Contents:
- What is incremental reading?
- Advantages of incremental reading
- Five basic skills:
- importing articles
- reading articles
- converting articles to
questions and answers
- repetition and review
- handling
knowledge overflow
- History of incremental reading
- Summary
- FAQ
What is incremental reading?
Incremental reading is a learning technique that makes it possible to
read thousands of articles at the same time without getting lost. Incremental
reading begins with importing articles from
electronic sources, e.g. the Internet. The student then extracts the most
important fragments of individual articles for further review. Extracted
fragments are then converted into questions and answers. These in turn become
subject to systematic review and repetition that maximizes the long-term recall of
the processed texts. The review process is handled by the proven repetition spacing
algorithm known as the SuperMemo method.
Incremental reading converts electronic articles into
durable knowledge in your memory. This conversion requires minimum
keyboard work:
- Input: electronic articles (e.g. collected from the net)
- Output: well-remembered knowledge (quizzed regularly in the
form of questions and answers)
|
Warning! Incremental reading may seem complex at first. However, once you master
it, you will begin a learning process that will surpass your expectations. You
will be surprised with the volume of data your memory can process and
retain!
Advantages of incremental reading:
- Massive learning: possibility of studying a huge
number of subjects at the same time. In traditional reading, one book or
academic subject might need to be completed before studying another. With incremental reading, there is virtually no limit on how
many articles you can study at the same time. Only the availability of time and
your memory capacity will keep massive learning in check
- Creativity (the association bonus): The key to creativity is
an association of remote ideas. By studying
multiple subjects in unpredictable order, you will increase your power to
associate ideas. This will immensely improve
your creativity. Incremental reading may be compared to brainstorming with
yourself
- Understanding (the slot-in factor): One of the
limiting factors in acquiring new knowledge is the barrier of understanding.
All written materials, depending on the reader's knowledge, pose a degree of
difficulty in accurately interpreting their contents. This is particularly
visible in highly specialist scientific papers that use a sophisticated
symbol-rich language. A symbol-rich language is a language that gains
conciseness by the use of highly specialist vocabulary and notational
conventions. For an average
reader, symbol-rich language may exponentially raise the bar of lexical
competence (i.e. knowledge of vocabulary required to gain understanding). Incremental reading makes it
possible to delay the processing of those articles, paragraphs or sentences
that require prior knowledge of concepts that are not known at the moment of
reading. The processing of the learning material will only take place then when the new information
begins to slot in comfortably in the fabric of the reader's knowledge.
Incremental reading makes it possible to tackle the hardest material that
might normally seem unreadable
- Counteracting entropy: The web is a goldmine of information.
However, rarely do we find step-by-step articles that provide all
information and entirely satisfy our needs. In scientific research,
acquiring engineering knowledge, studying a narrow topic of interest, etc.
we are constantly faced with a chaos of disparate and often contradictory
statements. Incremental reading makes it possible to resolve contradictions
and build harmonious models of knowledge on the basis of the information
chaos drawn from the Internet. Incremental reading stochastically
juxtaposes
pieces of information coming from various sources and uses the associative
qualities of human memory to emphasize and then resolve contradiction
- Stresslessness. The information era tends to
overwhelm us with the amount of information we feel compelled to process.
Incremental reading does not require all-or-nothing choices on articles to
read. All-or-nothing choices are stressful! Can I afford to skip this article? For
months I haven't had time to read this article! etc. SuperMemo helps
you prioritize and skip articles partially or transparently. Oftentimes, reading 3% of
an article may provide 50% of its reading value. Reading of articles
may be delayed transparently, i.e. not by stressful procrastination but by a
sheer competition with other pieces of information on the basis of their
priority. In incremental reading, instead of hesitating or procrastinating,
you simply prioritize
- Attention. Incremental reading widely stretches the
span of your attention. You will notice that a single paragraph in
an article may greatly reduce your enthusiasm for reading. If you stumble
against a few frustrating paragraphs, you may gradually develop a dislike of
reading a particular article. You may even become fed up with reading for
the entire evening. Incremental reading makes it possible to immediately move on to
other pieces of information reducing the negative impact of frustration. It also makes it possible to split larger
pieces into less intimidating portions. It allow you to read interesting
bits before reading the boring bits. Those measures dramatically increase
your attention. They also make reading fun. A skilled
incremental reader is likely to develop an addiction to learning with all
related benefits!
- Consolidation. Incremental reading combines the
process of extracting pieces of valuable knowledge with memory
consolidation. By the time you begin a standard spaced repetition process of
well-formulated items (as in classical SuperMemo), your memory will often have already been established
in a favorable context (i.e. context that makes remembering easier). This comes from the need to extract a
given piece of information from a larger body of knowledge that provides
your items with relevant context. This slow process of jelling out
knowledge provides you with an enhanced sense of meaning and applicability
of individual pieces of information. In addition, semantically equivalent
pieces of information may be consolidated in varying contexts adding
additional angles to their associative power. In other words, not only will
you remember better. You will also be able to view the same information from
different perspectives
- Prioritization: In incremental
reading, you can precisely determine the priority of each article,
paragraph, sentence or question. This will maximize the value of your
reading time. This will also reduce the impact of material overflow on
retention. You will always remember the desired proportion of your
top-priority material. While the lesser priority material may suffer more
from the overflow and be remembered less accurately. Priority of articles is
not set in stone. You can modify it manually while reading. The priority
will also change automatically each time you generate article extracts. It
will change if you delay or advance scheduled reading. The priority of
extracts is determined by the priority of articles. The priority of
questions and answers produced from individual sentences is determined by
their parenting extracts. Multiple prioritization tools will help you
effectively deal with massive changes in your learning focus
- Fun. The sense of productivity might be one of the most satisfying
emotions. This is why incremental reading is highly enjoyable. This only
magnifies its powers. To experience the elation of incremental
reading, you may need a few months of focused practice. You will first have
to start with the basic tools and techniques listed in this article. Then
you will need to master knowledge
representation skills. Finally, you will need a couple of months of
heavy-load incremental reading to perfect the details and develop your own
"incremental reading philosophy". Last but not least, incremental
reading requires good language skills, some touch-typing skills, and
patience (SuperMemo will often want you to go against your own intuition). Although the material is
originally imported from electronic sources, it always needs to be molded,
shortened, provided with context clues, restructured for wording and
grammar, etc. The skills involved are not trivial and require practice. In
contrast to classical SuperMemo, where you focus on the review of the old
material, incremental reading interweaves the old with the new. Novelty adds
to the fun and efficiency of learning
| Only SuperMemo makes it possible to implement
incremental reading. Incremental reading requires continual retention of
knowledge. Depending on the volume of knowledge flow in the program, the
interval between reading individual portions of the same article may extend from
days to months and even years. SuperMemo (repetition spacing)
provides the foundation of incremental reading,
which is based on stable memory traces that would not fade between the bursts of
reading |
See also: incremental
reading from user's perspective by Len Budney.
Five basic skills of incremental
reading
Incremental reading requires skills that you will perfect
only with passing time and growing experience. This
overview will help you handle the most basic skills and help you make a start
with incremental reading. The five basic skills are:
- importing articles to
SuperMemo
- reading articles and
decomposing articles into manageable pieces
- converting most important
pieces of knowledge to question-answer material
- review of the material to ensure a good recall
- handling of the unavoidable
overflow of information
Skill 1: Importing articles
To import an important article to SuperMemo, follow these steps:
- Select the imported text in your web browser and copy the selection to
the clipboard (e.g. with Ctrl+C)
- Switch to SuperMemo (e.g. with Alt+Tab)
- In SuperMemo, press Ctrl+Alt+N (this is equivalent to Edit
: Add a new article on the main menu). SuperMemo will create a
new element,
and paste the article. You can also use the paste button
 on the element
toolbar or on the Read toolbar
on the element
toolbar or on the Read toolbar
- Optionally, use Alt+P to define priority of the imported article.
Use the Percent field and remember that 0% is the highest priority,
while 100% is the lowest priority
- Optionally, use Ctrl+J to specify the first
review interval. For example: one day for high priority material or 30 days for low
priority material
Tips:
- Importing articles from Wikipedia
is easiest:
- to import Wikipedia articles opened in Internet Explorer, press Ctrl+Shift+W
(Edit : Add to category : Wikipedia)
- to open and import a specific article, press Ctrl+Shift+W, and
type the article's title
- to import an article on a subject you are reading about, select a
portion of text and press Ctrl+Shift+W
- To quickly import many articles from the web, do the
following: (1) find the articles (e.g. with Google), (2) open them in
Internet Explorer, and (3) in SuperMemo, use Shift+F8 (Edit :
Import web pages)
- To type your own notes in SuperMemo use Alt+N (Edit : Add to category : Note)
- If you would like to store pictures locally on your hard disk (in the
image registry),
and make them proliferate in incremental reading (e.g. show up in all
extracts even if the extracts do not include the picture, etc.), import the
pictures to image components:
- to import pictures included in the article use Ctrl+F8 (Download
images on the component menu), select images
and click Insert
- to import pictures from the web use Copy on the picture in your
Internet browser and then press Shift+Ins
or Ctrl+V in SuperMemo to paste the picture (press Esc a
few times to get to the display mode if the picture does not paste)
- to import many pictures from many articles in Internet Explorer, use Shift+F8
(Edit :
Import web pages) and choose Local images or Page
of images
- All incremental reading in SuperMemo is done using texts formatted as
HTML. To learn more about HTML in SuperMemo, see: HTML
component
Skill 2: Reading articles
Before you start reading articles, you can place the Read toolbar in
an easily accessible location on your screen. The toolbar may be helpful before
you learn to use the keyboard to access all its functions. Choose
Window : Toolbars : Read, place the
toolbar in a convenient place on the screen and press Ctrl+Shift+F5 (to
save the current layout of windows as your default layout). If you do not see the Window menu
read about levels.
This is the Read toolbar:

Here is a simplified algorithm for reading articles:
- Choose an article: Import an article as explained earlier or bring up a previously imported
article with Learn (Ctrl+L)
- Click the article to enter the editing mode in which you
can modify text, select fragments, etc.
- Start reading the article from the top
- Extract texts: If you encounter an interesting text in the article, select
it with the
mouse and choose Reading : Remember extract on the component
menu (or simply press Alt+X). Alternatively, you can click the green T icon on the
Read toolbar (
 )
or on the element toolbar. This
operation will introduce the extracted fragment into the learning process as
an independent mini-article. If you would like to specify the priority of
the new extract, choose Reading : Schedule extract instead
of Remember extract (checked T icon on the Read toolbar)
)
or on the element toolbar. This
operation will introduce the extracted fragment into the learning process as
an independent mini-article. If you would like to specify the priority of
the new extract, choose Reading : Schedule extract instead
of Remember extract (checked T icon on the Read toolbar)
- Optionally, if you read a fragment that seems unimportant, select it (e.g.
with the mouse). Then delete it
(e.g. with the Del key) or mark it with the ignore font. To
mark it with ignore font, choose Reading
: Ignore on the component menu (or click the stop-sign
icon on the Read toolbar)
- Optionally, if the selected fragment does not include all the important reading
context, you will need to add this context manually. For example, if you
are learning history, you may extract the following fragment from an article
about Lincoln: On Sept. 22, 1862, President Lincoln issued the
Emancipation Proclamation, one of the most important messages in the history
of the world. He signed it Jan. 1, 1863. If you would like to extract
the fragment related to signing the Emancipation Proclamation, you will need
to change He to Lincoln and it to Emancipation
Proclamation so that your fragment is understandable: Lincoln
signed the Emancipation Proclamation on Jan. 1, 1863. You can use the Reference
options on the component menu to easily add context to your extracts.
Context added by Reference will be added automatically to all
extracts of a given article. For example, select the text that you want to
serve as the reference title of all extracts and choose Reference : Title
on the component menu (or press Alt+T).
This text will appear at the bottom of all extracts (in reference pink font
by default)
- Mark your last reading point: Once you decide to stop reading the article before its end, mark the last
processed fragment as the read-point (e.g. with Ctrl+F7 or by
choosing Reading : Read-points : Set read-point). Next time
you come back to this same article, SuperMemo will highlight your read-point
and you will be able to resume reading from the point you last stopped
reading the article. To go to your current read point, press F7. If
you forget to set a read-point, SuperMemo will leave a read-point at the
place of your last extract
- Go to the next article: After you finish reading a portion of one article, choose Learn or Next repetition
to proceed with reading other articles. Those buttons are located at the
bottom of the element window. If the selected text
in the article is not empty, it is enough you press Enter to go to
the next article (otherwise, Enter will add a new line in the
article)
- In incremental reading, interrupted reading is a rule, not an exception!
(see advantages above)
With a dose of practice, you will quickly get accustomed to this not-so-natural
state of affairs and learn to appreciate the power of incremental approach.
Use the following criteria to decide when to stop reading the article:
- lack of time: if you still have many articles for review for a given day and your
time is running out, keep your increments shorter. After some time, being in a hurry will be a norm
and you will tend to read only 1-2 paragraphs of each article and dig
deeper only into groundbreaking articles that will powerfully affect your knowledge
- boredom: if the article tends to make you bored, stop
reading. Your attention span is always limited. If your focus is poor, you will benefit more from the
article if you return to it after some break. Go on to reading something
that you are not yet tired of. If SuperMemo schedules the
next review at a date you consider too late, use Ctrl+J
or Ctrl+Shift+R
to adjust the next review date
- lack of understanding: if you feel you need more knowledge before you are able to
understand the article, postpone it (e.g. use Ctrl+J or Ctrl+Shift+R
and schedule
the next review in 100 days or so). If you believe you have already imported
articles with relevant explanatory knowledge, you can search for these
articles (e.g. with Ctrl+F) and review or
advance these articles now (e.g. with browser's Learning
: Review all or Learning : Advance). If you have not yet
imported any explanatory articles, you could do it now (e.g. search the
web and import articles as explained
before). Note that you can select a piece of text in SuperMemo and use Ctrl+F3
to search encyclopedias or dictionaries for more material on a given
subject
- lower priority: read lower priority articles in smaller
portions thus reducing the overall time allocation for the related
subject
- Once you complete reading the article, press Ctrl+Shift+Enter (or Learning
: Done on the element menu). This will dismiss
the article, i.e. remove it from the review process. Done will also
delete the contents of the processed article (without deleting the extracted
material) and delete childless articles (i.e. articles that did not provide
interesting extract or whose extracts have been processed and moved to
various categories). Using Done will greatly
reduce the size your collection and eliminate "dead
hits" when searching through your collection
- If you have an impression that the article is difficult and you would like to
read some fragments later, extract those fragments with Reading : Schedule extract and
provide a review interval that will reflect the time you believe you will be
better equipped to understand the extracted fragment
Warning! Some texts rich in pictures and tables may be handled with
difficulty by SuperMemo. It may be very useful to learn to use HTML filters
(press F6). See: Problems with HTML. Some of
those problems stem from bugs in Internet Explorer that SuperMemo employs to
display and edit HTML. This particularly refers to Internet Explorer 6. It is
therefore highly recommended you install Internet Explorer 7 to make your life
easier. With a dose of patience, you will learn to work around these problems.
Skill 3: Extracting fragments, questions and answers
In the course of traditional reading, we often mark important paragraphs with
a highlighter pen. In SuperMemo,
those paragraphs should be extracted as separate mini-articles (elements) that will later be
used to refresh your memory. Each extracted paragraph or section becomes a new
element that will be subject to the same reading algorithm as discussed
above. Extract important fragments and single sentences with Remember extract (Alt+X).
Remember to add necessary context to make sure that the extracted fragment does
not become meaningless with time. You can use the Reference
options on the component menu
(esp. Alt+Q) to easily add context to your
extracts. For example, select the title of the source article and press Alt+T
(Reference : Title). This way, each extract will be marked by
the title of the source article. If you fail to provide the context, you can use the reference link button
 on the element toolbar to jump to the source article from which the extract had been produced.
on the element toolbar to jump to the source article from which the extract had been produced.
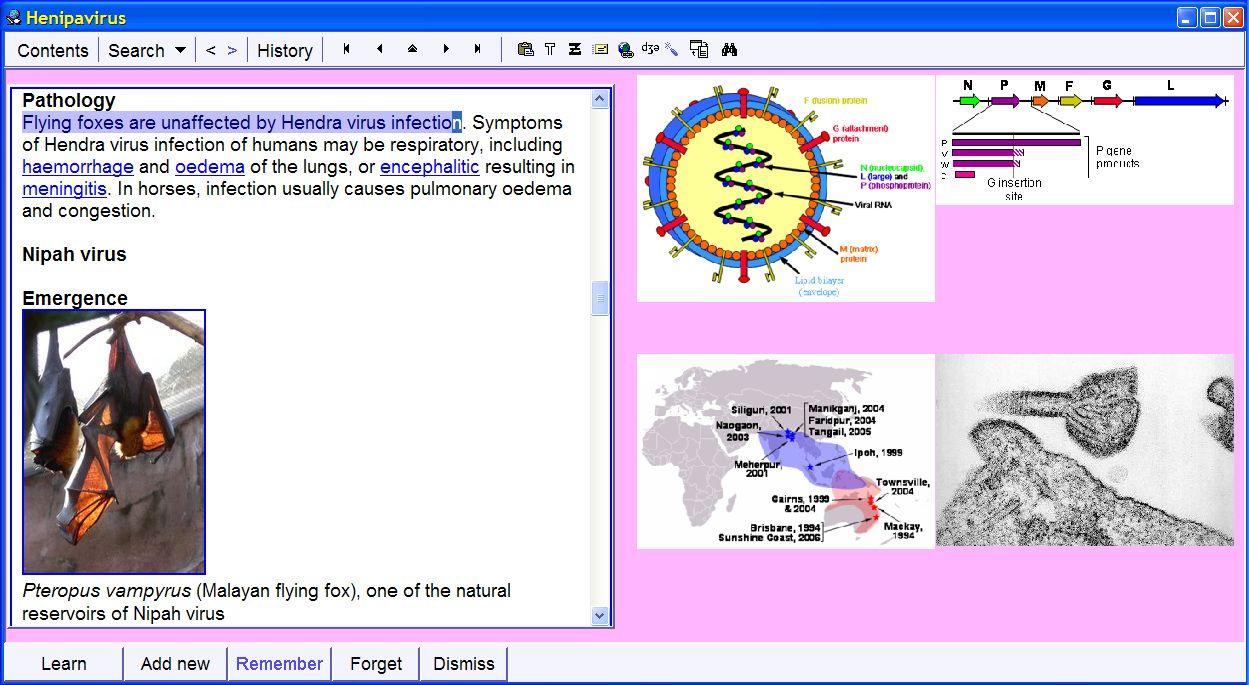
In the picture (click to enlarge): typical snapshot of incremental
reading. While learning about henipavirus, the student extracts the fragment
saying that "flying foxes are unaffected by Hendra virus infection".
The extracted fragment will inherit illustrations placed on the right, as well
as article references (not visible in the picture). The selected 'n' at the
end of the extracted fragment is a read-point. The student can move on to
reading another article by pressing Enter. The pictures on the right are
stored locally in the Image Registry (on the user's hard disk) and can be reused
to illustrate other articles or questions.
SuperMemo will show you that extracting important fragments and
reviewing them at later time will have an excellent impact on your ability to
remember and benefit from your learning material. However, it will also show
that once the time between reviews increases beyond 200-300 days, reading and
re-reading (passive review) will
often result in insufficient recall of the material. For this reason, sooner or
later, you will need to use Remember cloze
by pressing Alt+Z (or clicking the blue Z icon  on the Read toolbar or on the element toolbar). Remember cloze
will
help you convert a sentence
into a series of questions with answers. This way you will move from passive
review to active recall. You do not need to wait until
a paragraph or a sentence become
hard to recall in passive review. For
your most important
material, you can create cloze items immediately after finding a piece of
information that you need to remember well.
on the Read toolbar or on the element toolbar). Remember cloze
will
help you convert a sentence
into a series of questions with answers. This way you will move from passive
review to active recall. You do not need to wait until
a paragraph or a sentence become
hard to recall in passive review. For
your most important
material, you can create cloze items immediately after finding a piece of
information that you need to remember well.
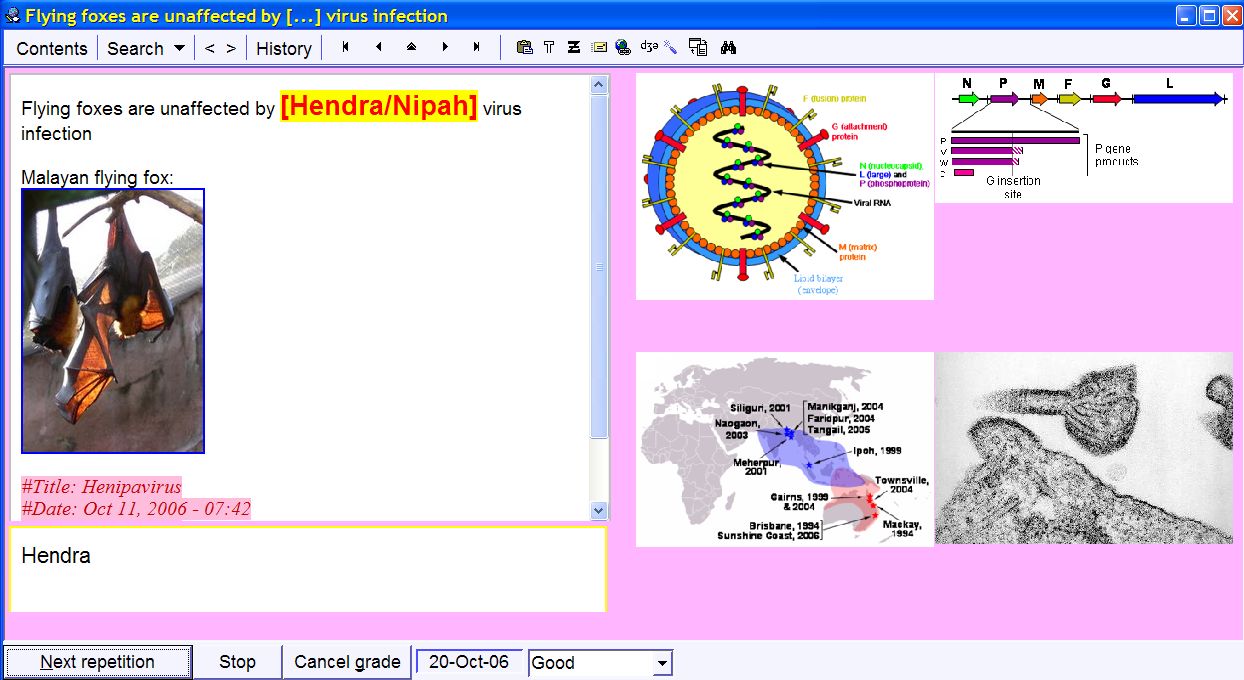
In the picture (click to enlarge): the sentence extracted during
incremental reading (see the previous picture) is converted into a cloze
deletion. (i.e. a type question-answer pair). Pictures from the original
extract have been inherited (on the right). The picture of the bat embedded in
the question remains remote (i.e. it is located on the Internet, not on the
user's hard disk). The student has just graded his answer as Good
and is informed that he will be tested again on the same question on Oct 20,
2006. Pink texts at the bottom of the question are references generated
automatically when importing an article from Wikipedia.
While converting extracts into questions and answers, you should make sure
your questions are simple, clear and carrying the relevant context. For example, if you have extracted the following fragment from your reading
about the history of the Internet:
The Internet was started in 1969 under a contract let by the Advanced
Research Projects Agency (ARPA) which connected four major computers at
universities in the southwestern US (UCLA, Stanford Research Institute, UCSB,
and the University of Utah)
you may discover than when review intervals become long enough, you may not
actually be able to recall the name of the ARPA agency or even forget the year
in which the Internet started. You can then select an important keyword, e.g. 1969,
and use Remember cloze to produce the following question-answer pair:
Question: The Internet was started in [...]
under a contract let by the Advanced Research Projects Agency (ARPA) which
connected four major computers at universities in the southwestern US (UCLA,
Stanford Research Institute, UCSB, and the University of Utah)
Answer: 1969
In the course of learning, you will yet need to polish the above item by
manual editing it to a more compact and understandable form:
Question: The Internet was started in [...](year)
under a contract let by the ARPA agency
Answer: 1969
Or better yet:
Question: The Internet was started in [...](year)
Answer: 1969
As for the precious information "lost" during the editing, it can
(but does not have to) be learned independently with separate questions
generated by Remember cloze.
The mini-editing of questions presented above added the following benefits to the
newly created question-answer pair:
- clearer purpose of the question: the fact that the question is about the year in which the
Internet began is emphasized by using the red-colored (year)
hint
- brevity: by removing superfluous information, you will not waste
time on information that is not likely to be remembered (only actively
recalled material will be remembered for years). You will
answer the question and never focus on which universities were originally
connected by the early Internet. If you believe this information is
important, you will use the original extract to produce more cloze items that will
focus solely on the universities in question by naming them in the answer
field (if you disagree, read: 20
rules of formulating knowledge)
- understandability: "the ARPA agency" phrase
may defy grammar
rules you have learned in primary school, but it is by far more understandable than
just the ARPA. In SuperMemo, understandability is more
important than stiff rules of grammar or spelling!
Remember:
- As a rule, you should use only one-sentence extracts to generate cloze
deletions! Some people hate incremental reading in the beginning. Monster clozes are the
#1 reason for such a negative feeling. By using one-sentence extracts for
cloze deletions, you will save ages on repetition time and eons on time
needed to simplify clozes and converting them to the final form based on the
minimum information principle. See: 20
rules
- Your work on extracting fragments, producing cloze
deletions and editing them should also be incremental. In each review, do only
as much work on the learning material as is necessary! Extracting and editing
in intervals adds additional benefit to learning and is more time-efficient.
Each time you rethink structure and formulation, you hone the representation and
"connectivity" of a given piece of knowledge. In addition, your priorities change as you proceed with
learning. At times, you will over-invest your time in a piece of
knowledge that quickly becomes irrelevant or out-dated. The incremental approach
will reduce the impact of over-investment. Incrementalism should then be
used not only while reading, but also in the follow-up processing
and formulation of knowledge
- To better understand incremental reading at this stage, it is recommended you
read: Topics
vs. Items
Skill 4: Repetition and review
SuperMemo is based on repetition. You
make repetitions of the learned material in order to ensure that your knowledge
retention (i.e. your ability to recall facts) reaches the desired level (usually 95-98%).
In SuperMemo, incrementally processed articles will also be subject
to repetition. We will often use the more intuitive term review in
reference to incrementally processed material; after all, when you resume
reading an article after a certain interval of time, you are not actually repeating
anything. You are simply reading new sections of the same material and
extracting newly acquired wisdom into separate elements with Alt+X (i.e. Remember extract).
The algorithms that determine the timing of (1) repetitions of question-and-answer
material and (2) reviewing reading material are analogous but not identical. Most
importantly, all repetitions and article presentations happen in increasing
intervals by default. In
incremental reading, you will see a constant inflow of new articles into your
collection. Unprocessed material will need to compete with the newly imported material.
Increasing review intervals make sure that your old material fades into lower priority
if it is not processed quickly. The speed of processing will depend
on the availability of your time and the value of the material itself. Articles
that are boring, badly written, less important for your work or growth, will
receive smaller portions of your attention and may go into long review intervals
before you even manage to pass a fraction of the text. That is an inevitable
side effect of a voluminous flow of new information into your collection and
into your memory. However,
intervals and priorities can easily be adjusted. If the priorities change, you can
modify the way you process important articles. At review time, you can either read the
entire article without interruption, or revert it to a shorter interval. You can
manually change its priority (e.g. with Alt+P). You can also use search tools (e.g.
Ctrl+F) to locate
more articles on the subject that you feel you have neglected. You can
reprioritize a bunch of articles by changing their priority. You can shorten
their interval or review them all when needed (see
subset operations in the browser).
The algorithm for reviewing questions and answers (e.g. cloze deletions) is
quite complex and limits your influence on the timing of repetitions
(see: SuperMemo Algorithm). This is to
ensure a high level of knowledge retention, which might be compromised by
manual intervention.
However, the algorithm for determining inter-review intervals in incremental
reading is much simpler and is entirely under your control. Each article
receives a specific priority. The priority determines which articles are
reviewed first and which can be postponed in case you run out of time. Each
article is also assigned a number called the A-Factor that determines how much intervals increase
between subsequent reviews. For example, if A-Factor is 2, review intervals will double
with each
review. Priority and A-Factors are set automatically, but you can change them
manually at any time. Both are determined heuristically on the basis of the length of the
text, the way it is processed, the way it is postponed or advanced, and by many
other factors. Long texts will receive low A-Factors (e.g. 1.1), while short extracts
will receive higher A-Factors (e.g. 1.8). Manually typed texts have higher
priority and lower
A-Factors than automatically imported texts. You can change the priority and
A-Factor of an article by pressing Alt+P. You can also use Ctrl+Shift+Up and Ctrl+Shift+Down to increase
or decrease element's priority. A-Factors associated with items cannot be changed by the
user, as they are a reflection of item difficulty that determines the length of
optimum inter-repetition intervals (see: forgetting index).
You can control the timing of article review by manually adjusting inter-review
intervals. Use Ctrl+J (Reschedule) or Ctrl+Shift+R (Execute
repetition) to determine the date of the next review. Ctrl+J will
increment the current interval, while Ctrl+Shift+R will first execute a
repetition and then set the new interval. For example, if your current interval is 100 and you specify the value of 3 in Reschedule,
your new interval will be 103 and the last repetition date will not change. If
you do the same with Execute repetition, your new interval will be 3 and
the last repetition date will be set to today.
In heavily overloaded incremental reading, you will often want to learn only
a portion of material related to a given subject. For that purpose, read about
the priceless concept of subset learning.
Skill 5: Handling
large volumes of knowledge
In incremental reading, you may quickly import and produce more
learning material than you can effectively process. To make sure that your learning does not
suffer from overload, you should use the priority queue. Using Alt+P
(Learning : Priority : Modify on the element menu),
you can set each element's priority from 0% to 100%. Remember that 0%
corresponds with high priority while 100% with low priority. By default, your
outstanding repetitions will be auto-sorted from high to low priority. This way,
if you fail to complete your daily load of learning, it will only be the lower
priority material that will suffer. Also by default, at the beginning of your
working day (i.e. at your first run of SuperMemo), your outstanding material
from previous days will be be auto-postponed (again with high-priority material
being least affected).
Read an article about the priority queue to learn
more about (1) manual sorting of elements, (2) defining sorting criteria, (3)
turning off auto-sort and auto-postpone, etc.
Read about the postpone dialog to learn about
defining postpone criteria.
To effectively work with material belonging to different subjects of
different priority, you might also want to study the following:
- using templates (providing different branches
with a different look)
- using categories (easily adding knowledge to different
branches of the knowledge tree)
- flow of knowledge in SuperMemo (summary
of skills related to the flow of knowledge between branches and knowledge
pools such as memorized, dismissed, processed, pending, extracts, articles,
etc.)
|
Optional: History of incremental reading
Incremental reading might be as important for SuperMemo as the original
repetition spacing algorithm. Incremental reading eliminates a number of bottlenecks
that limit the first stage of learning: knowledge acquisition.
Older SuperMemos: In the years
1987-1998, users of SuperMemo had only two alternatives in the area of
collecting learning material for learning with SuperMemo: (1) type it in and
formulate it manually or (2) obtain ready-made learning material from
colleagues, SuperMemo Library,
etc. The only way SuperMemo supported learning from electronic sources was
via Copy and Paste
SuperMemo 99 made the first
step towards efficient reading of electronic articles by introducing reading
lists and the first primitive reading tools: extracts and clozes. Reading lists are prioritized lists of articles to
read. Extracts make it possible to split larger articles into smaller portions.
Clozes makes it possible to convert short sentences into question-answer format
by means of cloze deletions
SuperMemo 2000 greatly
increased the
efficiency of reading by introducing the concept of incremental reading.
Incremental reading makes it possible to simultaneously read dozens of articles.
Each article is read in small increments fully controlled and prioritized by the
user and/or the default learning process. Components of incremental reading
introduced in SuperMemo 2000: new A-Factor-based topic repetition scheme (i.e.
learning algorithm), read points, formatting in extracts and in clozes (SuperMemo 99
would ignore formatting), text highlights, source article link,
reading toolbar, subset learning, subset postpone, and
support for longer articles (SuperMemo 99 was limited to 64K articles)
SuperMemo
2002 brought incremental reading to a new level. For SuperMemo
2002, incremental reading become the primary learning mode for middle-level and
advanced students. SuperMemo 2002 introduced HTML-based incremental reading. For
the first time, the user would see little difference between the material in his
web browser and in SuperMemo. Other new features introduced by SuperMemo 2002:
wholesale learning material import from Internet Explorer, mid-interval
repetitions that make it possible to review portions of material without damage
to the learning process (Algorithm SM-11), search-based learning (i.e. subset
learning in which the subset is defined by advanced search tools), dynamically
modified A-Factors that fine-tune the priorities without user intervention,
postpone wizard that makes reading lists obsolete, separate topic/item statistics and
new incremental reading progress statistics, reference labeling, and more
SuperMemo 2004 has
been developed solely with the view to perfecting the tools used in
incremental reading. The data collected from months of actual incremental
reading have been instrumental to enhancing the algorithm and the tools.
Fine tuning of the modification of topic A-Factors enhances the
optimization of new material review in a heavily overloaded
process. New tools include: rich statistics for monitoring and optimizing
the learning process, tools for handling excessive delays in review,
browsing sources of extracts and clozes, one-key reference labeling,
proliferating remote images, easy integration of remote images, and more
SuperMemo 2006 makes a major step in
rationalizing the overload of the learning material in incremental reading
by introducing the priority queue. It makes it easier to import
articles from the Internet (esp. from Wikipedia).
It simplifies importing, arranging,
compressing, converting, zooming and trimming pictures. SuperMemo 2006 can now pick any folder on your hard disk and convert
all your file archives into material that can be processed incrementally
(e.g. article archives, picture archives, family albums, movie clips,
documentation files, or assorted archives). SuperMemo 2006 also makes it
simple to do one-key searches and import of auxiliary learning material
on the web with customizable tools (e.g. Google, encyclopedias,
dictionaries, picture archives, etc.)
|
Summary: