Contents |
Priority queue: Introduction
Human knowledge resources are vast. Our appetite to acquire knowledge is usually exceeding our learning capacity. Incremental learning makes it easy to import huge volumes of knowledge. However, if you cannot effectively process all that imported knowledge, you risk neglecting high priority material by being overwhelmed by subjects that might be relegated to later study. This state of affair was the main reason for introducing priorities in SuperMemo.
In incremental learning, all elements are organized into a sequence determined by their priority. That sequence is called the priority queue. The priority is determined by the importance of the element for a particular student. Elements with lower priorities will be sacrificed first when the student runs out of learning time on a given day. As a result, only high-priority elements will receive the desired level of recall/retention. At any point in time, elements with lower priorities will be more likely to be discovered as forgotten.
During learning, on a given day, elements with highest priorities are processed first.
If you do not finish your learning for a day, do not despair. With the priority queue, you know you did your best and only lower priority material was left behind. Remember to use auto-sort and auto-postpone to make the most of the priority queue.
Can we learn the entire Encyclopedia Britannica?
Early in the learning process, many students do not bother to prioritize their learning material. This attitude is caused by two factors:
- smaller volume of learning early in the process
- false conviction that human memory is vast enough to hold all that dream knowledge
Do you think you are able to memorize the entire Encyclopedia Britannica line by line, fact for fact?
Chances are your answer might be: "I might be too lazy, I might be too busy, but if I had all the time of my day for the job, I would". Or perhaps "I might not, but I have heard of geniuses able to do it! How about Kim Peek?". If you believe the encyclopedia is within the realm of possible, you will soon realize that you desperately need the priority queue to help you overcome a big surprise: our memory is far more limited than you think!
Assuming we do not deal with humans affected with a mutation to their memory system, memorizing Britannica would falsify the theory of SuperMemo which should apply to all healthy adults. In the light of SuperMemo, memorizing Britannica verges on impossible. There are 44 million words in Britannica's 32 volumes. This translates to 6 million SuperMemo items ("human memory bits") assuming the average keyword extraction on information dense texts as 1:7. Assuming a 50-year learning span, we get to 18,250 days and 330 items per day. Assuming optimum representation of knowledge (say Britannica is already "perfectly formulated") you cannot learn faster for a given level of knowledge retention than with SuperMemo (it simply finds the mathematical optimum), and practice shows it is very difficult to sustain more than 100 items per day in the long run with retention around 95%. In other words, for an intelligent man, for perfectly formulated Britannica knowledge, with SuperMemo, you are hardly able to accomplish the goal with your whole life devoted to the task!
Volume vs. retention battle in learning
Incremental reading makes it easy to import large volumes of learning material from the Internet. By default, all imported material enters the learning process. As a result, large volumes of unprocessed information begin to compete for your attention with most important pieces of knowledge that you decided to remember. It is a clash of priorities. On one hand you want to ensure high retention of your mission-critical knowledge (as in classical SuperMemo), on the other, you want to devour more and more new knowledge.
Before SuperMemo, your learning would largely be based on reading and reviewing books or your own notes. With older SuperMemos, you would divide your time between reading (on paper) and repetitions (on the computer). With incremental reading, those competing processes were blended into one. You can read and review concurrently in SuperMemo. However, for the most avid incremental readers, the balance of priority will always dangerously shift in favor of new reading at the cost of the previously acquired knowledge. This comes from human nature. New reading provides instant gratification: "Today, I have learned something new. I am wiser now". Reviewing the material you already know will always feel like a burden. We are always unhappy with our forgetful memory. It always feels that the nature should have given us a natural choice of what to forget and what to remember without the painful effort of reviewing what we already know.
To settle the Volume-vs-Retention battle and to resolve the perpetual clash of priorities, you need better weapons than those made available by older SuperMemos. Before the arrival of the priority queue (2006), you would need to use a complex set of tools to employ massive learning and still protect the retention of your most important knowledge. You would use complex concepts such as A-Factors, forgetting index, subset learning, selective postpones, repetition sorting, etc. These tools were poorly automated and required substantial effort and knowledge on your part. In practice, most incremental readers would have to opt for the simplest prioritization tool: moderation. You could best protect your previous investment in learning by limiting your hunger for knowledge.
Newer SuperMemos use a simple and fully automated mechanism that will help you combine high volumes of reading with high retention of the most important material. This mechanism is based on the concept of the priority queue.
Priority bias in incremental reading
In SuperMemo, each element receives a priority from 0% to 100%. Elements sorted by their priority form the priority queue. An element's priority can also be expressed as its position in the priority queue. The most important element in your collection will sit at Position=1 of the priority queue. The queue is a relative queue. This means that if you, for example, insert an important article at Position=3, all items and articles at higher positions will be shifted by one position up in the queue (i.e. towards lower priority). Thus the element at Position=999 will be pushed to Position=1000, while the element previously sitting at Position=3 will now occupy Position=4. The first two elements in the queue, i.e. Position=1 and Position=2, will not move. The relative nature of the priority queue will help you instantly inspect the current priority of each element in your collection. In earlier versions of SuperMemo, you could observe crowding of elements at high-priority ranks. For example, you could amass a large number of topics with A-Factor=1.01 and be practically unable to prioritize within that group. (A-Factor=1.01 is the lowest possible and would correspond to the highest priority).
The fundamental rationale for using a relative priority queue is the existence of a form of cognitive bias, which we will call the priority bias. This bias makes us always think that the newly found article is extremely important to read. The new article feels so important, because we underestimate the value of all the previously imported articles. Our memory is unable to produce an effective estimate of the importance of the current mass of remembered knowledge. Even less so is it capable of producing a remotely accurate estimate of the importance of the mass of knowledge stored in your incremental reading process (of which, usually, only a tiny fraction is part of your long-term memories). The net effect is that we always underestimate the volume of what we know, the volume of what we keep in incremental reading, and the importance distribution of those volumes of knowledge. This psychological mechanism is also the primary force that works against the universal adoption of SuperMemo. Humans are, by biological design, very weak at estimating the size of their knowledge, the cost of learning, and the power of forgetting. As a result, without an intimate knowledge of what SuperMemo is, individuals rarely ever pause to sense the need to use spaced repetition. This underestimation effect is by far more damaging in the case of incremental learning, which is far more complex and has still not been explained in sufficiently simple and catchy terms.
By employing the priority queue, SuperMemo will help you visualize the priority bias and the process in which large volumes of new material quickly displace the old material from your learning focus. Moreover, SuperMemo highly automates the process in which you can handle material overflow and reconcile high retention with high volumes of learning. Incremental reading has always boasted of its capacity to bring the volume of learning to unprecedented levels. With the priority queue, you can nearly take away the moderation factor and increase the volume of learning even further without undue worry about your hard-earned knowledge.
Priority queue in SuperMemo
You can define the element's priority by:
- pressing Alt+P,
- by clicking the Priority button (
 ) on the learnbar, or
) on the learnbar, or - by choosing Learning : Priority : Modify on the element menu.

To set the element's priority, you can either choose the position of the element in the priority queue (from 1 to Total), or you can choose the percent value (from 0% to 100%). Position=1 corresponds to Percent=0%. Similarly, Position=Total corresponds to Percent=100%.
Low position and low percent mean high priority! This counterintuitive choice was made due to the fact that you are more likely to choose a high priority of 0% or 1% than the low priority of 99% or 100%. Typing the number 2 takes much less time than typing the number 98 (roughly 3-4 times less). As you are likely to set priority manually many times in the course of a single learning session, this counterintuitive choice will save you a lot of typing time over years of learning. In the long run, you will probably be grateful for things set upside down in SuperMemo!
You can use Learning : Priority : Increase on the element menu (Shift+Ctrl+Up arrow) to increase the priority of an element, or Learning : Priority : Decrease (Shift+Ctrl+Down arrow) to decrease it. Those operations also affect the A-Factor of topics.
You can view your entire priority queue with View : Priority queue on the main menu.
Prioritization is difficult before it becomes easy
Everyone struggles with priorities as it is very hard to admit things are not as important as they seem. Of good things, there is a correlation between the hunger for knowledge and creativity. If you struggle with priorities and overflow then it might be a good indicator, as long as you win the battle and learn to prioritize honestly.
To prioritize well, you only need to know that the most important material has priority 0%, while your least important material is 100%. You need to develop a sense for where, in the queue, a piece of information belongs. If you think that everything is "top priority" then you are clearly at the beginning of the road. Pick two items and ask yourself a question: "If I was to forget/delete one, which one would that be?" This exercise will help you see different applications of different items and different value behind the applications. Another exercise is: try to give items as low priority as you can stomach. Can you make it 10%? Would you be hurt if it was 20%? Would the world collapse if it was 66%? With some conscious effort you will realize that you can live without some portions of your knowledge (after all, most people do not use SuperMemo at all and survive ok). Over months of training, you will get better at this.
If you keep peeking at the Protection statistic, you may also realize that sending items beyond your average priority protection will help you clear them from view for a while. This way, if you have created too many cloze deletions that crowd your process, you might actually enjoy sending most of them out of the protected zone, and focus on just one or two that capture the essence of knowledge you are trying to learn.
SuperMemo will not help you much in the prioritization work unless you manually play with intervals (e.g. by saying "this cannot wait 30 days, I must see it in 11"). This tell SuperMemo that the priority must increase slightly.
Sorting repetitions
In a high-volume incremental reading process, you will be served more elements in a single day than you could possibly manage to process in a week (or worse). It is therefore vital that you begin your review process from elements of the highest priority. Low-priority elements might linger in the queue for months or years. High-priority items should be reviewed at the exact time that SuperMemo finds optimum. Only this way will you be able to meet your requested forgetting index criteria for high-priority material while still being under no pressure to limit your hunger for knowledge. In simpler terms, in an overloaded learning process, the SuperMemo promise of "excellent memory" will only apply to your top-priority material. The lower the priority, the lower the retention (see: Tools : Statistics : Analysis : Graphs : Forgetting index vs. Priority for empirical evidence).
By default, your repetitions will be auto-sorted at the beginning of each learning day (unless you uncheck Learn : Sorting : Auto-sort repetitions). This means that the elements reviewed on a given day will be ordered by priority. In addition to auto-sorting, you can also sort the learning queue manually at any time with Learn : Sorting : Sort now.
You will quickly discover that a precise sort executed strictly along the priority criteria has serious flaws. On one hand, due to the priority bias, you will quickly displace older high-quality material with whatever dominates your current interests. That would be a throwback to your pre-SuperMemo times when you kept reading new material, while forgetting your previous investment in learning. New material always feels very important and will always show a tendency to shift all your previous learning towards lower priority. In addition, you might overwhelm your classical SuperMemo repetitions (i.e. question-and-answer review) with the inflow of new articles to read. Again, instead of making sure your previous investment becomes durable, you keep rushing through new material and forgetting the old.
SuperMemo solves the problems of the priority bias and the problem of the massive inflow of topics by letting you define:
- the proportion of topics in learning, and
- a degree to which the learning queue is randomized.

Figure: Sorting criteria in SuperMemo. Only a small proportion of time-consuming topics is allowed in the learning queue. This proportion is chosen to maximize the fun and efficiency of learning: sufficient inflow of new material combined with the necessary review of your previous investment. Some degree of randomization in the learning sequence is permitted. This way you can re-discover precious articles that were displaced in priority by a massive inflow of new material. In the presented example, topics show a higher degree of randomization than items.
You can determine the sorting criteria by using Learn : Sorting : Sorting criteria. You need to adjust the proportion of topics and the degree of randomization by trial and error. This will all depend on your goals and preferences. If you admit too few topics in the process, you will not gain much new knowledge. If you allow too many topics, you will start forgetting previously learned material. If you randomize the learning queue too much, the whole prioritization mechanism will unravel, and your retention of high-priority material will drop. If you sort repetitions strictly by priority, the new material will keep displacing the old material due to the priority bias. Even for item repetitions, where the priority bias is less prominent, a degree of randomization will help you increase the priority of less appreciated items, disperse clozes generated from the same extract, and compensate some loss in retention by improving the overall speed of learning (through spacing effect).
Proportion of topics tells you how many topics you will be served during your repetitions as compared with items. If you want to ensure that you keep a high retention of previously added material (as per SuperMemo definition), you cannot overload the learning process with new material (new topics) because you will not have enough time left to do your daily item review. In a healthy learning process, you should limit the inflow of topics to 1:4 or less (i.e. allow of repeating at least 4 items per each topic served).
Random repetitions
To make sure you have a good understanding of the contents and distribution of the learning material in your collection, you should make randomized repetitions from time to time. This is to prevent tunnel vision and priority bias. You can randomize repetitions with Learn : Random : Randomize repetitions (Shift+Ctrl+F11), or with Tools : Mercy with Criteria : Sorting options set to Randomize.
Occasional random repetitions may be quite revealing as they will not favor any portions of your material. Your learning will not be biased by an increased proportion of elements such as: short-interval elements, long-interval elements, specific element types (e.g. articles, extracts, cloze deletions, etc.), element content (e.g. a specific branch of the knowledge tree), the degree of element processing, nor (most importantly) the element's priority. Random repetitions will help you understand the possible negative trends such as an excessive inflow of new material, low retention due to frequent rescheduling, poor formulation of newly created cloze deletions, low quality or applicability of the acquired knowledge, excessive emphasis on certain subject at the cost of other subjects, etc. Most importantly though, random repetitions should help you sense the power of the priority bias. You will notice that you will instantly be tempted to up-prioritize large sections of the material that has slipped your attention while focusing on new imports.
Prioritization rulebook
- Learn to work on priorities of new elements. Try to visualize the entire collection and learn to position elements in the spectrum of your entire knowledge. Try to ignore urgency, and to focus on the lifetime priority of knowledge (unless under a pressure of a deadline or an exam). If all your new elements get priorities of 1-10%, you know you are not being honest. Some of the new material must be down to 80-90%. There are things that you want to know, but you do not really need to know. Add them to your collection, but give them an honestly low priority. Do you learn about movie stars? That's ok. However, unless you want to be an actor yourself (or similar), you should rather give the stars the deserved 95-99%.
- Early in the process, you may find it hard to sense the difference between 30% and 60% priority. Or you may keep setting the priority always to 1%. The fact that SuperMemo displays the priority at four decimal places may make you feel your prioritizations are not adequate. Ignore those feelings. You can start from a 3 point scale: 1%, 33%, and 88%. The more you prioritize, the more natural and automatic it feels. Be patient.
- Deprioritization is very hard and very painful, however, it might be a key to your success in a heavily overloaded collection. It is very easy to wish to up-prioritize nearly anything. You need to train your brain to permit low priorities! You need to let some knowledge go (at least to lower priority areas)! You cannot know everything that you want to know! (unless you want to know little)
- Regularly inspect Tools : Statistics : Analysis : Use : Priority protection : Items (Shift+Alt+A opens this tab as you left it last time). Priority protection is the most honest indicator of what proportion of your collection can actually meet your requested forgetting index criteria. For example, if your Priority protection stand at 3%, you know that no knowledge in the 3%-100% priority bracket is safe! If you keep overrating priorities, items will crowd at high priority positions and the Priority protection parameter will be very low. If you are honest, you will increase that value and make it easier to protect top priority items from being delayed and possibly forgotten. You will be amazed how fast you can increase Priority protection with a focused effort and deprioritization in just a few days (let alone over a longer period)! See the example in the picture below. Such efforts will do miracles to the quality of your knowledge. Importance should always overrule urgency and emotion.
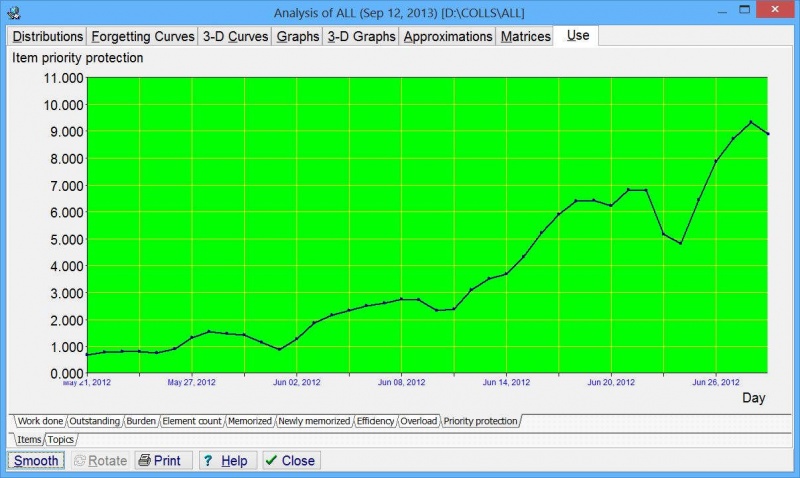
- Regulary inspect Tools : Statistics : Statistics : Protection. This parameters tells you how far you managed to cut into your top priority material in a given session (this is an equivalent of Priority protection for a single day). If those numbers get very low, you need to start deprioritizing your items (or topics). You do not need to cut your import appetites as long as you keep priorities reasonable.
- The most important moments to prioritize elements or element sets:
- at item failure, you need to rethink the priority. Items that fail often are the biggest contributor to slowed progress. Reducing their priority is one way of remedying this (and possibly helping your memory by inducing the spacing effect or reducing interference)
- at article import, high priority will ensure early reading, however, once you get to reading, you may want to deprioritize and only give high priority to important extracts! You can set the priority for the entire article and split it all in one go (while reading or by an auto-split). It is however much easier to split the article incrementally as you progress with reading, and only then spread the priorities of all children elements with Priority : Spread on the browser processing menu. Once you finish reading the article, some of the generated extracts and clozes will be given higher priority (as per your decision), while most elements will get their priority set automatically on the basis of article's priority. This will usually be a priority that is higher than deserved. Hence Priority : Spread is recommended each time you complete reading an article
- it makes sense to give new clozes a very high priority to make sure they are reviewed at least once to "hatch" in your memory. However, once the first repetition ends with success and your future recall at longer intervals is a bit more likely, you can provide a more honest priority, which is usually lower than when first prioritizing extracts for the sake of generating cloze deletions. If you are still worried about possible forgetting, you can wait with establishing the honest priority until the 3rd or 4th review. The longer you wait, the greater the chance you will forget something truly important in the meantime.
- If you hesitate between a lower priority and a higher priority, a lower priority is nearly always better! (due to the priority bias that is likely to crowd your learning process)
- If you skip some of your daily repetition sessions, item protection will drop (as indicated by Priority protection in Analysis : Use). If you do not prioritize well, item protection will drop as well. The best way to keep item protection high is to learn regularly, learn a lot, and provide honest priority evaluations
- Your measured forgetting index will increase if you are honest with priorities in an overloaded collection. However, it will more honestly reflect your actual knowledge of the material in the collection. To see how forgetting index changes with priority, see Tools : Statistics : Analysis : Graphs : Forgetting index vs. Priority
- If you manually change the interval, element priorities will change. If you shorten the interval, the priority will automatically increase. If you delay the next repetition, the priority will drop.
- Priority protection can at times drop by a huge margin in a single day. This is not a reason to worry, as long as this does not become a trend. For example, if you discover a set of clozes whose priority is too low, and you increase that priority in the entire set, all items that have been outstanding, but not at the front of the outstanding queue, will affect the item protection measurement on the next day. This is a one-day phenomenon. However, you will also notice a destructive impact of massive up-prioritizations. It is easy to say "that branch is very important", and very difficult to undo the damage by indiscriminate change of priorities.
- If you are curious which postponed item reduced your item protection (Priority protection), choose View : Recent : Postponed, choose Child : Items on the browser menu, and sort by priority (e.g. by clicking the Prior column heading). The offending item should land on top. It will tell how your item protection dropped. This is the highest priority item missed on the previous day of learning.
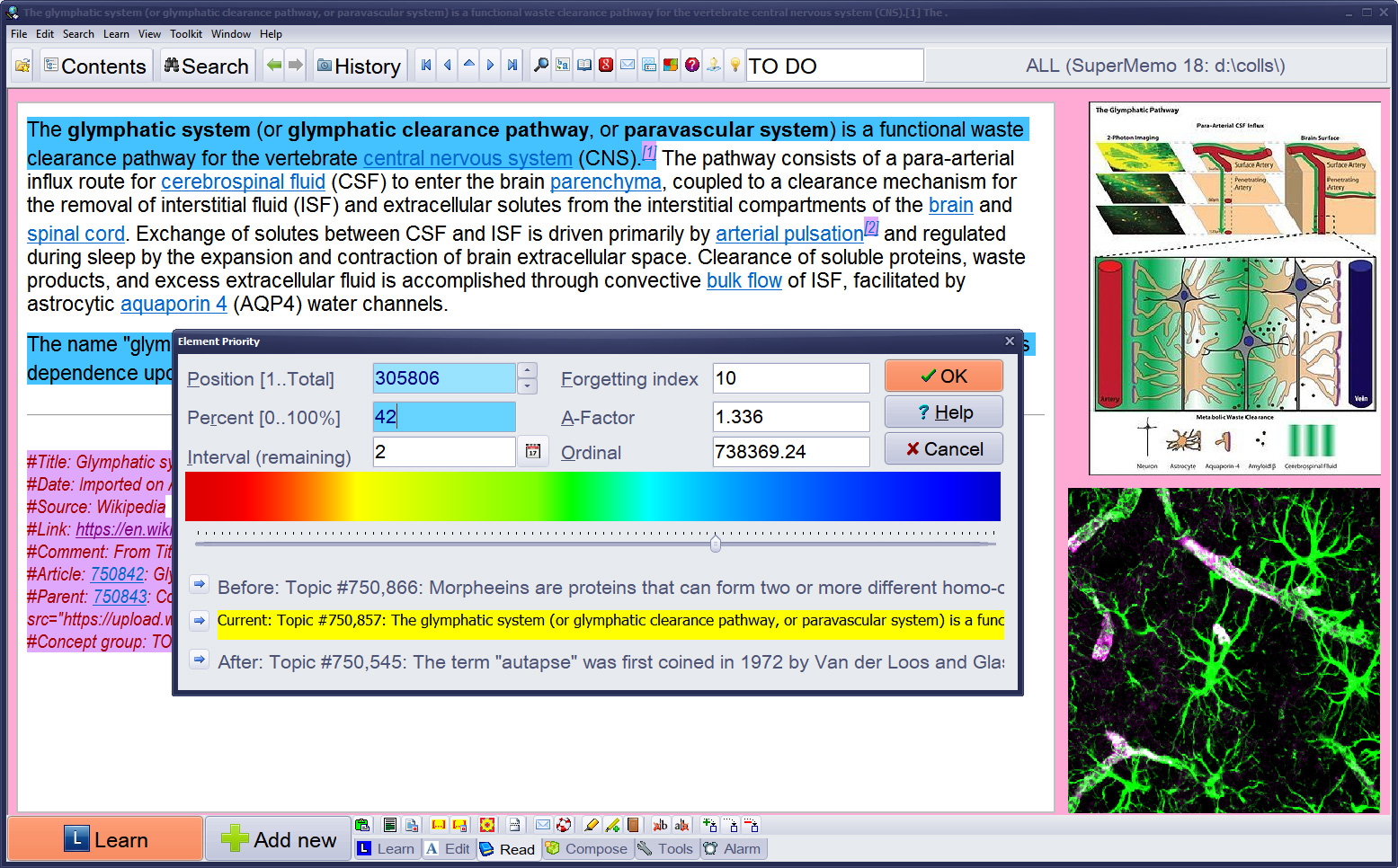
- A simple way to get the feel of the relative importance of an article is to look at the After and Before fields in the Element priority dialog box (Alt+P).

Figure: A simple way to get the feel of the relative importance of an article is to look at the After and Before fields in the Element priority dialog box (Alt+P). In the picture, an extract from a Wikipedia Donald Trump article in ref. to a ban on Muslims receives priority 64%. This priority is comparable with items about the cost of space shuttle flight and about the orbitofrontal cortex.
- The main difference between lifelong learning and school learning is that schools artificially distort the priority of the learning material. Before an exam, a section of material must receive high priority and high processing, while after the exam, the same material must be realistically re-assessed (which usually means a manifold decrease in priority and heavy dilution of the overload).

Priority queue: Summary
- SuperMemo uses a priority queue in which all elements are arranged by their priority in the learning process
- The highest priority is
0%. The lowest priority is100% - SuperMemo can auto-postpone the excess of the outstanding material
- SuperMemo uses the priority queue to auto-sort the learning queue. This means that each day, you will first be served high-priority elements
- Priority queue softens the need for moderation in learning; however, it does not entirely solve the priority bias
- SuperMemo automates moderation by strictly limiting the inflow of topics into the learning process
- SuperMemo helps you combat the priority bias by a user-defined degree of randomization in sorting the learning queue
- In a heavily overloaded learning process, the retention of low-priority material will drop substantially
- Deprioritization of elements is painful, but it is a key to your long-term success. Due to the priority bias, lower priority is nearly always better than a higher priority!
- Tools : Statistics : Analysis : Use : Priority protection : Items can be used to inspect the degree of item protection in an overloaded learning process
- Tools : Statistics : Statistics : Protection can be used to inspect one's progress in processing top priority material on a given day
- Priority queue will help you increase the volume of learning, and still increase the retention of top-priority material