. You might just be one of those who excel at theory and fail in practical situations for a number of reasons. You should definitely give incremental learning a try and see how it works. If frustrations keep multiplying beyond the first two months of use, your chances may drop. It is vital to start from simplest concepts: import, extract and cloze. All the remaining tools should wait for their turn until you start enjoying the process. For the same reason, you should start from learning about things you love (not about algebra or economics). Your hobby, your pet, your favorite sport, health, your favorite music band, your favorite actor or actress, etc. Use Wikipedia as its texts are well-suited for incremental reading. Only after 2-3 months, when you start sensing the new quality of knowledge emerge in your mind, will you be able to anchor emotionally in the process and find sufficient motivation to overcome successive obstacles.
Short comments on the rest of your text:
- tunnel vision: experience shows that incremental learning favors broad learning as opposed to developing a tunnel vision. After all, the more you know, the more you know you do not know. You are more likely to have your day monopolized by a single topic when you do traditional reading or browsing. In incremental learning you face the whole spectrum of your knowledge (with a natural bias towards your interests). Unpredictability of incremental learning sequences, also in different moods or different contexts (e.g. change of interest), increases the quality of the creative processes. This is where curiosity is born. You are more likely to become interested with a seemingly irrelevant detail when you have a peaceful time allocation typical of incremental learning. This is how you keep branching to new areas. This branching is less likely when you work in conditions of stress, time constraints, and information overload, typical to free browsing on the net. In free browsing, you can open 20 browser tabs and struggle with the right course of action: read now, make favorite, save to disk, skim, give up, etc. In incremental learning, you just import all tabs, and return to your main line of thought. Naturally, it helps greatly if you prioritize the tabs. This is a way of consolidating new interests as opposed to giving them just a temporary brush. SuperMemo's capacity to prevent tunnel vision is mentioned amongst its advantages. See: Advantages : Uniform progress
- wild goose chase: the way shifting priorities work in SuperMemo is exactly how priorities behave in real life situations: your yesterday's interests are ruthlessly replaced by today's interests, and so on. This is a wild goose chase indeed. But the fault is not with SuperMemo, but with human nature. Please recall that incremental reading started from reading lists. Priority bias could result in having a thousand or ten thousand top priority articles. This situation was not manageable and not rational. With relative priorities you can observe the process, and work to improve your strategies, and your personal honesty about priorities. This will not stop the wild goose chase, but you have a range of tools to correct your mistakes (e.g. when discovering a neglected portion of the material). However long you think about it, you are not likely to find a better remedy to your knowledge greed than a simple priority queue! You have signaled the problem, but you neglect the fact that in real life, the problem is incomparably greater. In SuperMemo, if you discover neglected material, you can up-prioritize it. In traditional learning, you forget the material and the problem itself. It is better to chase the goose that to have it swept under the carpet.
- stress: if the prioritization process is stressful, you can initially ignore the priority queue. You will needed it only when your collection grows beyond a manageable size. You can then gradually introduce various prioritization levels. For example, you can have a shy start with just two levels: Important: 22% and Unimportant: 88%. You will soon discover that you need more precision, esp. that you will never escape the feeling "this article must land in top 3 articles", which at some point may mean you need decimal places or referencing the priority queue by position.
- user friendliness: the problem of Step in Spread priorities is typical of SuperMemo, which claims to be unfriendly for novices to better satisfy the pros. This option might display a message: "You are trying to squeeze more elements into the range than the size of the range". However, this would make pros apoplectic, as it is very easy to input wrong data. You do not want to waste time on clicking away the message. A pro will just want to correct the input. This problem cannot be remedied by File : Level because Spread priorities is available only at advanced levels. This means that the user should already be inured to the fact that the first use of any function in SuperMemo may be difficult. A more sophisticated solution, e.g. a wizard or messages incorporated in the dialog, would probably not pass Value/Time criterion on the ever-bloating SuperMemo tasklist. You are right, SuperMemo is not nice for novices. If you have simpler solution ideas, please mail them. They are always read carefully.
- programming: it is not true that incremental reading is unsuitable for programmers (for example see: SuperMemo as a new tool for programmers). This misunderstanding might come from statements such as "computer code is not suitable as text to be processed with incremental reading", even though it is conceivable that incremental reading might be useful in code analysis (e.g. when a large number of well-encapsulated short procedures of different priority needs to be reviewed).
Priority queue
Priority queue: Introduction
Human knowledge resources are vast. Our appetite to aquire knowledge is usually also exceeding our learning capacity. Incremental learning makes it easy to import huge volumes of knowledge. However, if you cannot effectively process all that imported knowledge, you risk neglecting high priority material by being overwhelmed by subjects that might be relegated to later study. This state of affair was the main reason for introducing priorities to SuperMemo.
In incremental learning, all elements are organized into a sequence determined by their priority. That sequence is called the priority queue. The priority is determined by the importance of the element for a particular student. Elements with lower priorities will be sacrificed first when the student runs out of learning time on a given day. As a result, only high priority elements will receive the desired level of recall/retention. At any point in time, elements with lower priorities will be more likely to be discovered as forgotten.
During learning, on a given day, elements with highest priorities are processed first.
If you do not finish your learning for a day, do not despair. With the priority queue, you know, you did your best and only lower priority material was left behind. Remember to use auto-sort and auto-postpone to make the most of the priority queue.
Can we learn the entire Encyclopedia Britannica?
Early in the learning process, many students do not bother to prioritize their learning material. This attitude is caused by two factors:
- smaller volume of learning early in the process
- false conviction that human memory is vast enough to hold all that dream knowledge
Do you think you are able to memorize the entire Encyclopedia Britannica line by line, fact for fact?
Chances are your answer might be: "I might be too lazy, I might be too busy, but if I had all the time of my day for the job, I would". Or perhaps "I might not, but I have heard of geniuses able to do it! How about Kim Peek?". If you believe the encyclopedia is within the realm of possible, you will soon realize that you desperately need the priority queue to help you overcome a big surprise: our memory is far more limited than you think!
Assuming we do not deal with humans affected with a mutation to their memory system, memorizing Britannica would falsify the theory of SuperMemo which should apply to all healthy adults. In the light of SuperMemo, memorizing Britannica verges on impossible. There are 44 million words in Britannica's 32 volumes. This translates to 6 million SuperMemo items ("human memory bits") assuming the average keyword extraction on information dense texts as 1:7. Assuming a 50-year learning span, we get to 18,250 days and 330 items per day. Assuming optimum representation of knowledge (say Britannica is already "perfectly formulated") you cannot learn faster for a given level of knowledge retention than with SuperMemo (it simply finds the mathematical optimum), and practice shows it is very difficult to sustain more than 100 items per day in the long run with retention around 95%. In other words, for an intelligent man, for perfectly formulated Britannica knowledge, with SuperMemo, you are hardly able to accomplish the goal with your whole life devoted to the task!
Volume vs. retention battle in learning
Incremental reading makes it easy to import large volumes of learning material from the Internet. By default, all imported material enters the learning process. As a result, large volumes of unprocessed information begin to compete for your attention with most important pieces of knowledge that you decided to remember. It is a clash of priorities. On one hand you want to ensure high retention of your mission-critical knowledge (as in classical SuperMemo), on the other, you want to devour more and more new knowledge.
Before SuperMemo, your learning would largely be based on reading and reviewing books or your own notes. With older SuperMemos, you would divide your time between reading (on paper) and repetitions (on the computer). With incremental reading, those competing processes were blended into one. You can read and review concurrently in SuperMemo. However, for the most avid incremental readers, the balance of priority will always dangerously shift in favor of new reading at the cost of the previously acquired knowledge. This comes from human nature. New reading provides instant gratification: Today, I learned something new. I am wiser now. Reviewing the material you already know will always feel like a burden. We are always unhappy with our forgetful memory. It always feels that the nature should have given us a natural choice of what to forget and what to remember without the painful effort of reviewing what we already know.
To settle the Volume-vs-Retention battle and to resolve the perpetual clash of priorities, you need better weapons than those made available by older SuperMemos. Before the arrival of the priority queue (2006), you would need to use a complex set of tools to employ massive learning and still protect the retention of your most important knowledge. You would use complex concepts such as A-Factors, forgetting index, subset learning, selective postpones, repetition sorting, etc. These tools were poorly automated and required substantial effort and knowledge on your part. In practice, most incremental readers would have to opt for the simplest prioritization tool: moderation. You could best protect your previous investment in learning by limiting your hunger for knowledge.
Newer SuperMemos use a simple and fully automated mechanism that will help you combine high volumes of reading with high retention of the most important material. This mechanism is based on the concept of the priority queue.
Priority bias in incremental reading
In SuperMemo, each element receives a priority from 0% to 100%. Elements sorted by their priority form the priority queue. An element's priority can also be expressed as its position in the priority queue. The most important element in your collection will sit at Position=1 of the priority queue. The queue is a relative queue. This means that if you, for example, insert an important article at Position=3, all items and articles at higher positions will be shifted by one position up in the queue (i.e. towards lower priority). Thus the element at Position=999 will be pushed to Position=1000, while the element previously sitting at Position=3 will now occupy Position=4. The first two elements in the queue, i.e. Position=1 and Position=2, will not move. The relative nature of the priority queue will help you instantly inspect the current priority of each element in your collection. In earlier versions of SuperMemo, you could observe crowding of elements at high-priority ranks. For example, you could amass a large number of topics with A-Factor=1.01 and be practically unable to prioritize within that group. (A-Factor=1.01 is the lowest possible and would correspond to the highest priority).
The fundamental rationale for using a relative priority queue is the existence of a form of cognitive bias, which we will call the priority bias. This bias makes us always think that the newly found article is extremely important to read. The new article feels so important, because we underestimate the value of all the previously imported articles. Our memory is unable to produce an effective estimate of the importance of the current mass of remembered knowledge. Even less so is it capable of producing a remotely accurate estimate of the importance of the mass of knowledge stored in your incremental reading process (of which, usually, only a tiny fraction is part of your long-term memories). The net effect is that we always underestimate the volume of what we know, the volume of what we keep in incremental reading, and the importance distribution of those volumes of knowledge. This psychological mechanism is also the primary force that works against the universal adoption of SuperMemo. Humans are, by biological design, very weak at estimating the size of their knowledge, the cost of learning, and the power of forgetting. As a result, without an intimate knowledge of what SuperMemo is, individuals rarely ever pause to sense the need to use spaced repetition. This underestimation effect is by far more damaging in the case of incremental learning, which is far more complex and has still not been explained in sufficiently simple and catchy terms.
By employing the priority queue, SuperMemo will help you visualize the priority bias and the process in which large volumes of new material quickly displace the old material from your learning focus. Moreover, SuperMemo highly automates the process in which you can handle material overflow and reconcile high retention with high volumes of learning. Incremental reading has always boasted of its capacity to bring the volume of learning to unprecedented levels. With the priority queue, you can nearly take away the moderation factor and increase the volume of learning even further without undue worry about your hard-earned knowledge.
Priority queue in SuperMemo
You can define the element's priority by:
- pressing Alt+P,
- by clicking the priority button (
 ) on the learnbar, or
) on the learnbar, or - by choosing Learning : Priority : Modify on the element menu.

To set the element's priority, you can either choose the position of the element in the priority queue (from 1 to Total), or you can choose the percent value (from 0% to 100%). Position=1 corresponds to Percent=0%. Position=Total corresponds to Percent=100%.
Important! Low position and low percent mean high priority! This counterintuitive choice was made due to the fact that you are more likely to choose a high priority of 0% or 1% than the low priority of 99% or 100%. Typing the number 2 takes much less time than typing the number 98 (roughly 3-4 times less). As you are likely to set priority manually many times in the course of a single learning session, this counterintuitive choice will save you a lot of typing time over years of learning (and will likely be grateful for things set upside down in SuperMemo).
You can use Learning : Priority : Increase on the element menu (Shift+Ctrl+Up arrow) to increase the priority of an element, or Learning : Priority : Decrease (Shift+Ctrl+Down arrow) to decrease it. Those operations also affect the A-Factor of topics.
You can view your entire priority queue with View : Priority queue on the main menu.
Prioritization is difficult before it becomes easy
Everyone struggles with priorities as it is very hard to admit things are not as important as they seem. Of good things, there is a correlation between the hunger for knowledge and creativity. If you struggle with priorities and overflow then it might be a good indicator, as long as you win the battle and learn to prioritize honestly.
To prioritize well, you only need to know that the most important material has priority 0%, while your least important material is 100%. You need to develop a sense for where, in the queue, a piece of information belongs. If you think that everything is "top priority" then you are clearly at the beginning of the road. Pick two items and ask a question: if I was to forget/delete one, which one would that be? This exercise will help you see different applications of different items and different value behind the applications. Another exercise is: try to give items as low priority as you can stomach. Can you make it 10%? Would you be hurt if it was 20%? Would the world collapse if it was 66%? With some conscious effort you will realize that you can live without some portions of your knowledge (after all, most people do not use SuperMemo at all and survive ok). Over months of training, you will get better at this.
If you keep peeking at Protection statistic, you may also realize that sending items beyond your average priority protection will help you clear them from view for a while. This way, if you have created too many cloze deletions that crowd your process, you might actually enjoy sending most of them out of the protected zone, and focus on just one or two that capture the essence of knowledge you are trying to learn.
SuperMemo will not help you much in the prioritization work unless you manually play with intervals (e.g. by saying "this cannot wait 30 days, I must see it in 11"). This tell SuperMemo that the priority must increase slightly.
Sorting repetitions
In a high-volume incremental reading process, you will be served more elements in a single day than you could possibly manage to process in a week (or worse). It is therefore vital that you begin your review process from elements of the highest priority. Low priority elements might linger in the queue for months or years. High priority items should be reviewed at the exact time that SuperMemo finds optimum. Only this way will you be able to meet your requested forgetting index criteria for high-priority material while still being under no pressure to limit your hunger for knowledge. In simpler terms, in an overloaded learning process, the SuperMemo promise of "excellent memory" will only apply to your top-priority material. The lower the priority, the lower the retention (see: Tools : Statistics : Analysis : Graphs : Forgetting index vs. Priority for empirical evidence).
By default, your repetitions will be auto-sorted at the beginning of each learning day (unless you uncheck Learn : Sorting : Auto-sort repetitions). This means that the elements reviewed on a given day will be ordered by priority. In addition to auto-sorting, you can also sort the learning queue manually at any time with Learn : Sorting : Sort now.
You will quickly discover that a precise sort executed strictly along the priority criteria has serious flaws. On one hand, due to the priority bias, you will quickly displace older high-quality material with whatever dominates your current interests. That would be a throwback to your pre-SuperMemo times when you kept reading new material, while forgetting your previous investment in learning. New material always feels very important and will always show a tendency to shift all your previous learning towards lower priority. In addition, you might overwhelm your classical SuperMemo repetitions (i.e. question-and-answer review) with the inflow of new articles to read. Again, instead of making sure your previous investment becomes durable, you keep rushing through new material and forgetting the old.
SuperMemo solves the problems of the priority bias and the problem of the massive inflow of topics by letting you define:
- the proportion of topics in learning, and
- a degree to which the learning queue is randomized.

Figure: Sorting criteria in SuperMemo. Only a small proportion of time-consuming topics is allowed in the learning queue. This proportion is chosen to maximize the fun and efficiency of learning: sufficient inflow of new material combined with the necessary review of your previous investment. Some degree of randomization in the learning sequence is permitted. This way you can re-discover precious articles that were displaced in priority by a massive inflow of new material. In the presented example, topics show a higher degree of randomization than items.
You can determine the sorting criteria by using Learn : Sorting : Sorting criteria. You need to adjust the proportion of topics and the degree of randomization by trial and error. This will all depend on your goals and preferences. If you admit too few topics in the process, you will not gain much new knowledge. If you admit too many topics, you will start forgetting previously learned material. If you randomize the learning queue too much, the whole prioritization mechanism will unravel, and your retention of high-priority material will drop. If you sort repetitions strictly by priority, the new material will keep displacing the old material due to the priority bias. Even for item repetitions, where the priority bias is less prominent, a degree of randomization will help you increase the priority of less appreciated items, disperse clozes generated from the same extract, and compensate some loss in retention by improving the overall speed of learning (through spacing effect).
Proportion of topics tells you how many topics you will be served during your repetitions as compared with items. If you want to ensure that you keep a high retention of previously added material (as per SuperMemo definition), you cannot overload the learning process with new material (new topics) because you will not have enough time left to do your daily item review. In a healthy learning process, you should limit the inflow of topics to 1:4 or less (i.e. allow of repeating at least 4 items per each topic served).
Random repetitions
To make sure you have a good understanding of the contents and distribution of the learning material in your collection, you should make randomized repetitions from time to time. This is to prevent tunnel vision and priority bias. You can randomize repetitions with Learn : Random : Randomize repetitions (Shift+Ctrl+F11), or with Tools : Mercy with Criteria : Sorting options set to Randomize.
Occasional random repetitions may be quite revealing as they will not favor any portions of your material. Your learning will not be biased by an increased proportion of elements such as: short interval elements, long interval elements, specific element types (e.g. articles, extracts, cloze deletions, etc.), element content (e.g. a specific branch of the knowledge tree), the degree of element processing, nor (most importantly) the element's priority. Random repetitions will help you understand the possible negative trends such as an excessive inflow of new material, low retention due to frequent rescheduling, poor formulation of newly created cloze deletions, low quality or applicability of the acquired knowledge, excessive emphasis on certain subject at the cost of other subjects, etc. Most importantly though, random repetitions should help you sense the power of the priority bias. You will notice that you will instantly be tempted to up-prioritize large sections of the material that has slipped your attention while focusing on new imports.
Prioritization rulebook
- Learn to work on priorities of new elements. Try to visualize the entire collection and learn to position elements in the spectrum of your entire knowledge. Try to ignore urgency, and to focus on the lifetime priority of knowledge (unless under a pressure of a deadline or an exam). If all your new elements get priorities of 1-10%, you know you are not being honest. Some of the new material must be down to 80-90%. There are things that you want to know, but you do not really need to know. Add them to your collection, but give them an honestly low priority. Do you learn about movie stars? That's ok. However, unless you want to be an actor yourself (or similar), you should rather give the stars the deserved 95-99%.
- Early in the process, you may find it hard to sense the difference between 30% and 60% priority. Or you may keep setting the priority always to 1%. The fact that SuperMemo displays the priority at four decimal places may make you feel your prioritizations are not adequate. Ignore those feelings. You can start from a 3 point scale: 1%, 33%, and 88%. The more you prioritize, the more natural and automatic it feels. Be patient.
- Deprioritization is very hard and very painful, however, it might be a key to your success in a heavily overloaded collection. It is very easy to wish to up-prioritize nearly anything. You need to train your brain to permit low priorities! You need to let some knowledge go (at least to lower priority areas)! You cannot know everything that you want to know! (unless you want to know little)
- Regularly inspect Tools : Statistics : Analysis : Use : Priority protection : Items (Shift+Alt+A opens this tab as you left it last time). Priority protection is the most honest indicator of what proportion of your collection can actually meet your requested forgetting index criteria. For example, if your Priority protection stand at 3%, you know that no knowledge in the 3%-100% priority bracket is safe! If you keep overrating priorities, items will crowd at high priority positions and the Priority protection parameter will be very low. If you are honest, you will increase that value and make it easier to protect top priority items from being delayed and possibly forgotten. You will be amazed how fast you can increase Priority protection with a focused effort and deprioritization in just a few days (let alone over a longer period)! See the example in the picture below. Such efforts will do miracles to the quality of your knowledge. Importance should always overrule urgency and emotion.
- Regulary inspect Tools : Statistics : Statistics : Protection. This parameters tells you how far you managed to cut into your top priority material in a given session (this is an equivalent of Priority protection for a single day). If those numbers get very low, you need to start deprioritizing your items (or topics). You do not need to cut your import appetites as long as you keep priorities reasonable.
- The most important moments to prioritize elements or element sets:
- at item failure, you need to rethink the priority. Items that fail often are the biggest contributor to slowed progress. Reducing their priority is one way of remedying this (and possibly helping your memory by inducing the spacing effect or reducing interference)
- at article import, high priority will ensure early reading, however, once you get to reading, you may want to deprioritize and only give high priority to important extracts! You can set the priority for the entire article and split it all in one go (while reading or by an auto-split). It is however much easier to split the article incrementally as you progress with reading, and only then spread the priorities of all children elements with Priority : Spread on the browser processing menu. Once you finish reading the article, some of the generated extracts and clozes will be given higher priority (as per your decision), while most elements will get their priority set automatically on the basis of article's priority. This will usually be a priority that is higher than deserved. Hence Priority : Spread is recommended each time you complete reading an article
- it makes sense to give new clozes a very high priority to make sure they are reviewed at least once to "hatch" in your memory. However, once the first repetition ends with success and your future recall at longer intervals is a bit more likely, you can provide a more honest priority, which is usually lower than when first prioritizing extracts for the sake of generating cloze deletions. If you are still worried about possible forgetting, you can wait with establishing the honest priority until the 3rd or 4th review. The longer you wait, the greater the chance you will forget something truly important in the meantime.
- If you hesitate between a lower priority and a higher priority, a lower priority is nearly always better! (due to the priority bias that is likely to crowd your learning process)
- If you skip some of your daily repetition sessions, item protection will drop (as indicated by Priority protection in Analysis : Use). If you do not prioritize well, item protection will drop as well. The best way to keep item protection high is to learn regularly, learn a lot, and provide honest priority evaluations
- Your measured forgetting index will increase if you are honest with priorities in an overloaded collection. However, it will more honestly reflect your actual knowledge of the material in the collection. To see how forgetting index changes with priority, see Tools : Statistics : Analysis : Graphs : Forgetting index vs. Priority
- If you manually change the interval, element priorities will change. If you shorten the interval, the priority will automatically increase. If you delay the next repetition, the priority will drop.
- Priority protection can at times drop by a huge margin in a single day. This is not a reason to worry, as long as this does not become a trend. For example, if you discover a set of clozes whose priority is too low, and you increase that priority in the entire set, all items that have been outstanding, but not at the front of the outstanding queue, will affect the item protection measurement on the next day. This is a one-day phenomenon. However, you will also notice a destructive impact of massive up-prioritizations. It is easy to say "that branch is very important", and very difficult to undo the damage by indiscriminate change of priorities.
- If you are curious which postponed item reduced your item protection (Priority protection), choose View : Recent : Postponed, choose Child : Items on the browser menu, and sort by priority (e.g. by clicking the Prior column heading). The offending item should land on top. It will tell how your item protection dropped. This is the highest priority item missed on the previous day of learning.
- A simple way to get the feel of the relative importance of an article is to look at the After and Before fields in the priority dialog (Alt+P). For example, it may be tempting to give ahigh priority to an article that vexes your curiosity. However, you may need to pause and ask if the story of Scott Peterson is as important to your knowledge as an article about the causes of autism. If you happen to watch a documentary about Peterson (e.g. in your incremental video collection), you may temporarily accept a higher priority to that article, and use Priority : Spread on the browser processing menu to deprioritize all extracts after you finish watching the program. This way you will let various pieces of information dovetail together, which will benefit long-term retention.
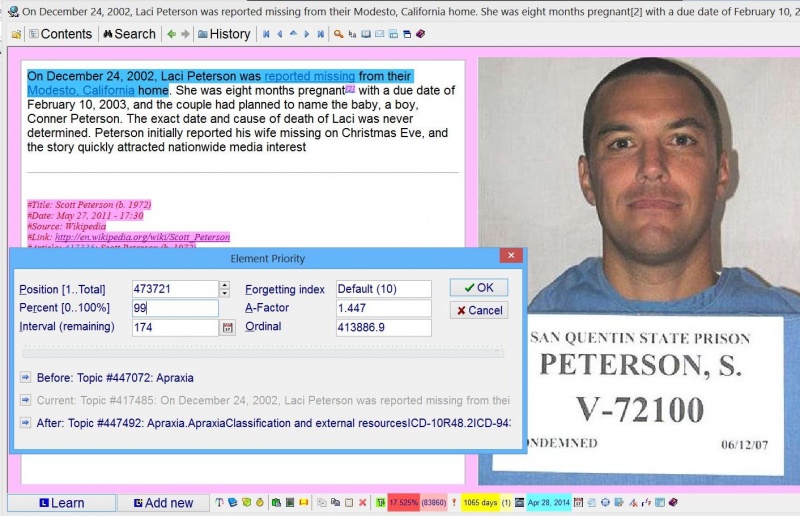
- The main difference between lifelong learning and school learning is that schools artificially distort the priority of the learning material. Before an exam, a section of material must receive high priority and high processing, while after the exam, the same material must be realistically re-assessed (which usually means a manifold decrease in priority and heavy dilution of the overload).


Priority queue: Summary
- SuperMemo uses a priority queue in which all elements are arranged by their priority in the learning process
- The highest priority is 0%. The lowest priority is 100%
- SuperMemo can auto-postpone the excess of the outstanding material
- SuperMemo uses the priority queue to auto-sort the learning queue. This means that each day, you will first be served high-priority elements
- Priority queue softens the need for moderation in learning; however, it does not entirely solve the priority bias (i.e. your tendency to attach excessive priority to new material)
- SuperMemo automates moderation by strictly limiting the inflow of topics into the learning process
- SuperMemo helps you combat the priority bias by a user-defined degree of randomization in sorting the learning queue
- In a heavily overloaded learning process, the retention of low-priority material will drop substantially
- Deprioritization of elements is painful, but it is a key to your long-term success. Due to the priority bias, lower priority is nearly always better than a higher priority!
- Tools : Statistics : Analysis : Use : Priority protection : Items can be used to inspect the degree of item protection in an overloaded learning process
- Tools : Statistics : Statistics : Protection can be used to inspect one's progress in processing top priority material on a given day
- Priority queue will help you increase the volume of learning, and still increase the retention of top-priority material
Visual learning
Visual learning: Incremental picture processing and learning
A picture is worth a thousand words. This ageless maxim expresses a well-known fact taken from neuroscience: we have an extremely effective visual memory systems that should be used often to complement the memorysystems used for more abstract knowledge that is the chief target of incremental reading. Pictures have a great mnemonic power and should be used profusely to illustrate the learning material. SuperMemo implements picture operations that should make your work with pictures easier than ever as long as you master the basic skills of visual learning.
Visual learning is an equivalent of incremental reading, but is used to master material represented as pictures. In visual learning, you get a series of pictures as your input, and produce lasting memories of the most important pictures, picture fragments, or annotations associated with pictures.
The tools and techniques of visual learning can also be used to learn texts that are available only as pictures (e.g. book snapshots, read-only PDF screen prints, paper notes, etc.). A scanner or a digital camera can be used to take pictures of the notes. However, text searches cannot be executed unless high-quality OCR software is used or picture texts are annotated manually.
Adding pictures to SuperMemo
Pasting pictures from the clipboard
To paste a picture to SuperMemo, copy it first to the clipboard. In SuperMemo, go to the element that is to display the picture. Make sure you are in the presentation mode (e.g. press Esc a few times if you are not sure). Press Shift+Insert or Ctrl+V to paste the picture or click the Paste button (![]() ) on the learnbar.
) on the learnbar.
If the element does not have image components, SuperMemo will shift the existing components to the left to make space for the picture. Otherwise it will reuse the first empty image component, or tile existing images to add a new one in the space devoted to pictures. Depending on your category template settings, and the existence of picture templates associated with your default template, SuperMemo may also prompt you Do you want to use a picture template?
If your template has a picture hosting equivalent, you will be asked if the picture template should be used. The picture template should have the same name as the currently applied template with the suffix Picture or P. For example, if the applied template is called Physics, and you want picture templates to be suggested automatically for elements with the Physics template, name the picture template Physics Picture or PhysicsP in the template registry (e.g. available via Search : Templates on the main menu).
A newly pasted picture is always added to the image registry and becomes linked to the image component that hosts it.

Figure: Several pictures of a naked mole rat have been pasted to the presented element. After economizing space for the first picture, SuperMemo will tile the remaining pictures in the available area on the right of the element window (or in the relevant picture area if a custom-made picture template is applied when pasting). Note that you can accomplish the same effect with Import web pages if you select Page of images.
Importing pictures from a local drive
A single picture
If your picture resides on the hard disk:
- right-click over the image component you want to import the picture to,
- choose File : Import file,
- choose the picture from the disk.
A folder of pictures
If you want to import an entire album of pictures stored in a specific folder on your hard disk, use File : Import : Files and folders, and choose the folder to import. All files (including non-picture files) will be imported to separate elements that will form a tree structure in the contents window analogous to the structure of imported folders (i.e. the selected folder and its subfolders (if any)). Note that you can automatically delete imported pictures from the import folder. Use this option with caution. To accelerate the import, there is no undo for import delete. Moreover, if you choose a wrong folder, the process may take ages and you will end up with a collection peppered with, for example, EXE applications.
Importing pictures from the web
You can import pictures from the web. You can either search for pictures (e.g. with Google Images), or you can import pictures that are included in the articles that you process with incremental reading.
Import from the web
If you find some pictures on the net, open them in the Internet Explorer, and use Shift+Ctrl+A to import them to SuperMemo. See Import web pages for details. Download progress for large pictures is displayed on the status bar.
The import template is determined as follows:
- Default topic template for the current category is used if it contains at least one text component (for picture descriptions) and one image component (for the picture)
- Predefined Article Picture template is used if it still exists (you can redefine this template or save your own template under this name as long as it contains the required text and image components)
- In all other cases, template-less element is created with text and image components as required by the import procedure

Figure: 21 Keke Palmer's pictures are found in opened Internet Explorer tabs/windows and selected for import as Page of images. Note that when pictures are imported from the web in this mode they get automatically tiled.
Import from articles included in SuperMemo
Once you import an article from the net, all its pictures will still reside on the net. If you would like to make sure you do not lose those pictures (e.g. when the article is pulled off), or if you want the pictures to show up in all extracts and clozes produced in incremental reading, use Ctrl+F8 (Download images on the HTML component menu).
Figure: Two images from the article Atherosclerosis (previously imported to SuperMemo) are selected for import (i.e. localizing into the image registry and illustrating the article). The currently selected picture on the list is called "Endo dysfunction Athero.PNG (source=http://upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Endo_dysfunction_Athero.PNG/109px-Endo_dysfunction_Athero.PNG)". This picture is previewed on the right. SuperMemo displays its original name, size and the original web address. Note that you can change the name of the picture. The new name will be used to locate the picture in the image registry. Once the selected pictures get inserted in the element, they will be used to illustrate all extracts and cloze deletions produced from this article in the process of incremental reading.
Pictures as answers
If you want a picture to be part of the answer (i.e. not visible at question time), check Answer on the image component menu.
Tiling pictures
If you are not happy with the way your pictures are tiled, you can rearrange the components and re-tile your pictures. To rearrange components, set them in the dragging mode first. You can switch a component to the dragging mode with Alt+click (click twice until the component becomes gray and draggable). You can switch all the components to the dragging mode with the Switch mode button (![]() ) on the learnbar, with double Alt+click over an empty element area, over the navigation bar, or over the bottom bar of the element window. Once in the dragging mode, components can be moved around with the mouse.
) on the learnbar, with double Alt+click over an empty element area, over the navigation bar, or over the bottom bar of the element window. Once in the dragging mode, components can be moved around with the mouse.
To tile components, set the to-be-tiled components in the dragging mode, and choose Tile components in the Commander (Ctrl+Enter), or Components : Tile components (Shift+Alt+T) on the element menu. Component tiling assistance will help you arrange the components into the optimum set of rows and columns. Components will be tiled into the rectangle determined by the topmost, bottommost, rightmost and leftmost edges of all the components selected for tiling. Positions of all other components are not taken into consideration. Note that once you change either Rows or Columns you need to press Enter in order to recalculate the other parameter and to update the preview grid.
To choose components to tile, you can also press Ctrl+E to set all components in the editing mode, and return non-tile components to the presentation mode with double or triple Alt+click. Finally, you can just check or uncheck the components on the list displayed right before they are to be tiled.

Figure: 17 Didier Drogba's pictures are being tiled with the assistance of the Tile arrangement tool. You can use this tool to easily determine in how many rows and columns you want to arrange the pictures available in the current element.
Big pictures
Zooming, slicing, trimming, and cropping pictures
Some pictures are too big to be effectively used in learning. They carry too much information. In some cases you will want to focus on the important part of the picture, in other cases you will just want to discard unnecessary information.
For example, when learning political geography, you might import a huge map of Africa to SuperMemo. However, for individual items, you might want to limit the displayed portion of the picture to a single country with its direct neighbors.

Figure: The unzoomed picture of the African political map used to illustrate elements related to Africa. You can see an element related to the assassination of the President Habyarimana extracted from the article about the history of Rwanda originally imported from Wikipedia. The element is illustrated with the political map of Africa on the right (the map is neither zoomed nor trimmed; just stretched proportionally within the image component).

Figure: The picture of the African political map zoomed in on Rwanda to illustrate to an item about the assassination of the President Habyarimana in 1994. In the picture above, you can see a cloze deletion produced from the History of Rwanda article. In this element, however, the African political map is zoomed in on Rwanda (and the neighboring nations). The original picture is zoomed in without cropping the original picture file. Zoomed pictures are marked with a border, which is colored bright lime in zoom&trim mode and red in the display mode. If you do not crop the picture, it will remain unchanged (whether zoomed or unzoomed) in all elements that use it (including other extracts from the History of Rwanda article).
To display only a small portion of a picture in a given element, enter the zoom&trim mode by Alt+clicking the picture. You can now use several operations to zoom in onto the interesting portion of the picture:
- Zoom: click the middle mouse button to zoom in on an interesting portion of the picture
- Unzoom: Shift+click the middle button to unzoom
- Move: Shift+drag the zoomed picture to adjust the displayed area
- Trim: Ctrl+swipe unwanted edges of the picture:
- press Ctrl,
- point to the edge that is to be cut out,
- press down the mouse, and
- move it in the direction of the area that is to be cut.
- Select: drag and select to mark the area that is to be displayed in the picture:
- point to one corner of the desired area,
- press down the left mouse button,
- drag the selection marquee to select a portion of the picture, and
- release the mouse button to slice the picture.
Once you zoom in onto the interesting area, press Esc to quit the zoom&trim mode. You will be given the following options:

- Leave the picture zoomed/trimmed without changing the file. This will display the selected portion of the picture in the current element without changing the original picture file that might be used elsewhere in its entirety or with other portions zoomed onto. This is the default option. When you revisit the element, it will still be marked with a zoom border. However, the lime-colored border of the zoom&trim mode will be replaced with a red border, which indicates a zoomed picture in the display mode.
- Permanently cut/crop the zoomed/trimmed image file. This will replace the original picture file with a smaller picture representing the zoomed-in area).
- Unzoom/undo. This will cancel the changes introduced in the zoom&trim mode.
- Cancel. This does nothing (i.e. you will stay in the zoom&trim mode)
If you leave the element without terminating the zoom&trim mode, the picture will remained zoomed, and the original picture file will remain unchanged (i.e. as if you chose the default option when terminating the zoom&trim mode with Esc)
Picture processing options
You can quickly access picture processing options with Shift+Ctrl+F8. If you have more than one picture in the element, start from clicking the one that you want to process.

The following picture processing options are available:
- Zoom - enter the zoom&trim mode (you can enter this mode even faster with Alt+click over the image)
- Unzoom - unzoom the zoomed picture, i.e. show the entire original picture
- Extract (Alt+X) - extract portion of a picture into a new element. SuperMemo (1) duplicates the element, (2) clones the image, and (3) enters the trim&zoom mode. This will, in essence, produce an extract in the same way as you produce a text extract in incremental reading. Once you finish selecting or trimming the extract, press Esc, and choose Permanently cut/crop the zoomed/trimmed image file. If you do not want the original picture to be marked with extract boundaries, respond with No to Replace picture with a JPG image? After executing Extract, you will have two elements: one with the original picture with extract boundaries marked (or unchanged, if you do not want to modify the picture), and the new element with a new picture, which is a portion of the original picture (see: example)
- Crop - delete invisible portions of the picture from the original file (i.e. reduce its size to the visible portion of the zoomed picture). This will affect all elements that use this picture
- Clone - create a copy of a picture in the image registry (this way, cropping a picture or marking it with extracted portions will not affect other elements that use the same picture in the collection)
- Compress - reduce the size of the picture by choosing a new size; compression will produce a file that is no greater than the size you choose. In most cases, you can compress a 2-5 MB picture to 200-500 kB without noticing the difference in quality
- Scale - reduce the size of the picture by reducing its quality, increasing compression, reducing its dimensions, trimming its edges, etc
Extracting pictures from larger pictures
Extracting picture fragments from larger pictures is analogous to extracting fragments of texts in incremental reading. They can also be executed with the same shortcut Alt+X. The Alt+X will work for a picture extract if (1) no text is selected, and (2) there is a picture available in the element.
When you press Alt+X on a picture, the element will be duplicated (as is the case with text extracts), the picture will be cloned (i.e. a duplicate of its original will be created), and you will enter the zoom&trim mode. Once you zoom onto a portion of the picture, press Esc to crop the extract and return to the original element (from which the extract has been made). SuperMemo will ask you: Replace picture with a JPG image? Note that the above sequence is slightly different from the one you use in extracting texts: you press Alt+X and generate a new element before you select a picture fragment.

If you choose Yes, the original big picture will be marked with a bright yellow-red extract rectangle (marking the area that has been extracted). If extract rectangles overlap, you may wish to answerNo to make sure the extracts themselves do not get obscured by previous extract borders; however, in such cases you will need to remember which portions of the picture have already been extracted. This means that in those cases you will rather need to do all your extracts one after another (i.e. while you keep your progress fresh in memory).
Example of a picture extract
This large picture of a stunning Freiburg panorama is too large to view details in SuperMemo. You can therefore extract all interesting portions for independent review. After producing an extract, yellow-red border can indicate which portions of the picture have already been processed:
.jpg)
Individual extracts are small enough to view details without zooming:
.jpg)
Instead of extracting portions of the panorama, you might equally well just zoom in. However, if you extract only a tiny portion of pictures from a very large image, extracts will consume less disk space because the portions of the picture you are not interested in, will be discarded.
Cloze for pictures
To create graphic deletion tests (occlusion tests), do the following:
- Choose Add new (Alt+A) to add a new item
- Apply the Occlusion template (e.g. press Ctrl+Shift+M and choose "Occlusion")
- Paste the image prepared for the graphic test (e.g. Ctrl+V)
- Use Ctrl+T a few times to select the occlusion rectangle
- Size the rectangle so that to occlude the portion that makes the question
- Type in the question (e.g. "What portion of the image is covered by the red rectangle?")
- Type in the answer
- Use Shift+Alt+L to test your new occlusion test
- Use Edit : Duplicate (Alt+D) on the element menu to generate more tests with the same picture
- Remember that for best scaling results you need to keep your template/element Scaled and your picture Stretch : Filled (without those two, resizing the element will move the rectangle relative to the image and reveal the answer)
Incremental video
What is incremental video?
Incremental video is a technique for learning or watching video recordings with the view to forming lasting memories of the material viewed. Incremental video makes it possible to learn from multiple sources of video without neglecting any one of them. The processing of individual sources proceeds in parallel and time allocations for individual sources depend on student's priorities. Incremental video is to video as incremental reading is to learning from electronic texts. In incremental video, it is the user who decides which portions of a video are important to remember. Those portions are part of a standard learning process known from other applications of SuperMemo. Each portion of the video forms a separate topic that is reviewed at increasing intervals. Despite working with thousands of videos, you do not ever need to feel lost, ever get bored, or ever miss a valuable scene. You can also use SuperMemo as your video or music jukebox. You can work with individual videos for mere seconds. Just as much as is needed to set the new viewing point, determine the priority and determine the date of the next viewing. This way, you can process dozens of videos daily and work with thousands of videos in parallel. You shall feel overwhelmed with the richness of YouTube never again!
On the face of it, incremental video looks like channel-zapping on steroids. However, it is also a powerful learning technique that makes it easy to process thousands of videos in parallel without getting lost. It also makes it easy to learn individual video scenes for long-term retention. It can be used to learn sports, master musical instruments, understand biology, or learn fun dialogs in your favorite movies. Individual videos are processed in small portions. Viewing can be resumed at any time at the last viewing position. Best pieces are preserved for repeat viewing. Individual videos are prioritized and served on a daily basis in manageable portions in order of priority.
Although, incremental video can roughly be implemented with a pair of digital video recorders working in tandem, only SuperMemo provides a bona fide implementation with the whole set of incremental learning tools. SuperMemo makes it possible to learn from standard video files (e.g. MP4). It also makes it easy to learn from YouTube videos. At the moment of writing these words, no other software in the world provides the incremental video learning toolset.

Figure: Exemplary screenshot from an incremental video process in SuperMemo.
Incremental video with YouTube
Incremental video in SuperMemo can use YouTube videos. You can capitalize on the video streaming power of YouTube and speed up SuperMemo even though you may suffer video lags on weaker Internet connections. You will also dramatically save on hard disk space. Videos are notorious hogs of space, your YouTube collections will take a tiny fraction of space needed for video based on local files. YouTube collection will actually take less space than incremental reading collections while carrying lots of learning power. If your network is slow or frequently down, you should take comfort in the fact that this situation is likely to change for the better as networks improve worldwide all the time (and this progress is not likely to be slowed soon). Last but not least, SuperMemo will hopefully encourage you to upload your own educational videos to YouTube and thus share them with others.
Incremental video with video files
Incremental video in SuperMemo can use video files from your local drive. You do not need to limit your learning to videos available from YouTube that can be notoriously volatile (e.g. with accounts closed for copyright violations, embedding blocked by account holders, videos made private, etc.). You are not limited by the need to access to the Internet. You can also process private videos.
Using incremental video with local files requires computers with significant processing power. On a strong PC, processing video files is fast and painless. It may be slower on weaker PCs. Your collections may grow to be terabytes large, which is the main disadvantage of keeping files local. Make sure you have a big dedicated external drive for a backup of your material. The time-scale resolution of local videos is higher than that of YouTube-based videos, which are limited to setting Start and Stop points in increments of 1 second. With local files, you can review fragments that last milliseconds. You can review your best football move at nauseam. Moreover, with local files, you can work when disconnected from the net.
Incremental video can use local files in several video formats (incl. MP4, WMV, AVI, MOV, Mpeg, and more). Not all video formats are supported. Before you commit to SuperMemo, give it a try to see if your files can be processed or converted to acceptable format with third party tools.
Incremental video in SuperMemo
SuperMemo is a pioneer in implementing versatile incremental video. For those who are familiar with incremental reading (also pioneered by SuperMemo), incremental video is an analogous technique. Instead of text extracts, you generate video extracts, i.e. portions of a larger video. Video extracts are viewed repeatedly in increasing intervals (as it is thecase with other pieces of information in SuperMemo).
Individual videos and their extracts are treated in the same way as all other topic elements and enter the learning process according to the rules that are known from incremental reading. Currently, only passive review of extracts is supported. There is no equivalent of cloze deletion in incremental video. However, you can use videos as answers if you choose so.

Incremental video with YouTube: Outline
This is how you work with incremental video in SuperMemo:
- open your favorite YouTube videos in Internet Explorer
- choose YouTube import option to import videos to SuperMemo (e.g. Shift+Ctrl+Y)
- use Learn to process individual videos
- use Start and Stop buttons to mark interesting scenes
- use Extract to generate new elements with scenes marked with Start and Stop
- use learning tools in SuperMemo to prioritize, schedule, and organize videos and video extracts

Figure: An extract from the "Pirates of Silicon Valley" (yellow in the template is used to differentiate between extracts and parent videos). SuperMemo will play the fragment between the start time of 8 min. 43 sec. and the stop time of 9 min 8 sec. (of the original YouTube video). The checkmark near the Test button indicates that the fragment should be played in a loop. On the right, you can see the description of the video imported from the YouTube database. In pink, you can see references generated automatically (when importing videos with Edit : Import web pages : YouTube (Shift+Ctrl+Y)). Both the video description and the references are propagated from the original video element to all video extracts.
Importing videos from YouTube
To import videos for incremental learning do the following:
- open YouTube videos in Internet Explorer
- choose one of the following:
- press Shift+Ctrl+Y
- Import YouTube videos on the learnbar (right-click over the Import articles button)
- Edit : Import web pages : YouTube from the main menu
- optionally, set import options (e.g. which videos to import, video priority, name of the import node in the knowledge tree, etc.)
- click Import
If you see a video embedded in a webpage choose Copy video URL on the YouTube video context menu (right click), and paste the video to SuperMemo with Ctrl+N (as you would paste anywebpage).
If you receive a video forward from SuperMemo, you can copy its code from the body of the mail and paste it to your collection with Ctrl+N (as you would paste any text or article).

Viewing YouTube videos
Use Learn in the same way as when learning with SuperMemo. The videos start automatically. When you get bored or need to watch other videos, press Start to mark the point from which you will resume the video next time you see it. If you find an important fragment that you would like to learn or view again, press Start at the beginning of the fragment, and Stop at the end of the fragment. Use Test to view the fragment again. Press Extract if you would like to create a new fragment that should take part in the learning process as a separate element.
You can use Mark and Resume to set a bookmark that will not affect the point from which video starts (e.g. when preparing an extract).
You can generate extracts without interrupting the viewing process. Extract elements are generated only when you move on to the next element or when you press Alt+X.
If you get the same videos over and over again, and you would like to get some variety independent of video priority, use Learn : Sorting : Sorting criteria and increase Randomization (move the thumb from Prioritized topics towards Randomized topics, i.e. to the right).
If you are not sure how to handle the incremental learning process, incremental reading is a good introduction to understanding incremental video.
Forwarding video fragments to friends
If you forward a YouTube element in SuperMemo via e-mail to others, it will include the link and start:stop boundaries of the video. Forwarded videos can be viewed in a web browser or directly in SuperMemo with Start and Stop buttons set to make sure only the recommended fragment plays.
Your e-mail will look similar to this one:
Please have a look at this YouTube video:http://www.youtube.com/watch?v=WOzNAiOR7fY?rel=0&t=49&end=79See the fragment from 00:49 to 01:19.If you are using SuperMemo 15 or later you can also:(1) select this code (e.g. triple click):{SuperMemoYouTube:WOzNAiOR7fY,00:49,01:19,00:00}(2) copy the code to clipboard (e.g. Ctrl+C)(3) use Ctrl+N to paste the code to SuperMemo and play the recommended fragment.Sender ID: SuperMemo Research==================================================#Subject: Marissa Mayer: Why Google Maps is far ahead on Android#Author: Jean-Louis Nguyen#Date: Feb 27, 2013, Wed, 00:18 (updated: Feb 27, 2013, Wed, 00:18)#Source: YouTube#Comment: Uploaded 2012-09-27 (2669 views)#Link: http://www.youtube.com/watch?v=WOzNAiOR7fY#Collection: YOUTUBE [Element=6667]#Generated: Aug 01, 2013, Thu, 12:13:00#Software: SuperMemo 16 (Build 16.0, Aug 01, 2013)Exemplary YouTube videos
Incremental video is a video equivalent of incremental reading. However, there are many things you may wish to learn that are best mastered with video and cannot be substituted with reading. The list is truly endless. However, here are just a few examples taken from YouTube to give you the first sense of why incremental video is an important component of incremental learning:
- learn a foreign language with the help of movies, speeches, lectures, etc.
- learn recent history with archive footage
- explore the student's video paradise: Khan Academy
- learn to play a musical instrument using video tutorial produced by experts or best artists
- learn to play along or sing along your favorite songs
- use Mike Phelps videos to learn how to swim butterfly
- recover from injuries by learning physiotherapeutic exercises
- watch movies incrementally
- listen to your favorite music
- watch historic sports events
- watch video lectures from reputable universities
- enjoy or learn the best jokes or comedy pieces by Leno, Connan, Jon Stewart, and others
- master speechmaking with videos of MLK, JFK, Reagan, or Obama
- seek motivation from Tony Robbins or other self-help gurus
- learn to cook
- relive memorable moments in the lives of your family and friends
- learn physiology, geology, physics, or history, wherever a video explanation is needed
- learn sign language, volleyball, soccer, etc.
Incremental video with video files: Outline
This is how you work with video files using incremental video in SuperMemo:
- put your video files into a single empty folder
- use File : Import : Files and folders to import the contents of that folder to SuperMemo
- use Learn to process individual videos
- use Start and End buttons to mark interesting scenes
- use Extract to generate new elements with scenes marked with Start and End
- use learning tools of SuperMemo to prioritize, schedule, and organize videos and video extracts
Figure: An extract from a boxing training video (yellow color in the template is used to differentiate between extracts and parent videos). SuperMemo will play the fragment between the start time at 151.28 sec. and the end time at 157.61 sec. (of the original video). On the right, you can see the import parameters of the video, which should, ideally be converted to annotations that will help you locate the video and assist in the training (or learning).
Video deletion
Incremental video is currently most suited for processing video or audio material passively with the most interesting portions extracted for passive review as topics. Currently you cannot "cloze delete" portions of video or audio files with a keystroke, however, you can, easily use video extracts as answers to text questions, or video questions. For that purpose, mark your sound or video components with the Answer attribute. You can also define templates that will make that process easier.
Viewing video files and learning
Use Learn in the same way as when learning with SuperMemo. The videos start automatically if you have AutoPlay checked on the element menu. When you get bored or need to watch other videos, press Start (on the Extractor panel). Start marks the point from which you will resume the video next time you see it. If you find an important fragment that you would like to learn or view again, pressStart at the beginning of the fragment, and End at the end of the fragment. Use Test to view the fragment again. Press Extract if you would like to create a new element with the extracted fragment that should take part in the learning process.
If you get the same videos over and over again, and you would like to get some variety (even though the videos might be of top priority), use Learn : Sorting : Sorting criteria and increase Randomization (move the thumb from Prioritized topics towards Randomized topics).
If you are not sure how to handle the incremental learning process, incremental reading is a good introduction to understanding incremental video.
Exemplary video files
For a list of exemplary videos that may be used in incremental learning see: Exemplary YouTube videos.
Note that not all video material may be learned with the help of YouTube. There might be copyright or privacy issues. There is also one pesky problem with YouTube that can ruin any long-term learning process: videos can be pulled at any minute (unless you upload them yourself for public viewing with full respect to copyright). Last but not least, the time resolution of local file incremental video is higher that that of YouTube-based video. You can set your starting point with millisecond precision (as opposed to 1 second resolution of YouTube videos).
Material that might work better with files on your local hard disk include:
- lectures or interviews that are available for download but not published at YouTube
- lectures or interviews that are available for download and you wish to keep local (e.g. to ensure speed, precision, persistence, or offline viewing)
- copyrighted material from iTunes
- movies
- home video
- language courses
- all other files that you want to learn but cannot upload to YouTube (or just you do not want to be bothered with the hassle)
Hints: Incremental video
Hints: Incremental video with YouTube
- Define "YouTube Extract" template to have it used for extracts from YouTube videos (as long as you use the "YouTube" template). Otherwise, "YouTube" template will be used with the background changed to yellow. The simplest approach is to save your "YouTube" template with the new name ("YouTube Extract") and then redefine it (e.g. by changing the element color). Differentiating videos from their extracts (e.g. by color) is important for your strategies in optimizing the learning process.
- Incremental video is less incremental than incremental reading. Incremental video was designed on the assumption that, unlike in incremental reading, you go through the main body of the video linearly. This is because of multiple context problems when splitting videos into smaller portions and watching them in unpredictable order. This way, once you make an extract, the assumption is, you do not come back to the once viewed portion of the video as it is already part of the extract. When you return to process the video, you start from the last position extracted or marked with Start. In other words, as you do not extract without viewing, there should be little needed for sub-extracts
Hints: Incremental video with local files
- Define "Video Extract" template to have your template used for extracts. Otherwise, The "Video" template will be used with the background changed to yellow. The simplest approach is to save your "Video" template with the new name ("Video Extract") and then redefine it (e.g. by changing the element color to the desired extract color). Color differentiation is important for optimizing the strategies in processing videos
- If you want your extracts to run in an infinite loop, make sure you check Continuous in your video extract template
- There isn't much performance penalty for processing large video files. You can import whole DVDs too and process them incrementally
- Not all file formats are supported, however, most formats can easily be converted to MP4 (e.g. with XMedia Recode).
- Note that some MP4 files may not work correctly in SuperMemo. Please test a trial SuperMemo before you make a major commitment
Problems with YouTube-based incremental video
Here are some problems you may encounter when learning with YouTube-based incremental video:
- YouTube videos can be removed at any time. They can also have embedding disabled. This is a major problem for the present implementation of incremental video in SuperMemo. There are no API tools that could allow of legal localization of YouTube contents (at the moment of writing). However, the problem mostly affects copyrighted material that shows up on YouTube illegally (e.g. movies, music, etc.). Occasionally, video authors themselves remove content. This should never be a problem though if you use your own videos. Hopefully, there will be more and more persistent content uploaded for educational purposes.
- Alt+Left arrow shortcut is used by Internet Explorer to return to the previously visited page. As a result, it also works like an Undo for your Start:Stop setting. To return to the previous page in SuperMemo, use the Back button (
 ) on the navigation bar
) on the navigation bar - it may happen that your network is down or the Internet is slow when working with YouTube videos. You may therefore prefer to first experiment with a dedicated incremental video collection to learn how to handle videos and prevent interruptions to learning in cases of network problems. You can always stop working with your incremental video collection, return to your regular learning, and resume video learning when the network returns to normal functionality
- if you would like to use SuperMemo as your YouTube jukebox, you should also keep music videos in a single collection (or mark them all with a specific keyword for fast subset learning). You can later hide your jukebox collection in the system tray. Your jukebox will play only the selected fragments of individual videos in order of priority as specified in your sorting criteria. As in incremental reading, using intervals and priorities is a good remedy against getting bored with a given song or video
- videos cannot be played in SuperMemo if their embedding is blocked (you will see a message Embedding Disabled By Request). Those videos you can only watch on YouTube. This means that those videos are pretty useless in your incremental video learning; however, you can still use prioritization and scheduling tools to choose which videos should be played in which sequence and on which day. Note also that many of those videos are uploaded multiple times by various users, and you only need to search for an alternative that can be embedded
- for technical reasons, some videos (roughly one in a thousand) cannot be watched incrementally (they will ignore extracts and always play in their entirety); some can show large rounding errors for extract precision (around 10% of videos can only be watched in large increments). This problem seems to have largely been resolved after 2010.
- some videos may display loading errors on first entry. Right-click over the video and choose Refresh to reload (or use Alt+Left arrow followed by Alt+Right arrow to revisit the element). If the error reoccurs, use the link in references on the right to visit the original page at YouTube. This problem seems to have largely been resolved with the newer versions of YouTube API
- there are bugs in YouTube API, flash player, and Internet Explorer that can interfere with your work. Your script can use
version=2orversion=3of the player. Both have ups and downs. Version 2 tends to hang on very short video pieces that play over and over again (due to a memory leak in Flash software). Version 3 may hang for 10-20 seconds when loading videos preceded with advertising (without actually showing the advertising).
Your own incremental video script
Videos are handled with the help of YouTube Player API in HTML components using a small JavaScript program. When you first run SuperMemo, it writes this script into a file stored in the [BIN] subfolder of the folder in which you installed SuperMemo. The name of the file is yt.htm. If you know JavaScript, you can substitute your own incremental video script in that file (e.g. to change the layout, size of buttons, or even add new functions for processing videos). Here are the only components of the script that you need to preserve:
- the order of
INPUTfields (these are used by SuperMemo to collect extract boundaries) -
SELECTandOPTIONfields for generating extracts -
INPUTfield with YouTube video ID substituted by SuperMemo (id="videoid") -
INPUTfield that determines the position of video start and end (id="startvideoat"andid="stopvideoat")(must be "0:00:00")
The most important change you may wish to introduce is to decide between version=2 and version=3 of the player. Both have their bugs and disadvantages. For more see Player Version Issues. The version of the player you choose will be picked by default in all your YouTube elements. However, you can change the default with Player version from the context menu of the Edit file button on the learnbar.
If you would like to share your own script with others, you can upload it to SuperMemoPedia.
Incremental audio
Incremental audio is analogous to incremental video. You can use incremental video to process audio information from YouTube, or you can use a dedicated extractor bar in sound components to import and process sound files (e.g. MP3, WMA, WAV, etc.).
Incremental audio with sound files
Working with sound files is the same as working with video files. The only difference is that you will use sound components instead of video components. Those will be created for you automatically at import with File : Import : Files and folders (available from the main menu). For details see: Incremental video with video files: Outline.
Incremental audio with YouTube
See: Incremental video with YouTube: Outline to find out how to use YouTube material in incremental audio process.
Incremental mail processing
E-mail in SuperMemo: Introduction
SuperMemo makes it easy to resolve mail overload without neglecting the most important channels of communication.
In addition to prioritizing and managing the communication, SuperMemo helps you:
- incorporate e-mail communication into your learning process (e.g. forwarding and discussing important pieces of knowledge)
- incorporate learning into your e-mail communication (e.g. memorizing important facts related to your mail communication)
To fully use e-mail functionality in SuperMemo you will need Windows (Live) Mail (or any other e-mail client that support EML) or MS Outlook 2000 or later. At the very minimum, MAPI compatible mail would be needed for sending SuperMemo elements or objects via mail.
Here are the most important uses of e-mail in SuperMemo:
- Sending learning data to others: If you encounter valuable information in incremental learning (or when processing mail), you can send it to your colleagues, friends, partners or family with a single click for inspiration or further discussion. For example, while reading an article about decoding human genome, you might find out that Craig Venter of Celera comes from a Mormon family and that his father was eventually excommunicated. You can send such a note (or the whole article) from SuperMemo to your Mormon friend with a click of a button.
- Using incremental learning tools to process mail: Incremental reading is a powerful tool that helps you prioritize, schedule, and process mail. As a result, you may decide that instead of using your mail software, it is more convenient and rational to use SuperMemo to read and respond to your e-mail. Users of Windows (Live) Mail or MS Outlook can now import all their mail to SuperMemo with a keystroke. If you receive more mail than you are able to effectively process, you can prioritize it with incremental learning tools. You will immediately process only the most important pieces and proceed with others according to their priority in proportion of available time. As in the learning process, rescheduling and sorting happens in the background, so that you never lose sleep over delaying a reply or being slow with processing excess mail.
- Using mail material in incremental learning: You may also incorporate snippets of mail in your learning process. You can treat most valuable pieces of e-mail as articles to read. If you receive highly inspirational messages, you may want to introduce it into incremental learning and memorize its portions to ensure long-term benefit. In other words, your mail may not only prompt action, but may also be used in learning to keep your memory up-to-date with things you care about. This way you can also learn from materials sent from others, esp. if those materials come in small portions extracted from an incremental learning process conducted by other people. You can also comment or respond to individual portions of the processed mail. You can do it while reading or when new ideas come to your mind upon review. You can use this process for the purpose of creativity (e.g. reviewing an inspiring idea or information in different contexts) or for the purpose of recall (e.g. trying to remember the university major of your cousin).
Sending learning data to others
To send an element via e-mail, click the E-mail button (![]() ) on the navigation bar or press Shift+Ctrl+E. Element texts will be sent in the e-mail body (if you wish so), while formatted texts, pictures, and other files will be sent as attachments. You could also send texts without attachments by using E-mail : Texts or E-mail : Q&A on the element menu.
) on the navigation bar or press Shift+Ctrl+E. Element texts will be sent in the e-mail body (if you wish so), while formatted texts, pictures, and other files will be sent as attachments. You could also send texts without attachments by using E-mail : Texts or E-mail : Q&A on the element menu.
To send a selected fragment of an article via e-mail, right-click over the selection (to open the component menu) and choose Reading : E-mail (Shift+Ctrl+E). Alternatively, you can also click the E-mail button (![]() ) on the Read toolbar. Note: SuperMemo sends only plain text mail, and formatted texts can only be sent as attachments.
) on the Read toolbar. Note: SuperMemo sends only plain text mail, and formatted texts can only be sent as attachments.
To send a fragment of YouTube video, mark the fragment with Start and Stop buttons and click the E-mail button (![]() ) on the navigation bar.
) on the navigation bar.
Importing mail to SuperMemo
Importing mail from Windows (Live) Mail
To import mail from Windows (Live) Mail, follow these steps:
- (optionally) Preview mail in your Windows (Live) Mail Inbox:
- delete spam,
- process one-liners (mail that requires only short answers and is not worth archiving),
- categorize mail by moving it to separate folders (e.g. Business, Family, Pictures, Learning, etc.), forward mail that may be processed by others, etc.
- (optionally) Move mail that is to be processed incrementally in a given collection to a dedicated import folder. Use a top level import folder as SuperMemo only lists top folders on the pick-list (e.g. Inbox, Sent items, Business as opposed to Inbox/Business). Nested folders need to be picked manually (with Change the import folder).
- You can import mail from any folder by following these steps:
- Choose Edit : Import mail (Shift+F4) on the main menu, or Import mail from the import context menu on the learnbar
- (when importing for the first time) select Windows (Live) Mail as your mail application
- (when importing for the first time) pick the account you want to import mail from
- (when importing for the first time) SuperMemo will ask you to specify the folder with e-mails to import

Figure: A dialog with the list of top level folders to import mail from (displayed when importing mail for the first time)
- Pressing OK will import all mail to SuperMemo. E-mail attachments will be imported as separate components of the appropriate type. Binary components will be used to import attachments in formats that are not supported by SuperMemo (e.g. PDF, URL, ZIP, MSG, MMP, XLS, DOC, MPA, WMA, etc.). Mail that has been imported previously will be skipped (as long as it is located in the same import folder as used in the prior import)

Figure: Progress bar displayed while importing mail to SuperMemo
Note that you will only repeat steps 2-4 when changing the e-mail client or the import folder.
Importing mail from MS Outlook
To import mail from MS Outlook, do what follows:
- (optionally) Preview mail in the Outlook Inbox
- (optionally) Move mail that is to be processed incrementally in a given collection to a dedicated import folder. A disadvantage of importing directly from Outlook Inbox is that new mail may arrive during the import process
- You can import the content of your Inbox (or any other Outlook mail folder) by choosing Edit : Import mail (Shift+F4) on the main menu. Choose Import All to import all mail to SuperMemo and move it to an archive folder in MS Outlook (see the picture below). E-mail attachments will be imported as separate components of the appropriate type. Binary components will be used to import attachments in formats that are not supported by SuperMemo (e.g. PDF, URL, ZIP, MSG, MMP, XLS, DOC, MPA, etc.)

Importing mail from other applications
Importing mail from a folder
If your mail application keeps mail on a local disk in the EML format, you can import it by pointing to the folder from which the mail should be imported:
- choose Edit : Import mail (Shift+F4) from the main menu
- choose Change the mailing program (if you used other methods previously, answer with No to whatever confirmation SuperMemo demands)
- choose Other applications
- when SuperMemo asks "Please point to the folder where you keep the mail that you want to import", point to the folder where EML files reside
Importing mail by copy&paste
If you do not use Windows (Live) Mail, nor MS Outlook, nor any other suitable application from where you can import mail, you can manually import individual pieces of mail.
To paste a piece of e-mail for incremental reading, select the text in the e-mail body, copy this text to the clipboard and choose E-Mail: Paste in the Commander (Ctrl+Enter, E). You can also use Edit : Add to category : E-mail from the main menu.
If you want to respond to the original sender while incrementally reading his or her e-mail, paste the e-mail along with its header information (date, return address, subject, etc.).
For example, in Thunderbird:
- click Forward,
- select the entire body of the message (e.g. with Ctrl+A),
- copy the selected text to the clipboard (e.g. with Ctrl+C or Ctrl+Ins)
- switch to SuperMemo, and choose E-Mail: Paste in the Commander. This will automatically convert your e-mail to plain text (to save space, remove read-only attributes, etc.). It will also format the header for you. If you want to retain some formatting, select the text and re-paste the formatted fragment
Reading mail incrementally
You can process e-mail incrementally in SuperMemo in a process analogous to incremental reading.

Here are the pros and the cons:
Advantages
- recall of important facts: if you learn new things from e-mail sent by others, you can easily introduce the most valuable pieces into the learning process (via standard Extract or Alt+X). Those pieces will be reviewed as other pieces of knowledge in SuperMemo. If you decide to respond to a given inspirational fragment, the sender address will automatically be used when you click the E-mail button (
 ) on the navigation bar. Incremental processing will help you remember names, contexts, events, and facts far better than when using other methods. You will not experience mental chaos caused by an overcrowded Inbox
) on the navigation bar. Incremental processing will help you remember names, contexts, events, and facts far better than when using other methods. You will not experience mental chaos caused by an overcrowded Inbox - prioritization: if you get more e-mail material than you are able to process, you can use incremental learning tools for prioritizing mail and its fragments. One of the greatest strengths of incremental learning is its unique system for efficiently determining the priority of the reading material with the help of the priority queue. Remember to politely inform everyone about your e-mail processing system. Otherwise you may easily be accused of acting as an e-mail black hole
- handling overflow: you can use Postpone and other rescheduling tools to resolve the excessive inflow of information without damage to your selected priority criteria. If you work in a team, it is a great idea to delegate some of your work; however, not all work can be delegated. Additionally, if you delegate, you do not learn from e-mail that you delegate. To answer the latter problem, you can choose a solution in the middle: delegate e-mail jobs and process inflowing pieces with the tools of incremental learning
Disadvantages
- splintering e-mail: some people dislike splintered responses. They prefer to have their e-mail analyzed as a whole and responded to as a whole (preferrably within an hour :). As an act of kindness, try to remember people's preferences and do not use incremental e-mail processing (too much) on those who do not like it
- incremental approach is not transitive: incremental e-mail processing shows the greatest power for longer pieces of mail, article forwards, etc. For very short e-mail messages, incremental e-mail processing delivers less value per unit time. Because incremental mail processing leads to short communication bursts, it undermines its own power when used at both ends of the communication channel. However, even if you communicate in short sentences (i.e. without SuperMemo), keep the record of mail in your collection for Search and review
Incremental strategy for mail processing
Incremental learning can be employed in mail processing.
The strategy will be different when processing mail from family or friends. It will be different when processing business mail. It will also be different, and perhaps most effective, when brainstorming over e-mail.
This is an exemplary strategy that might be used in nearly all imaginable applications:
Review stage
- (optionally) Preview mail in your Inbox: delete spam, process one-liners (mail that requires only short answers and is not worth archiving), categorize mail by moving it to separate folders (e.g. Business, Family, Pictures, Learning, Music, etc.), forward mail that may be processed by others, etc.
- import mail from a selected import folder (e.g. with Shift+F4). You may import different categories of mail to different collections (e.g. business mail to Mail.kno, while family pictures to Photos.kno)
- prioritize mail. Use Spread priorities to assign a range of priority to the imported subset of mail. Use Alt+P on most important pieces of mail to assign individual priorities. For example, import the bulk in the 3%..6% range, and pick 5-10 most important pieces for higher priorities
Processing stage
- click Learn, and process mail using standard incremental reading tools (extract, re-prioritize, delay, etc.) combined with e-mail options (extract, send/reply, FAQ, article or picture forwards, etc.). As long as you use auto-sort and auto-postpone, your workload should be reasonable and you should always begin from top priority mail. If you have Learn : Sorting : Auto-sort repetitions checked, your mail will be sorted by priority at the beginning of the day. If have Learn : Postpone : Auto-postpone checked, all the mail that you fail to process today will be redistributed into the future
- (optionally) once you run out of time, process some mail without responding to re-prioritize and reschedule the most important pieces manually (rather than leaving them to automatic rescheduling)
Naturally, as with incremental reading, the time you choose to progress through individual stages is important for efficiency. Processing stage should fall into time slots with best alertness and mental performance. Review stage can be done at other times, incl. while multi-tasking. This approach eliminates the instant nature of mail, but makes the entire process more reasonable, esp. if volumes are far beyond manageable. Although many pieces of mail will get substantially delayed (or perhaps even neglected), top-priority mail will be processed in the first order, and damage done by urgency will be less. The above strategy may introduce an inevitable delay of up to 4 days in replying (Day #1 arrival, #2 review, #3 prioritizing, #4 processing); however, in incremental reading, it is always the priority and quality that should come first ahead of speed and urgency. Those pieces that truly cannot wait can be handled at Review stage (if absolutely necessary).
Mail processing tips
- Create a separate collection for e-mail processing (unless you plan to combine e-mail work with standard repetitions)
- Import mail to your e-mail collection with Shift+F4
- Use the priority queue (Alt+P) to prioritize mail
- Use Auto-sort and Auto-postone to resolve overload and prioritize mail automatically
- You can delay individual pieces of mail with Ctrl+Shift+R or Ctrl+J, and change their priority with Alt+P. Use Ctrl+Shift+R on first reading to determine when you want to reply to an e-mail
- SuperMemo picks the earliest [mailto: tag from your e-mail text as the default response addressee. If you would like to send pieces of an article to a selected person, put this tag with the address anywhere in the text. For example: [mailto:johndoe@hotmail.com] (note the square brackets around the tag and the missing space between mailto: and the address). You can specify multiple recipients by separating their names with a semicolon. For example: [mailto:miko;alex] where miko and alex must be defined in your mail program's address book (e.g. Windows Live Mail address book). Adding the [mailto: tag is useful when you want to ask many questions or forward many pieces of a single mail to a single person whose address is complex and is not defined in your address book
- Optionally, add a degree of randomization in your Sorting criteria to prevent "tunnel vision" in processing. For example, we all suffer from a recency bias where recently arrived mail is ranked higher in priority than mail that arrived earlier. Randomization helps to counteract this and similar biases
- In the e-mail review process (initiated with Learn), do the following:
- respond to the most important fragments with E-mail button ()(on the navigation bar)
- schedule less important fragments with Schedule extract (on the Read toolbar)
- pass or delete unimportant fragments, or mark them with Ignore (on the Read toolbar)
- if you jump to the next e-mail element before completing the reading, select the current read-point with Ctrl+F7 (Set read-point)
- if you jump to the next e-mail before completing the reading, optionally, set the new interval with Shift+Ctrl+R
- if mail can be answered later, use Alt+P to reduce its priority
- use Next repetition or Learn to move on to the next piece of mail
- if you complete reading/processing a piece of e-mail, dismiss it with Ctrl+D. You can also use Done on the element menu (Shift+Ctrl+Enter) if you do not plan to archive a given piece of mail
- respond to the most important fragments with E-mail button (
- To change the addressee, paste the new address in place of the old one in the [mailto: ] field. You can use short names (e.g. [mailto:john]) if you have the name in your Address Book. Unfortunately, you will have to paste the address to all splinter fragments generated in incremental reading. You could use Search and Replace (Ctrl+R) for that purpose.
- You can sort mail by interval, date, and more. See: You can sort mail by interval, priority or other criteria
- You can safely remove texts that SuperMemo adds at the end of mail sent
You can sort mail by interval, priority or other criteria
You can sort mail by the length of the interval using the following method:
- choose View : Outstanding
- click Intrv twice at the top of the browser window (to sort from the lowest to the highest intervals)
- choose Tools : Save repetitions (on the browser menu)
You can use this method in e-mail processing in the same way as in the learning process. You can also use this method to sort mail by priority, last review date, etc. It is most convenient to use auto-sort and auto-postpone when processing mail. This way you can be sure that mail of highest priority is scheduled at the beginning of the outstanding queue.
Responding with FAQs
When processing e-mail, you can choose to reply to a question with an FAQ (i.e. a question-answer pair), which can then be stored in your FAQ database. Responding via FAQ is the best way to retain the context of the question, even if you reply with substantial delay.
Use Reading : E-mail FAQ on the component menu or click the FAQ icon on the Read toolbar. After providing the answer, click OK. Optionally, you can reword the question, change the addressee, or the title of the question. You can also have your FAQ saved in HTML or Wiki format for publishing on the web. Note that SuperMemo FAQs are generated with SuperMemo itself. This way, many users can benefit from a reply to a question asked by a single individual.
If you would like to publish your FAQs and change their formatting, modify the following files:
- HTML: [SuperMemo folder]\bin\FAQ_template.htm
- Wiki: [SuperMemo folder]\bin\FAQ_wiki.txt
If you would like to use rich formatting in your FAQs that will be saved to a selected HTML file, toggle the Rich formatting button above the top right corner of the Question text area. You can recognize if the formatting is enabled by blue borders of the Question and Answer fields. You will then be able to use standard keyboard shortcuts for basic formatting (e.g. Ctrl+B to make the currently selected text bold, Ctrl+I to italicize the selected text, etc.)
 |  |
| Figire: Reading : E-mail FAQ on the component menu makes it possible to use the selected text as a question in an FAQ. The FAQ will be sent as a reply, and stored in FAQ files (as HTML and/or Wiki). | |
You can edit your FAQs in the HTML component. Use Split: Insert splitmark in the Commander to separate question from answer with a splitmark (you can use Reading : Split : Insert splitmark on the component menu). You can also use horizontal lines instead of splitmarks (Shift+Alt+H). Once the FAQ is largely complete, select both the question and the answer, and choose Reading : E-mail FAQ from the component menu to polish its HTML, preview it in the WYSIWYG mode, and send it. The FAQ will be sent as a reply, and stored in FAQ files (as HTML and/or Wiki).
Incremental learning in creativity
Incremental learning promotes creativity by association of remote ideas coming in proximate sequences during the learning process. This characteristic of incremental learning can be used for all sorts of creative processes that need a boost from extra knowledge or better recall. The most useful cases of creativity enhanced with incremental learning are:
Incremental problem solving
Incremental learning can assist you in problem solving. It will be particularly useful for the classes of problems with the following properties:
- problems that require processing large amouts of information
- problems that are complex and involve rich branching of the thought process
- problems where working memory becomes a bottleneck
Exemplary problems to solve
- How to fix a pesky problem with a computer?
- How to get rid of a health problem?
- How to move to another country?
- How to get a PhD?
- How to find a culprit in a crime?
- How to answer a difficult question in science?
Many technical issues and bugs in SuperMemo have been solved with incremental problem solving methods. Incremental approach is most suited for complex problems with multiple reasoning paths or requiring rich input of new information. Some bugs in SuperMemo would be particularly intractable due to their complex technical background or difficulty in reproducing the problem. In most severe cases, it makes sense to set up a separate collection for working on a single issue. That collection can later be integrated with larger bodies of knowledge (incl. problem solving knowledge).
How does incremental problem solving work?
Incremental problem solving works as follows:
- collect all information about the problem from all sources available
- write down your own ideas and comments as separate topics
- process all that information with incremental learning techniques
- document all new ideas and new sub-problems that need to be tackled
- import all relevant supplementary material that expands on core ideas
Advantages of incremental problem solving
- always focusing on a small sub-problem that requires further testing or gathering further information
- never missing a single idea in a jungle of criss-crossing inspiration
- never drowning in excess information
- using random association of ideas that boosts creativity
- never getting frustrated by lack of progress in solving the problem. There is always progress in incremental learning, which is reassuring
- never being limited by time constraints. Breaks taken from the work over the problem are not a problem and may actually improve one's chances of coming up with an original idea or the solution. This is due to:
- the spacing effect,
- the novelty effect produced by forgetting, and
- the creative power of memory optimization in sleep
Incremental writing
Incremental writing: Introduction
SuperMemo can be used in the process of creative writing, which combines two processes:
- writing texts and
- creative review and elaboration.
Both processes are based on incremental reading. By analogy to incremental reading, this process is called incremental writing.
The technique of incremental writing was used to compile some of the materials at supermemo.com. Most notably, Good sleep, good learning, good life (2012), and the present Incremental learning (2013) article.
The main difference between traditional writing and incremental writing is that the writer is free to re-organize the material and review it with incremental reading tools.
The main difference between incremental reading and incremental writing is that the "big picture" of the article is built primarily within the collection, and to a lesser extent in the writer's mind. This is suitable for large fact-packed material that is difficult to organize sequentially. In addition, one's own writing may be the source of most input, as opposed to external electronic sources. Incremental writing is also suitable in a compilation of a large body of prior writing, esp. of materials that are repetitive, fact-rich, and often loosely connected. Incremental writing is less useful for texts with a linear line of thought.
Incremental article writing is an open-ended process that can be interrupted at any stage for the article to be exported to as a single document for text-flow rewrites.
Articles written using incremental writing may be particularly suitable for incremental reading. They can be compared to Wikipedia. Crowdsourced Wikipedia is an excellent source for incremental reading due to its incremental growth and solid local context. For the exactly same reasons, materials compiled with incremental writing are highly suitable for incremental reading. They may be bloated and repetitive, however, with incremental reading, they can be prioritized in a rational way. Incremental writing leaves the texts highly granular and the flow of thought is jagged, however, in incremental reading, this is an advantage as all individual articles and subarticles carry sufficient local context to be read independently.
Incremental writing algorithm
The incremental writing algorithm involves the steps presented below. Note, however, that these steps are not executed one after another. All steps are executed incrementally and interleaved in unpredictable sequences that assist the creative process. Unpredictable association of text component is also useful in:
- the development of the logical structure of the text,
- the elimination of contradictions, and
- deleting/reconciling the repetitive material.
The steps involved in incremental writing:
- import all the relevant sources, supplementary material, and supporting knowledge to a single SuperMemo collection
- build a knowledge tree branch at the root of the collection with the desired structure of the article (e.g. name this branch ARTICLE)
- keep all the supplementary material in a separate branch (e.g. TO DO)
- review the ARTICLE branch incrementally, rewrite, improve, and rebuild the tree structure to organize a logical entirety
- add figures, citations, links, etc.
- review the TO DO branch incrementally, copy and paste, or move incrementally processed texts from the TO DO branch to the ARTICLE branch in the tree. Attach snippets to the right branches in the tree. Reschedule and re-prioritize less relevant texts. Delete texts that will be of no use in the final article
- use incremental learning. This implies that you will see articles from ARTICLE and TO DO branches interleaved in unpredictable sequences moderated only by material priority. Always work on the topic that comes next. Do as little as necessary or as much as you like it. You can finish the processed topic in one go, or you can just pass a single sentence and reschedule
- use 'Mercy to re-distribute the excess of the material in manageable portions
- use templates to visually indicate the status of individual portions of the article (e.g. "to write", "to expand", "to rewrite", "to review", "finished", etc.)
- branches that bloat beyond manageability can be treated in the same way as the entire article with subset review, tree reorganization, topic extraction and merging, etc.
- once the job is largely completed, or a deadline looms, export the article branch with Export : Document (on the contents menu), which also automatically adds a table of contents
Incremental writing example #1
Let us consider Good sleep, good learning, good life (2012) as an example. The source material for the article included its decade-old original version, several articles related to sleep and published at supermemo.com, as well as a great deal of basic knowledge taken from various scholarly sources involved in sleep research. Those materials were supplemented with the review of knowledge of sleep from a general knowledge collection compiled by the author. The whole process started from a massive review of the entire material with incremental learning. The construction of a rough outline of the structure of the article proceeded in parallel (in the Contents window). Supplementary materials were imported to fill in or complement individual pieces of knowledge. Figures, annotations, links, and literature citations were also processed incrementally in order of priority. This process quickly resulted in an article bloat, however, this was a bloat of valuable information rather than a bloat of excess writing. Towards the end of the process, individual topics from SuperMemo were imported to a single-page wiki. Some manual wikification was necessary at that step. Alternatively, multi-page wikis, blogs, or plain-HTML sites could have been used as the target of exports from SuperMemo.
Incremental writing example #2
The presented article: Incremental learning (2013) has been compiled from a number of older articles on incremental reading, priority queue, incremental video, visual learning, as well as older articles such as Devouring knowledge, Flow of knowledge in SuperMemo, FAQ pages, SuperMemopedia, etc.
Advantages of incremental writing
The most tangible advantages of incremental writing in SuperMemo are:
- Incremental approach provides for a better focus on a task at hand
- Incremental approach is great for resolving writer's block
- Incremental approach makes it possible to compile new texts from old texts that need resolution of duplicates (e.g. converting two or more versions of older texts into a newer reconciled text)
- Priorities can be used to start from the most important portions of the text. In the end, lowest priority material may never be processed and left neglected or relegated to future versions of the text
- Working with the knowledge tree as opposed to a linear text helps to see the big picture of the entire article, and organize its logic
- Search returns chapters instead of portions of the text. This helps you locate portions of the text that include a keyword that is too frequent to make it useful in ordinary searches (e.g. as in MS Word)
- Search&review is great for minor edits, comparisons, reprioritization, safe search&replace, and more
- Analysis : Use graphs and Workload can be used to chart the progress through the writing material
- Outstanding topics can be sorted by priority to match the circadian cycle (high priorities for high alertness times, low priorities for less productive hours of the day)
- Add to outstanding (or other tools) can be used if a subset of texts needs to be processed more than once in a single day
- Open-ended writing and a "never-ending writing" are easy and natural
- Writing in SuperMemo is fun. It is not just more fun than writing. It is an order of magnitude more fun than traditional writing! Naturally, a high degree of fluency in using SuperMemo toolkit is necessary to experience the fun factor
Fun of writing boosts efficiency
When the fun of writing is gone, the writer's block can ensue. SuperMemo makes writing fun as compared to traditional methods (e.g. writing in a word processor). If you are in no mood to write about one topic today, you might be more inclined to try something else. If you are in no mood for writing anything, tackle some minor clean up jobs. Very often, once you start writing, you get sucked into the effort and the mood returns. A piece of information can trigger new ideas. If it happens in your writing slot, you can instantly write down new ideas. You can write them rough and short. But you need to write them instantly. If you keep waiting, the memory of the inspiration whittles down to just the need to write about a subject! This is how forgetting affects your own ideas! Strike the iron while it's hot. Process inspiration incrementally, and pick the pieces that raise most enthusiasm at any given moment. Those pieces will generate most new creative value.
Creative explosion vs. deadlines
Excess creativity and wish to include valuable information or ideas may cause an unstoppable bloat of writing materials and a never-ending writing loop. It is vital to keep all ideas well prioritized in a TO-DO branch, while the article grows independently in the ARTICLE branch.
Separating TO-DO from ARTICLE is the best solution that makes it easy to cut off the writing process at any stage depending on the writing goals, opportunity costs, and/or deadlines. Whatever is left in the TO-DO branch can be processed later or not at all. As long as strict priorities are applied, loss of value to the main article should be minimized.
Disadvantages of incremental writing
Incremental writing will always be superior over linear writing for a class of non-fiction texts, however, the toolkit is difficult to master, and the strategies are not obvious. This is a new set of techniques that requires a high degree of innovative thinking on the part of the author. This is why we do not expect any significant degree of adoption at the moment. Incremental writing should primarily be considered by authors who are already masters of incremental reading.
Incremental brainstorming
If you combine incremental learning with incremental problem solving and plain old brainstorming, you will arrive at incremental brainstorming. The brainstorming part may be executed face-to-face or over e-mail.
Incremental brainstorming sounds like an oxymoron. Incremental brainstorming has very little to do with "storming", but it makes a very good use of the brain's capacity to build creative associations in fertile knowledge-rich conditions. Incremental brainstorming might be slow, but it can deliver more than plain face-to-face brainstorming. At worst, the outcome will be different, and in creative work, this is always a desirable complementary effect.
In face-to-face brainstorming, two or more brains, preferably with different strengths, specializations, and biases, engage into a fast exchange of ideas, where Idea X from Brain A might generate ideas Y and Z from Brain B, which in turn may cause a chain reaction of creative inspiration in other participating brains. Moreover, brainstorming requires a degree of mental discipline that may be missing in brainstorming with oneself (in one's mind, i.e. without incremental learning). Converting thoughts to speech slows down the thinking, but increases the discipline and may dramatically enhance creative outcomes.
In incremental brainstorming, this process is taken a few steps further. Incremental learning is a form of brainstorming with oneself, as mentioned in the Creativity section, however, it can also be used in remote brainstorming via e-mail. The main tools of remote incremental brainstorming are:
- incremental learning (for processing knowledge),
- incremental mail processing (for processing exchanged ideas), and
- e-mail communication (which may be supplemented by live video).
Incremental brainstorming may be slow, and yet it adds an additional degree of discipline with an archive of written communications. Most of all, it adds more sources of inspiration to the mix. In addition to the participating brains, incremental brainstorming adds inspiration from external sources of knowledge (with non-participating authors providing further inspiration). It also adds from the history of the communication. Due to forgetting, incremental brainstorming makes it possible to brainstorm with one's past self. In other words, the participants of incremental brainstorming include:
- participating brains,
- past versions of participating brains, and
- non-participating authors from the past and the present.
Advantages of incremental brainstorming
The main advantages of incremental brainstorming are:
- wider knowledge: involvement of incremental learning in expanding upon the discussed ideas substantially extends the knowledge used in the creative process. This is a way of adding non-participating brains to the mix
- spacing effect: when brainstorming is slowed down, fading memory traces evoke the spacing effect that may:
- provide for better long-term consolidation of ideas, and
- evoke new creative reasoning pathways in cases where the fading signal needs to be rebuilt via new pathway searches.
- circadian synchronization: participating brains do not need to synchronize their peek performance hours (e.g. when working over different times zones)
- sleep: few people realize the monumental role of sleep in creativity. Neural optimization of memories in sleep works like an automatic creative thinker that is autonomous from the conscious brain even though it feeds on creative processes that occur in waking. Sleep is an organizer of memories and can convert results of brainstorming into new quality. Incremental brainstorming is slower, it may span weeks or months. As such, it employs sleep mechanisms as new autonomous brains in the creative process. Sleep converts the chaos of data into abstract models that yield higher quality reasoning
- balancing attention and creativity: in all creative pursuits, striking the ideal balance between creativity and attention is vital for the ultimate success. Our multitasking society is pretty good at stimulating creativity, however, the same factors that boost creativity have a destructive impact on attention. Incremental brainstorming helps you strike a balance between focused individual work and pulling the team brains together. You can brainstorm without ever interrupting each other
- free from reliance on the coincidence of interests: face-to-face brainstorming often fails due to differing levels of interests or motivations in the participating parties. Moderating face-to-face and adding a bigger dose of incremental brainstorming may be an easy solution. In those cases, most of the workload may shift to a single brain, while still capitalizing on the contribution of the less involved brains
Disadvantages of incremental brainstorming
The main disadvantage of incremental brainstorming is its snail's speed. Naturally, it won't be of much value right before a project's deadline. However, despite the hype speed receives in the media in reference to technological progress, the hardest problems are always solved by collective efforts of multiple brains working over generations. Incremental brainstorming might be less useful in hurrying a new iPad model, but it would be handy in slowly developing or slowly adopting theories like those of Darwin, Mendel, Wegener, and the like.
Future of brainstorming
Incremental brainstorming is not intended to replace face-to-face interactive collaboration. However, it should serve as its rich supplement. It carries all the advantages of incremental learning: creativity, attention, prioritization, meticulousness, consolidation, long-term sustainability based on long-term memories, and more. It requires a lot of training before it brings fruits. Therefore, if problem solving or creative work are vital for your progress, you might consider mastering the following progression of skills: classical SuperMemo (for better memory), incremental reading (for processing text), incremental learning (for overall learning), incremental problem solving (for employing knowledge in solving problems), to finally arrive at incremental brainstorming, i.e. combining incremental learning with classical brainstorming.
User's take: Creative elaboration
Elaborative IR
- I type up the main points of my intended article as a topic in SuperMemo, and then extract them.
- When SuperMemo shows me these fragments, instead of simplifying them (as you would when trying to learn knowledge) I elaborate on them, using my newly learned knowledge from SMIR.
- As my knowledge grows, so does my article, and some of the original extracts can undergo further extracting, in order to elaborate on individual points.
- When I am satisfied, I can collect all the elaborated extracts (located in the children) and bring it back to the parent article, resulting in a well-developed article.
- The problem is that I don't want individual fragments to increase their intervals to 200 or 300 days or more because then I may never finish writing the article. So I have to adjust the intervals manually.
The advantages of a slow and incremental approach to writing articles (and possibly in any other type of creative endevour) are similar to regular SMIR. But because the creation process is in most ways the opposite of the learning process i think that this opposite process may need its own features although i'm not sure what, exactly :)
Anyway, it's just something for you to experiment on if you'd like, if you haven't already.
-- Georgios Zonnios
- Yours is a very healthy and creative way of using incremental reading. This is not exactly "opposite to learning with IR". This is more like a creative way to enhance your recall and understanding. Few things contribute as much to your learning as formulating other people's ideas in your own way. Long and complex articles can often be effectively summarized in 2-3 short sentences and thus contribute far more to your comprehension and long-term recall of the essential knowledge. One thing remains unclear, why should this function be separated from SuperMemo, and what tools are missing from incremental reading toolkit to enhance this process. -- SuperMemo Support
- When writing an article in this style the outcome that I have reached time and time again is a large tree structure (in the Contents window) with the most important information at the leaves (something like the outcome of incremental reading). To turn this information into an "article", one has to go to each leave individually and copy the text, then return to the original parent and paste it in order. Hence, I see the need for a "recomposition" tool that can take all information in the leaves and paste it into a single element using the order specified by the tree structure. -- Georgios Zonnios
- You could:
- open all elements relevant to a given article in the element browser
- Sort the contents of the browser by the order of the knowledge tree
- Export the contents of the browser as a single HTML document (which should make editing of the final article much more efficient)
- You could:
- -- SuperMemo Support
Incremental learning myths
SuperMemo always had to struggle with myths slowing down its popularization. Preventing the reappearance of myths appears to be a never-ending battle. The knowledge about SuperMemo has grown to a substantial volume. Not all users can afford reading dozens of articles. Many users are bound to arrive to the same wrong conclusions independently of others. Some of these myths are rooted in general myths of memory. Others seem to spring from the common sense thinking about learning. Here are some most damaging myths related to spaced repetition, SuperMemo, and incremental learning.
Myth: Many people are successful without using SuperMemo, hence its importance is secondary
Myth: Many people are successful without using SuperMemo, hence its importance is secondary.
Fact: Neither Darwin nor Newton had access to computers, yet computer illiteracy may make today's scientist entirely impotent. Similarly, with a growing importance of knowledge, neglecting the competitive advantage of a wider and stable knowledge will increasingly limit your chances of successful career in science, engineering, medicine, politics, etc. You can live without SuperMemo, but it can definitely raise your learning to a new level.
Myth: Natural mechanisms for selecting important memories are good enough. We do not need a crutch
Myth: Natural mechanisms for selecting important memories are good enough. We do not need a crutch. The evolution produced an effective forgetting mechanism that frees our memory from space-consuming and perhaps irrelevant garbage. This mechanism proved efficient enough to build the amazing human civilization. Consequently, many believe that there cannot be much room for improvement.
Fact: The forgetting mechanism was built in abstraction from our wishes and decisions. It only spares memories that are used frequently enough. Nowadays, we are smart enough to decide on our own which knowledge is vital and which is not. A single peek into a dictionary may often take more time than the lifetime time cost of refreshing the same word in SuperMemo. This is just the least spectacular example. Human history is rich in monumental errors coming from ignorance. NASA's confusion of imperial and metric units cost a lost Mars probe. Confusion of comma with a dot in Fortran, cost a Venus probe. Errors in English communication caused many aerial and maritime catastrophes. A piece of knowledge in surgeon's mind may be worth the life of his patient. Forgetting is too precarious to leave mission-critical knowledge to your brain's own devices. SuperMemo puts you in the driver's seat. You can decide what your remember and what you forget. For more see: Memorization is not needed and Memory has an excellent ability to retain important information
Myth: We cannot improve memory by training
Myth: We cannot improve memory by training. Infinite memory is a popular optimist's myth. A pessimist's myth is that we cannot improve our memory via training. Even William James in his genius book The Principles of Psychology (1890) wrote with certainty that memory does not change unless for the worse (e.g. as a result of aging or disease).
Fact: If considered at a very low synaptic level, memory is indeed quite resistant to improvement. Not only does it seem to change little in the course of healthy life. It is also very similar in its properties across the human population. At the very basic level, synapses of a low-IQ individual are as trainable as that of a genius. They are also not much different from those of a mollusk Aplysia or a fly Drosophila. However, there is more to memory and learning than just a single synapse. The main difference between poor students and geniuses is in their skill to represent information for learning. A genius quickly dismembers information and forms simple models that make thinking easy. Simple models of reality help understand it, process it, and remember it. What William James failed to mention is that a week-long course in mnemonic techniques dramatically increases learning skills for many people. Their molecular or synaptic memory may not improve. What improves is their skill to handle knowledge. Consequently, they can remember more and for longer. Learning is a self-accelerating and self-amplifying process. As such it often leads to miraculous results.
Myth: SuperMemo repetitions take too much time to make it worthwhile
Myth: SuperMemo repetitions take too much time to make it worthwhile. Many users struggle with an increasing load of repetitions and may conclude that the effort is not worth the outcome.
Fact: Just 3 well-selected items memorized per day may produce a better effect than a hundred crammed facts. This means that even a minute per day will make a world of difference, as long as you pay a close attention to what you learn. Not all knowledge is worth the effort of 99% retention. High retention should be reserved only for mission-critical facts and rules. Last but not least: knowledge formulating skills may cut the learning time for beginners by a wide margin. For more see: High retention results in slow learning
Myth: As you add more material to SuperMemo, your repetition loads mount beyond being manageable
Myth: As you add more material to SuperMemo, your repetition loads mount beyond being manageable. No item added to SuperMemo is considered "memorized for good". For that reasons, all items are subject to review sooner or later. There must therefore be an inevitable increase in the cost of repetitions.
Fact: It is true that a large number of outstanding repetitions is the primary excuse for SuperMemo drop-outs. However, computer simulations as well as real-life measurements show that, with the constant daily learning time, the acquisition of new knowledge does not visibly slow down in time except for the very first couple of months. In other words, from a long-term perspective, the acquisition of new knowledge is nearly linear. Older items are repeated less and less frequently leaving room for new material. The exponential nature of this "fading" explains why we can continue with a heavy inflow of new material for decades.
Myth: People differ in the speed of learning, but they all forget at the same speed
Myth: People differ in the speed of learning, but they all forget at the same speed.
Fact: Although there are mutations that might affect the forgetting rate, at the synaptic level, the rate of forgetting is indeed basically the same (independent of how smart you are). However, the same thing that makes people learn faster, helps them forget slower. The key to learning and slow forgetting is representation (i.e. the way knowledge is formulated). If you learn with SuperMemo, you will know that items can be very difficult or very easy. The difficult ones are forgotten much faster and require shorter intervals between repetitions. The key to making items easy is to formulate them well. Moreover, good students will show better performance on the exactly same material. This is because the ultimate test on the formulation of knowledge is not in how it is structured in your learning material, but in the way it is stored in your mind. With massive learning effort, you will gradually improve the way you absorb and represent knowledge in your mind. The fastest student is the one who can instinctively visualize and store knowledge in his mind using imagery that provide minimum-information and maximum-connectivity.
Myth: Hypertext can substitute for memory
Myth: Hypertext can substitute for memory. An amazingly large proportion of the population holds memorization in contempt. Terms "rote memorization", "recitatory rehearsal", "mindless repetition" are used to label any form of memorization or repetition as unintelligent. Seeing the "big picture", "reasoning" and leaving the job of remembering to external hypertext sources are supposed to be viable substitutes.
Fact: Knowledge stored in human memory is associative in nature. In other words, we are able to suddenly combine two known ideas to produce a new quality: an invention. Hypertext references are a poor substitute for associative memory. Two facts stored in human memory can instantly be put together and bring a new idea to life. The same facts stored on the Internet will remain useless until they are pieced together inside a creative mind. A mind rich in knowledge, can produce rich associations upon encountering new information. An empty mind is as useful as a toddler given the power of the Internet in search of a solution. Biological neural networks work in such a way that knowledge is retained in memory only if it is refreshed/reviewed. Learning and repetition are therefore still vital for the progress of mankind. This humorous text explains the importance of memory: It is not just memorizing
Myth: We do not need SuperMemo, all we need is to build an index to knowledge sources
Myth: We do not need SuperMemo, all we need is to build an index to knowledge sources. With multiple on-line sources of knowledge, some people are tempted to believe that all we are supposed to learn is a sort of index to these external sources of knowledge.
Fact: Even "index to knowledge" is subject to forgetting and needs to be maintained via repetition or review. All creative geniuses need knowledge to form new concepts. The extent of this knowledge will vary, but the creative output does depend on the volume of knowledge, its associative nature, and its abstractness (i.e. its relevance in building models).
Index to knowledge
A less extreme version of "memorization is not needed" myth, is that "we only need to remember an index to knowledge". It is true that abstract knowledge and general concepts are most useful. However, this type of knowledge is also subject to forgetting. Moreover, not all knowledge is inferential. To reason about Antarctica, we often need to know that it is cold. We might derive the temperature conclusion from the position of Antarctica on the map, but we need the knowledge of the map, the knowledge of the climate, and the knowledge of the earth's position in reference to the sun. Any kid will admit that it is simpler to just remember that Antarctica is white and cold. In this case, rules are more useful, but facts are easier to remember.
A mere mortal will usually be aware that doughnuts are foods that should better be avoided by people who fear a heart disease. The fact "Doughnuts ain't good for heart" contributes to an average man's knowledge about health. This fact probably does not need SuperMemo. After all, most of us will refresh the knowledge about doughnuts and the heart each time we see a tasty doughnut. The Doughnut Fact contributes also to our index to knowledge. It is enough to jump to Google and type +doughnut +heart to make a good use of this particular entry in our index. The search will help us recover more knowledge about the relationship between doughnuts and the heart.
If we want to enhance our ability to think and conclude about doughnuts and the heart, we might try to remember the following:
- Fact 1: Doughnuts are high in trans fatty acids
- Rule 1: Trans fatty acids in foods tend to lower HDLs (high-density lipoproteins)
- Rule 2: Lower blood HDLs are a major risk factor in cardiovascular disorders (e.g. arteriosclerosis)
There is an advantage to knowing the above facts and rules: upon finding out that French fries are high in trans fatty acids, we will be able to use Rule 1 and Rule 2 to derive a new fact: French fries ain't good for the heart. The awareness of the above rules will increase our reasoning ability. In the terminology of knowledge engineering, we will be able to derive new facts and rules from the existing set of facts and rules. In plain language, we will know more than we have actually learned. We will be able to conclude more. We will become more intelligent (if intelligence was defined as the inferential ability of the human mind).
Yet there is a downside to remembering the trans fat rules. They are not as plain as the Doughnut Fact, and they may not effectively be refreshed upon a sight of a doughnut. Consequently, we may simply forget the link between doughnuts, trans fat, and the heart. This is where SuperMemo comes to play a role. It will help you refresh the trans fat rules. It will minimize the number of reviews in lifetime. In other words, it will help you keep the trans fat rules in your forgetful memory. Thus SuperMemo makes sure that your "index to knowledge" remains intact in your mind.
Myth: In incremental reading, you spend mere seconds reading a topic
Myth: In incremental reading, you spend mere seconds reading a topic.
Fact: The time devoted to a topic depends on your needs. It may be a few seconds (e.g. for a low priority boring subject), or it can be an entire day (e.g. before an exam, or when doing research, or just when following your passions).
Myth: Memorization is not needed
Myth: Memorization is not needed.
Fact: If all students followed the suggestion that memorization is not needed, we would live in a different world. Here is a humorous take on how this world might look like.
- If memorization was not needed, we could travel around the world without learning languages. After all, finding out words in a dictionary takes mere seconds
- If memorization was not needed, students of medicine would not need to cram details of human anatomy and physiology. Instead they would learn to use state-of-the-art expert systems with all answers built in. If you asked: What's up doc? You will hear: I have no idea but wait ... I will check it out on my computer
- If memorization was not needed, all exams such as SAT, GRE, TEOFL, FCE, GCSE, USMLE, etc. would be a great waste of human time and resources. Students should rather come to exams with their link to the web and figure out answers ad hoc. Or they would just read out relevant paragraphs from a textbook
- If memorization was not needed, nobody should poke fun at George Bush Jr. for his lack of knowledge of the heads of state of Chechnya, Taiwan, or Pakistan. After all, he can find those names in seconds on his smartphone. If using external storage was permissible, nobody should blame George W. for mixing up Slovakia with Slovenia, or refer to Kosovars as Kosovarians, East Timorese as East Timorians, or Greeks as Grecians (NB: the word Grecians is considered correct too)
- If memorization was not needed, you could be a rocket scientist at NASA tomorrow! After all, rocket scientists follow well-known rules written in well-known manuals organized in a very well-known manner. If you need to plot the trajectory for Galileo to beam images of Europa back to Earth... no problem... take the Advanced Calculus textbook, figure it out, and send your billion dollar mission on course
The advantage of keeping knowledge in your head as compared to keeping it in external sources can metaphorically be compared to the advantage of going from primary through secondary to university education as opposed to getting a week-long course on digging info from external sources. Nearly all parents seem to prefer to choose the former for their kids.
Myth: High retention results in slow learning
Myth: High retention results in slow learning.
Fact: You need to understand a clear distinction between the two extremes of learning:
- high-retention-low-volume learning (as in early versions of SuperMemo) - in which you make sure you remember 95 or more percent of the studied material
- low-retention-high-volume learning (as in traditional forms of learning) - in which you quickly process large chunks of the material while having to struggle with massive forgetting
Reading books belongs to the low-retention category, while memorizing 10-20 items per day with SuperMemo belongs to the high-retention category. The optimum reading strategy will find the golden mean between these two. You should not give up traditional reading. Neither should you expect to put all your study material into SuperMemo. You should choose a middle-ground strategy. For example, if you consistently spend 90% of your time on reading and 10% of your time on adding most important findings to SuperMemo, your reading speed will actually decline only by some 10%, while the retention of the most important pieces will be as high as programmed in SuperMemo (i.e. usually 95%).
Incremental reading provides you with a precise tool for finding the optimum balance between speed and retention. You will ensure high-retention of the most important pieces of text, while a large proportion of time will be spent reading at speeds comparable or higher than those typical of traditional book reading.
It is worth noting that the learning speed limit in high-retention learning is imposed by your memory. If "memorizing" one-book-per-year sounds like a major disappointment, the roots of this lay in human memory. Our current knowledge of psychophysiology and pharmacology does not provide any means that could allow of breaking beyond those limits. We are left with the choice between high-speed and high-retention. Incremental reading gives you a full hands-on control over finding the optimum balance.
Myth: We are good at remembering important things
Myth: We are good at remembering important things.
Fact: The evolution of the brain proceeds too slowly to have helped us adapt its structures to abstract thinking. What was excellent for survival 200,000 years ago does not suffice to process modern abstract knowledge. Simple computational tasks such as multiplication or division proceed in a shamefully inefficient way in the human mind. After all, early humans did not need to multiply (explicitly and a lot). At the same time, for long, computers found it hard to compete with the visual cortex in pattern recognition and processing. Recognizing the enemy or prey was critical not only for Homo sapiens but also for birds, reptiles, fish or even insects. The only measure of the importance of knowledge our brain synapses have at hand is the pattern of repetition, levels of circulating hormones at the time of exposure, and a limited impact of conscious attentive labeling of information as important at the moment of encoding. Forgetting is needed to optimize knowledge storage; hence we have to forget less important things. Repeated use of the memorized knowledge is a good but far from perfect measure of importance (see: We remember useful things because we use them)
Modern life has changed the hierarchy of value and importance of knowledge. The link between importance and repeated use has been severed. A flashy lingerie billboard we see every morning is not likely to be more important than dozens of volatile facts pertaining to our professional life. Regrettably, there is no circuit in our brain that would let us consciously etch important memories: This is important! I must not forget it! All we can do is to use the trick of reverberation or mnemonic techniques which... still will usually not last long unless we apply spaced repetition as in SuperMemo.
If memory had an excellent ability to retain important information:
- you would not tremble before an exam and confusingly run through the notes to be sure that at the zero hour you won't suffer from a blackout. At the same time, you could easily recall details of a Schwarzenegger movie seen last evening or even weeks before the exam. Clearly, Arnie beats the ups and downs of the Ottoman Empire. And if you think the Ottoman Empire had much greater an impact on humanity than the island shootout in Commando, you are still likely to remember the muscle and the machine gun far better than the timeline of the sultans
- you would never have problems with recalling the date of your mother-in-law's birthday. This is a piece of data that is critical to your marital harmony!
- you should instantly forget the Olympic champions in football in Atlanta 1996 or Munich 1972. After all this might be a classic case of unimportant knowledge. Yet few Africans would forget how Nigeria beat Argentina 4:3 in 1996. Similarly, few Poles would forget the most memorable moment in the history of Polish football: Olympic championship in Munich.
The truth is that we excellently remember only things that are both easy to remember and repeated frequently enough. The brain does not have an internal measure of importance (other than limited volitional control or control via repeated exposure)! Your memory storage ruthlessly deletes your career-critical knowledge with the same ease as it ravages the traces of last year's golf scores or contributing names listed at the end of a boring soap opera. SuperMemo will ensure you remember your mission critical data. What is in, stays in your memory. What is out, is free to go.
Myth: We remember useful things because we use them
Myth: We remember useful things because we use them.
Fact: Not only are we limited in our ability to remember things that we consider important. We cannot even rely on the fact that frequently used memories are remembered better. There are two main reason why frequency of use is not sufficient:
- spacing effect (frequently used memories may be very volatile): if you use things often, e.g. a credit card's pin code, you may surprised by a sudden unexpected lapse of memory! The facts that are used too often or are too obvious, do not challenge the memory system well enough. They are remembered superficially. Any break from use, stress, change of context, or innocent interference from other memories may cause a sudden inability to recall a fact from memory. Even SuperMemo may not help in those cases. Those easy items often grow their intervals fast and cannot prevent the spacing effect.
- tunnel vision: when we rely on frequently used memories, we are slow at expanding our horizons. With spaced repetition, you can quickly grow stable and coherent knowledge into new areas. This expansion is not easy or even possible when relying on frequent use. A conscious intervention is necessary. In an extreme case, you might ask a cat why it does not master mathematics. In a cat's tunnel vision, simple goals lead to a narrow set of factual knowledge that is needed and remembered. A cat will never fly to Mars (on its own).
Opponents of SuperMemo often say: "Whatever knowledge I need, I use often. If I use it often, I do not forget". This is a false conviction. Spacing effect and forgetting are unpredictable. The whole world of useful things escapes your brain on a daily basis. You may say that if need to fly to Mars, you can just read about math tools that you find useful. However, the tool that is useless today might be useful in 5 years, or tomorrow, when you tackle a different problem. You need the whole toolset ready in your mind. The associative power of the extra knowledge just makes you a better problem solver and a stronger thinker.
Tunnel vision effect may be counteracted with extensive reading, however, there is no better way of reading than incremental reading.
History of incremental learning
Incremental learning might be as important to SuperMemo as the original repetition spacing idea. Incremental learning eliminates a number of bottlenecks that limit various stages of knowledge acquisition.
The name incremental reading first appeared in SuperMemo 2000. However, the concept is not new. It originated from combining our natural reading habits with the demands of spaced repetition (SuperMemo). We rarely pick up a book and read it cover-to-cover in one go. At school we often dig through a number textbooks used for different courses. At home we stop reading a book to read a newspaper and then stop reading the newspaper to watch TV. A combination of needs and interests determines how far we go with the reading of an individual text. SuperMemo drives this concept to an extreme by letting you read just one sentence from one chapter from one book and then go on to reading extracts from a thousand books and/or articles. SuperMemo's contribution here is only the management of this multi-source reading process. As for the creative aspect of incremental reading, Niels Bohr is known to have used the power ofintermitted reading and intermitted thinking to maximize his creative output. He would keep dozens of shelves with outlines of ideas. He would return to individual shelves from time to time, esp. if he was inspired by a conversation, thinking, experiment, or reading. He would then keep reading a single shelf, think and ponder, add new notes, etc. Many of those shelves ended up as scientific publications. In that sense, Niels Bohr employed rudimentary incremental reading in his creative work.
The approach used in incremental reading is widely employed by many creative individuals. Even if it is far less formal that incremental reading or even Bohr's approach. Dr Michael Gazzaniga puts it this way: "I think the creative process is directly related to the amount of time one spends mulling something over. I come back and revisit ideas, data, thoughts, all the time. I think this keeps key semantic networks active and then "bingo" an inconsistency or consistency suddenly presents itself to consciousness and the beginnings of a new idea appear".
Here is a brief history of incremental reading:
- Before SuperMemo (1980): The author of SuperMemo and co-author of this incrementally written text, Piotr Wozniak, in his student years, used his own "cross-the-notebook" method of learning. He would go through his paper notes and cross out those he was sure he would remember for the exam. He would read his notes over and over again until all the notes have been crossed out. Each pass was faster as there was less and less to read. That method was nearly a guarantee of excellent exam results. All his lecture notes were covered with crossed out shapes that surrounded pictures and portions of text. This "granular treatment" with "processing attributes" can be thought of as an early inspiration for future incremental reading
- SuperMemo algorithm (1984-1985) - The first ever attempt to measure optimum intervals in learning resulted in the formulation of the SuperMemo method in 1985
- SuperMemo 1.0 (1987) - The birth of SuperMemo is also the birth of computational spaced repetition, i.e. the use of computers in computing optimum intervals in learning
- SuperMemo 2 - SuperMemo 98 (1987-1998) - In the years 1987-1998, users of SuperMemo had only two alternatives in the area of collecting learning material for learning with SuperMemo:
- type it in and formulate it manually, or
- obtain ready-made learning material from a colleague, SuperMemo Library, etc.
- The only way SuperMemo supported learning from electronic sources was via Copy and Paste.
- SuperMemo 99 (1999) made the first step towards efficient reading of electronic articles by introducing reading lists and the first primitive reading tools: Extract and Cloze. Reading lists were prioritized lists of articles to read. Extracts made it possible to split larger articles into smaller portions. Clozes made it possible to convert short sentences into question-answer format by means of cloze deletions (i.e. fill-in-the-blank questions)
- SuperMemo 2000 greatly increased the efficiency of reading by introducing the concept of incremental reading. Incremental reading makes it possible to simultaneously read dozens of articles. Each article is read in small increments fully controlled and prioritized by the user and/or the default learning process. Components of incremental reading introduced in SuperMemo 2000: new A-Factor-based topic repetition scheme (i.e. the learning algorithm), read points, formatting in extracts and in clozes (SuperMemo 99 would ignore formatting), text highlights, source article link, reading toolbar, subset learning, subset postpone, and support for longer articles (SuperMemo 99 was limited to 64K articles)
- SuperMemo 2002 brought incremental reading to a new level. In SuperMemo 2002, incremental reading became the primary learning mode for middle-level and advanced students. SuperMemo 2002 introduced HTML-based incremental reading. For the first time, the user would see little difference between the material in his web browser and in SuperMemo. Other new features introduced by SuperMemo 2002: automatic learning material import from Internet Explorer, mid-interval repetitions that make it possible to review portions of material without damage to the learning process, e.g. before an exam (Algorithm SM-11), search-based learning (i.e. subset learning in which the subset is defined by advanced search tools), dynamically modified A-Factors that fine-tune the priorities without user intervention, postpone wizard that makes reading lists obsolete, separate topic/item statistics and new incremental reading progress statistics, reference labeling, and more.
- SuperMemo 2004 was developed solely with the view to perfecting the tools of incremental reading. The data collected from months of actual incremental reading was instrumental in enhancing the algorithm and the tools. Fine tuning of the modification of topic A-Factors enhanced the optimization of new material review in a heavily overloaded process. New tools included: rich statistics for monitoring and optimizing the learning process, tools for handling excessive delays in review, browsing sources of extracts and clozes, one-key reference labeling, proliferating remote images, easy integration of remote images, and more.
- SuperMemo 2006 made a major step in rationalizing the material overload in incremental learning by introducing the priority queue. SuperMemo 2006 made it easier to import articles from the Internet (esp. from Wikipedia). Material overload could be handled with auto-postpone and auto-sort tools. SuperMemo 2006 simplified importing, arranging, compressing, converting, zooming, and trimming pictures. SuperMemo 2006 could pick any folder on the user's disk and convert all the file archives into material that can be processed incrementally (e.g. article archives, picture archives, family albums, movie clips, documentation files, or assorted archives). SuperMemo 2006 also made it simple to do one-key searches and import of auxiliary learning material on the web with customizable tools (e.g. Google, encyclopedias, dictionaries, picture archives, etc.).
- SuperMemo 2008 extended incremental learning into the areas of pictures, sounds and video with visual learning and YouTube-based incremental video. Imports from the web, esp. Wikipedia and YouTube became simpler with set priorities, references, categories, etc. SuperMemo 2008 also simplified and automated the process of creating source material references.
- SuperMemo 15 (2011) improved web imports (e.g. eliminating article duplicates), splitting articles (e.g. automatic splitting of Wikipedia articles into separate topics), handling references, and more. As SuperMemo 15 provided a full Unicode support, incremental reading in languages other than English became easier.
- SuperMemo 16 (2013) consolidated all incremental learning technologies with the last two missing links: incremental audio and incremental video with video files. It added more tools for Wikipedia imports (e.g. downloading full resolution pictures intead of thumbs, etc.), and visual learning (e.g. global paste). It also made it possible to separate extracts from source articles in child browsers. Dozens of improvements to incremental learning process convert quantity into new quality. For example, SuperMemo 16 added import from Windows (Live) Mail, or a trivial, but extremely useful incremental reading function: Delete before cursor. For a detailed list see: What's new in SuperMemo 16?
A friend recommended incremental reading to me. However, I was instantly turned off by your claim: read thousands of articles at the same time. This is not only impossible, but also sounds like overhyped marketing. All you do in incremental reading is split articles into chunks and read those separately. With this method you lose the big picture. I am afraid you are selling snake oil.