This older version of the SuperMemo algorithm runs in parallel with Algorithm SM-17, and can be used to visualize differences and/or the superiority of Algorithm SM-17
Below you will find a general outline of the 8th major formulation of the repetition spacing algorithm used in SuperMemo. It is referred to as Algorithm SM-15 since it was first implemented in SuperMemo 15.0. Although the increase in complexity of Algorithm SM-15 as compared with its predecessors (e.g. Algorithm SM-6) is incomparably greater than the expected benefit for the user, there is a substantial theoretical and practical evidence that the increase in the speed of learning resulting from the upgrade may fall into the range from 30 to 50%. In addition, Algorithm SM-15 eliminates various problems with repetition delay and repetition advancement evident in Algorithm SM-8.
Historic note: earlier releases of the algorithm
Although the presented algorithm may seem complex, you should find it easier to follow its steps once you understand the evolution of individual concepts such as E-Factor, matrix of optimum intervals, optimum factors, forgetting curves, or mid-interval repetition:
- 1985 - Paper-and-pencil version of SuperMemo is formulated (Algorithm SM-0). Repetitions of whole pages of material proceed along a fixed table of intervals. See also: Using SuperMemo without a computer
- 1987 - First computer implementation makes it possible to divide material into individual items. Items are classified into difficulty categories by means of E-Factor. Each difficulty category has its own optimum spacing of repetitions (Algorithm SM-2)
- 1989 - SuperMemo 4 was able to modify the function of optimum intervals depending on the student's performance (Algorithm SM-4). This was then the first algorithm in which the function of optimal intervals was adaptable
- 1989 - SuperMemo 5 replaced the matrix of optimum intervals with the matrix of optimal factors (an optimum factor is the ratio between successive intervals). This approach accelerated the adaptation of the function of optimum intervals (Algorithm SM-5)
- 1991 - SuperMemo 6 derived optimal factors from forgetting curves plotted for each entry of the matrix of optimum factors. This could dramatically speed up the convergence of the function of optimum intervals to its ultimate value (Algorithm SM-6). This was then the first adaptable algorithm that would use regression to find the best fit to the actual memory performance data. Unlike SuperMemo 5, which could keep converging and diverging depending on the quality of the learning material and the learning process, SuperMemo 6 would get closer to the student's ultimate memory model with each day of learning
- 1995 - SuperMemo 8 capitalized on data collected by users of SuperMemo 6 and SuperMemo 7 and added a number of improvements that strengthened the theoretical validity of the function of optimum intervals and made it possible to accelerate its adaptation, esp. in the early stages of learning (Algorithm SM-8). New concepts:
- replacing E-Factors with absolute difficulty factors: A-Factors. Item difficulty was thus defined in terms of actual properties of human memory, and would not depend on the average difficulty of the learning material
- fast approximation of A-Factors from the First Grade vs. A-Factor correlation graph and Grade vs. Forgetting index graph. This makes it possible to quickly guess item's difficulty before more data is available
- real-time adjustment of the matrix of optimal factors based on the power approximation of the decline of optimum factors
- 2002 - SuperMemo 2002 introduced the first SuperMemo algorithm that is resistant to interference from delay or advancement of repetitions. This makes it possible to safely delay repetitions (Postpone) or advance repetitions (Review):
- accounting for delayed repetitions by introducing the concept of repetition categories
- accounting for advanced repetitions by introducing O-Factor decrements derived from the concept of the spacing effect
- 2005 - SuperMemo 2004 introduced boundaries on A and B parameters computed from the Grade vs. Forgetting Index data. This plugs up a weakness in the algorithm that showed when importing repetitions from other applications (e.g. open source MemAid). If a large number of easy repetitions occurred at unnaturally long intervals (as after pre-training with another application), the graph might show reversed monotonicity that would temporarily affect the estimation of A-Factors (the speed of self-correction would be reversely proportional to the amount of flawed data). When boundaries are imposed, self-correction is instant, and the accuracy of A-Factor estimation increases with each repetition executed in SuperMemo
- 2011 - SuperMemo 15 eliminated two weaknesses of Algorithm SM-11 that would show up in heavily overloaded collections with very large item delays:
- U-Factors now allow of correctly interpreting repetition delays of up to 15 years
- forgetting curves are now corrected for repetition delays beyond the maximum registered U-Factor value (preventing failed grades in delayed repetitions decreasing the estimates of the optimum interval for standardly-scheduled items in the same category)
- 2015 - Algorithm SM-17 is a successor to all prior versions of the algorithm in future SuperMemos. It has passed all important benchmarks with surprisingly good results
Algorithm SM-15
SuperMemo begins the effort to compute the optimum inter-repetition intervals by storing the recall record of individual items (i.e. grades scored in learning). This record is used to estimate the current strength of a given memory trace, and the difficulty of the underlying piece of knowledge (item). The item difficulty expresses the complexity of memories, and reflects the effort needed to produce unambiguous and stable memory traces. SuperMemo takes the requested recall rate as the optimization criterion (e.g. 95%), and computes the intervals that satisfy this criterion. The function of optimum intervals is represented in a matrix form (OF matrix) and is subject to modification based on the results of the learning process. Although satisfying the optimization criterion is relatively easy, the complexity of the algorithm derives from the need to obtain maximum speed of convergence possible in the light of the known memory models.
Important! Algorithm SM-15 is used only to compute the intervals between repetitions of items. Topics are reviewed at intervals computed with an entirely different algorithm (not described here). The timing of topic review is optimized with the view to managing the reading sequence, and is not aimed at aiding memory. Long term memories are formed in SuperMemo primarily with the help of items, which are reviewed along the schedule computed by Algorithm SM-15.
This is a more detailed description of the Algorithm SM-15:
- Optimum interval: Inter-repetition intervals are computed using the following formula:
I(1)=OF[1,L+1]
I(n)=I(n-1)*OF[n,AF]
where:- OF - matrix of optimal factors, which is modified in the course of repetitions
- OF[1,L+1] - value of the OF matrix entry taken from the first row and the L+1 column
- OF[n,AF] - value of the OF matrix entry that corresponds with the n-th repetition, and with item difficulty AF
- L - number of times a given item has been forgotten (from "memory Lapses")
- AF - number that reflects absolute difficulty of a given item (from "Absolute difficulty Factor")
- I(n) - n-th inter-repetition interval for a given item
- Advanced repetitions: Because of possible advancement in executing repetitions (e.g. forced review before an exam), the actual optimum factor (OF) used to compute the optimum interval is decremented by dOF using formulas that account for the spacing effect in learning:
dOF=dOFmax*a/(thalf+a)
dOFmax=(OF-1)*(OI+thalf-1)/(OI-1)
where:- dOF - decrement to OF resulting from the spacing effect
- a - advancement of the repetition in days as compared with the optimum schedule (note that there is no change to OF if a=0, i.e. the repetition takes time at optimum time)
- dOFmax - asymptotic limit on dOF for infinite a (note that for a=OI-1 the decrement will be OF-1 which corresponds to no increase in inter-repetition interval)
- thalf - advancement at which there is half the expected increase to synaptic stability as a result of a repetition (presently this value corresponds roughly to 60% of the length of the optimum interval for well-structured material)
- OF - optimum factor (i.e. OF[n,AF] for the n-th interval and a given value of AF)
- OI - optimum interval (as derived from the OF matrix)
- Delayed repetitions: Because of possible delays in executing repetitions, the OF matrix is not actually indexed with repetitions but with repetition categories. For example if the 5-th repetition is delayed, OF matrix is used to compute the repetition category, i.e. the theoretical value of the repetition number that corresponds with the interval used before the repetition. The repetition category may, for example, assume the value 5.3 and we will arrive at I(5)=I(4)*OF[5.3,AF] where OF[5.3,AF] has a intermediate value derived from OF[5,AF] and OF[6,AF]
- Matrix of optimum intervals: SuperMemo does not store the matrix of optimum intervals as in some earlier versions. Instead it keeps a matrix of optimal factors that can be converted to the matrix of optimum intervals (as in the formula from Point 1). The matrix of optimal factors OF used in Point 1 has been derived from the mathematical model of forgetting and from similar matrices built on data collected in years of repetitions in collections created by a number of users. Its initial setting corresponds with values found for a less-than-average student. During repetitions, upon collecting more and more data about the student's memory, the matrix is gradually modified to make it approach closely the actual student's memory properties. After years of repetitions, new data can be fed back to generate more accurate initial OF matrix. In SuperMemo 16, this matrix can be viewed in 3D with Tools : Statistics : Analysis : 3-D Graphs : O-Factor Matrix
- Item difficulty: The absolute item difficulty factor (A-Factor), denoted AF in Point 1, expresses the difficulty of an item (the higher it is, the easier the item). It is worth noting that AF=OF[2,AF]. In other words, AF denotes the optimum interval increase factor after the second repetition. This is also equivalent with the highest interval increase factor for a given item. Unlike E-Factors in Algorithm SM-6 employed in SuperMemo 6 and SuperMemo 7, A-Factors express absolute item difficulty and do not depend on the difficulty of other items in the same collection of study material (see FAQs for an explanation)
- Deriving OF matrix from RF matrix: Optimum values of the entries of the OF matrix are derived through a sequence of approximation procedures from the RF matrix which is defined in the same way as the OF matrix (see Point 1), with the exception that its values are taken from the real learning process of the student for who the optimization is run. Initially, matrices OF and RF are identical; however, entries of the RF matrix are modified with each repetition, and a new value of the OF matrix is computed from the RF matrix by using approximation procedures. This effectively produces the OF matrix as a smoothed up form of the RF matrix. In simple terms, the RF matrix at any given moment corresponds to its best-fit value derived from the learning process; however, each entry is considered a best-fit entry on its own, i.e. in abstraction from the values of other RF entries. At the same time, the OF matrix is considered a best-fit as a whole. In other words, the RF matrix is computed entry by entry during repetitions, while the OF matrix is a smoothed copy of the RF matrix
- Forgetting curves: Individual entries of the RF matrix are computed from forgetting curves approximated for each entry individually. Each forgetting curve corresponds with a different value of the repetition number and a different value of A-Factor (or memory lapses in the case of the first repetition). The value of the RF matrix entry corresponds to the moment in time where the forgetting curve passes the knowledge retention point derived from the requested forgetting index. For example, for the first repetition of a new item, if the forgetting index equals 10%, and after four days the knowledge retention indicated by the forgetting curve drops below 90% value, the value of RF[1,1] is taken as four. This means that all items entering the learning process will be repeated after four days (assuming that the matrices OF and RF do not differ at the first row of the first column). This satisfies the main premise of SuperMemo, that the repetition should take place at the moment when the forgetting probability equals 100% minus the forgetting index stated as percentage. In SuperMemo 16, forgetting curves can be viewed with Tools : Statistics : Analysis : Forgetting Curves (or in 3-D with Tools : Statistics : Analysis : 3-D Curves):
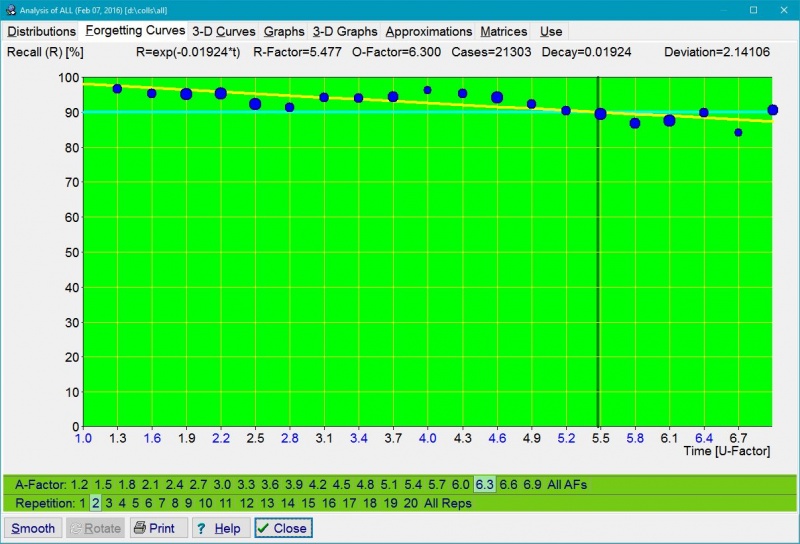
Uniform forgetting curve for a single memory stability and item difficulty level
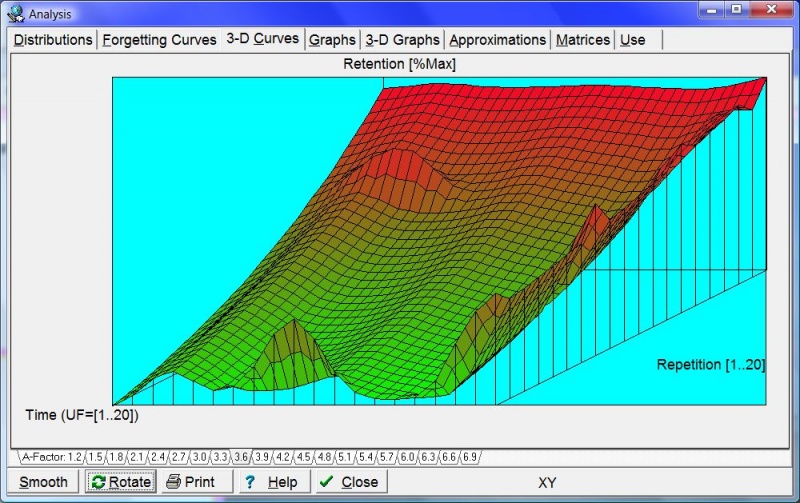
3D representation of the family of forgetting curves for a single item difficulty and varying memory stability levels (normalized for U-Factor)
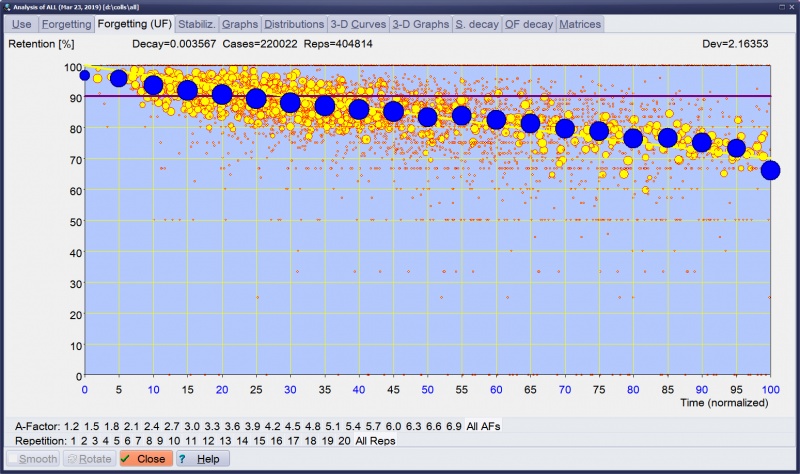
A cumulative normalized forgetting curve for all registered repetition cases in a single collection
- Deriving OF matrix from the forgetting curves: The OF matrix is derived from the RF matrix by:
- fixed-point power approximation of the R-Factor decline along the RF matrix columns (the fixed point corresponds to second repetition at which the approximation curve passes through the A-Factor value),
- for all columns, computing D-Factor which expresses the decay constant of the power approximation,
- linear regression of D-Factor change across the RF matrix columns, and
- deriving the entire OF matrix from the slope and intercept of the straight line that makes up the best fit in the D-Factor graph. The exact formulas used in this final step go beyond the scope of this illustration.
All the above steps are passed after each repetition. In other words, the theoretically optimum value of the OF matrix is updated as soon as new forgetting curve data is collected, i.e. at the moment, during the repetition, when the student, by providing a grade, states the correct recall or wrong recall (i.e. forgetting) (in Algorithm SM-6, a separate procedure Approximate had to be used to find the best-fit OF matrix, and the OF matrix used at repetitions might differ substantially from its best-fit value) - Item difficulty: The initial value of A-Factor is derived from the first grade obtained by the item, and the correlation graph of the first grade and A-Factor (G-AF graph). This graph is updated after each repetition in which a new A-Factor value is estimated and correlated with the item's first grade. Subsequent approximations of the real A-Factor value are done after each repetition by using grades, OF matrix, and a correlation graph that shows the correspondence of the grade with the expected forgetting index (FI-G graph). The grade used to compute the initial A-Factor is normalized, i.e. adjusted for the difference between the actually used interval and the optimum interval for the forgetting index equal 10%
- Grades vs. expected forgetting index correlation: The FI-G graph is updated after each repetition by using the expected forgetting index and actual grade scores. The expected forgetting index can easily be derived from the interval used between repetitions and the optimum interval computed from the OF matrix. The higher the value of the expected forgetting index, the lower the grade. From the grade and the FI-G graph (see: FI-G graph in Tools : Statistics : Analysis), we can compute the estimated forgetting index which corresponds to the post-repetition estimation of the forgetting probability of the just-repeated item at the hypothetical pre-repetition stage. Because of the stochastic nature of forgetting and recall, the same item might or might not be recalled depending on the current overall cognitive status of the brain; even if the strength and retrievability of memories of all contributing synapses is/was identical! This way we can speak about the pre-repetition recall probability of an item that has just been recalled (or not). This probability is expressed by the estimated forgetting index

- Computing A-Factors: From (1) the estimated forgetting index, (2) length of the interval and (3) the OF matrix, we can easily compute the most accurate value of A-Factor. Note that A-Factor serves as an index to the OF matrix, while the estimated forgetting index allows one to find the column of the OF matrix for which the optimum interval corresponds with the actually used interval corrected for the deviation of the estimated forgetting index from the requested forgetting index. At each repetition, a weighted average is taken of the old A-Factor and the new estimated value of the A-Factor. The newly obtained A-Factor is used in indexing the OF matrix when computing the new optimum inter-repetition interval




To sum it up. Repetitions result in computing a set of parameters characterizing the memory of the student: RF matrix, G-AF graph, and FI-G graph. They are also used to compute A-Factors of individual items that characterize the difficulty of the learned material. The RF matrix is smoothed up to produce the OF matrix, which in turn is used in computing the optimum inter-repetition interval for items of different difficulty (A-Factor) and different number of repetitions (or memory lapses in the case of the first repetition). Initially, all student’s memory parameters are taken as for a less-than-average student (less-than average yields faster convergence than average or more-than-average), while all A-Factors are assumed to be equal (unknown).
Optimization solutions used in Algorithm SM-15 have been perfected over 24 years of using the SuperMemo method with computer-based algorithms (first implementation: December 1987). This makes sure that the convergence of the starting memory parameters with the actual parameters of the student proceeds in a very short time. In addition, Algorithm SM-15 includes mechanisms that make it insensitive to interference from the deviation from the optimum repetition timing (e.g. delayed or advanced repetitions). It can also accept uninitialized learning process imported from other applications (e.g. other SuperMemos). The introduction of A-Factors and the use of the G-AF graph greatly enhanced the speed of estimating item difficulty. The adopted solutions are the result of constant research into new algorithmic variants. The theoretical considerations, as well as the research into the employment of neural networks in repetition spacing indicates it is not likely neural networks could effectively compete with the presented algebraic solution (see FAQ below).
Algorithm SM-15 is constantly being perfected in successive releases of SuperMemo, esp. to account for newly collected repetition data, convergence data, input parameters, instabilities, etc. In particular, new procedures are being researched for capitalizing on sleep log data collected by SuperMemo. Making repetitions at optimum circadian time should allow of substantial increase in optimum intervals, and further acceleration of the learning process in those individuals who opt to log in their sleep data.
FAQ
When inspecting optimization matrices, use repetition category, not repetition number
From: Steven Trezise
Country: USA
Sent: Apr 20, 1999
Question
In my collection, I have items for which I have done between 1 and 8 repetitions. However, when I look at the Cases matrix, there are no entries beyond repetition 3
Answer
The algorithm used by SuperMemo updates all optimization matrices using repetition categories, not the actual repetition number (you can view the optimization matrices with Tools : Statistics : Analysis : Matrices). A repetition category is an expected number of repetitions needed to reach the currently used interval. Once the matrices change, the estimation of repetition category may change too. If, for example, you score well in repetitions and your intervals become longer, it will take fewer repetitions to get to a given interval. In such a case, you might be at 8-th repetition while your repetition category will be 3. All matrices such as OF matrix, RF matrix, etc. will be updated in the third row (not in the 8-th row)
A-Factors can drop even if grades are good
From: Dr. Prateek Mishra
Country: India
Sent: Oct 5, 2000
Question
I noticed that A-Factor may decrease even if the grade is Great. Is this correct?
Answer
Usually, the better the grade the greater the increase in A-Factor. However, the new value of A-Factor for Repetition>1 is computed by trying to find this column in OF matrix which provides the best fit for the estimated value of the optimal interval for the just executed repetition. In other words, the algorithm checks how well the item fared after a given interval, makes a guess as to the optimal interval for similar situations in the future, and then, using the same information makes a guess as to the true difficulty of the just repeated item. If your item was considered "A-Factor(i) difficult" on Day(i) and the values in the OF matrix increased substantially before the Day(i+1) on which the next repetition takes place, A-Factor(i+1) may appear lower than A-Factor(i) even if you scored Great (which reflects the fact that the used interval could even be longer). Simply, the relative valuation of difficulty will have changed during the inter-repetition interval. It is worth noting that each time you worry about the accuracy of the SuperMemo algorithm, you should simply look at the measured forgetting index in the statistics (Measured FI). This value should equal to your requested forgetting index. Usually it is slightly higher due to minor inaccuracies of the algorithm. However, the main contributor to an overly high measured forgetting index is delay in making repetitions (the picture illustrates slow 7-months-long recovery of the measured forgetting index from a one-time use of Tools : Mercy in SuperMemo)

To better understand the relationship between the new value of A-Factor and the estimated forgetting index, see this function taken from SuperMemo source code (simplified for clarity; valid only for Repetition>1):
function GetNewAFactorFromEstimatedFI(IOD:PItemOptimizationData):real;
var col:byte;
OptimumInterval,OFactor:real;
begin
with IOD^ do begin
OptimumInterval:=(UsedInterval*ln(0.9)/ln(1-EstimatedFI/100));
{Optimum interval computed from EstimatedFI and adjusted to FI=10%}
OFactor:=OptimumInterval/UsedInterval*UFactor;
for col:=20 downto 1 do {scan columns of the OF matrix}
if OFactor>EstimatedOFactor(col,RepetitionsCategory) then
break;
end;
Result:=AFactorFromOFColumn(col); {new value of A-Factor}
end;
RF stands for "retention factor"
From: Malcolm Macgregor
Sent: Saturday, September 21, 2002 12:32 AM
Question
What does RF stand for?
Answer
RF stands for "retention factor". In the ideal world, RF would be the same as OF. However, in the real world, RFs reflect the noise of the stochastic nature of forgetting. In other words, when the sample of measured repetitions is small, RF may deviate from OF. RFs are computed from forgetting curves plotted in the course of repetitions. For a large number of repetitions, when the forgetting curve starts resembling a negatively exponential curve, RFs will approach OFs in value. However, as this approximation process may take months or years, the matrix of OF is derived by smoothing the matrix of RF. Some entries of the RF matrix are never filled out with real data values. For example, we never get to the 10th repetition of very easy material. We simply die before the chance to collect data occurs. This is why the RF matrix is composed of entries based on "intense research", "rough approximation" as well as "educated guess". The formulas to compute the OF matrix try to do the best fit of the theoretical OF matrix to this miscellany of RF data
Forgetting curve for ill-formulated items is flattened
Sent: Wednesday, July 25, 2001 2:54 PM
Question
I had a 5-months break in using SuperMemo. I resumed my repetitions and noticed that I still remembered many items. Initially, SuperMemo asked me to repeat difficult items (e.g. enumerations). To my surprise, I remembered many of these items. SuperMemo required a 15 days interval, while I made my repetitions after 150 days and still succeeded. I no longer believe in the optimality of the SuperMemo algorithm. Probably it is 10 times worse than optimal
Answer
Your results are in full compliance with theoretical expectations. It is no surprise that SuperMemo initially tossed the most difficult items at you, and it is no surprise that you showed remarkable recall on these items. Those items clearly belong to those that have not been formulated in compliance with representation rules (e.g. enumerations are notoriously difficult). If you imagine memories as sets of apples (you can see an apple as a single synapse in the brain), good memories are like small collections of well-polished apples. Bad memories (e.g. enumerations, complex items, ambiguous items, etc.) are like large collections of apples of which few are spoilt. Naturally, spoilt apples rot fast and make recall difficult. After just 15 days, all spoilt apples might have been rotten. During the remaining 150 days, the remaining apples rot very slowly. Hence the typical departure of wrongly formulated items from the shape of the classical forgetting curve. For bad items, the curve is flattened (as an expected superposition of several Ebbinghausian curves). SuperMemo blindly obeys your recall criteria. If it takes 15 days to ensure 98% recall, SuperMemo will take no consideration of the fact that at 150 days you may still show 95% recall. This is why SuperMemo 16 includes leech management. It makes it easy to identify bad items and use auto-postpone or auto-forget options. Auto-postpone will do exactly what you expect, i.e. delay bad items with little impact on overall retention. Auto-forget will help you rebuild memories from scratch. Occasionally, the newly established memory representation will click and your recall will improve. Naturally, the best method against bad items is the use of appropriate representation (see: 20 rules of formulating knowledge for learning). Interestingly, SuperMemo can never predict the moment of forgetting of a single item. Forgetting is a stochastic process and can only operate on averages. A frequently propagated fallacy about SuperMemo is that it predicts the exact moment of forgetting: this is not true, and this is not possible. What SuperMemo does is a search for intervals at which items of given difficulty are likely to show a given probability of forgetting (e.g. 5%). If you look for a numerical measure of the algorithm's inaccuracy, instead of comparing intervals you should rather compare retention levels as the retention is the optimization criterion here. Even for a pure negatively exponential forgetting curve, a 10-fold deviation in interval estimation will result in R2=exp(10*ln(R1)) difference in retention. This is equivalent to a drop from 98% to 81%. For a flattened forgetting curve typical of badly-formulated items, this drop may be as little as 98%->95%. For more on non-exponential forgetting curves see: Building memory stability
Flatter forgetting curve does not increase optimum interval
From: Tomasz P. Szynalski
Country: Poland
Sent: Saturday, August 04, 2001 5:53 AM
Question
If the forgetting curve is flatter for difficult items, I will remember them for a longer time, right? Does that suggest that ill-formulated items are remembered better?
Answer
No. Flattened forgetting curve will increase retention measurements in intervals that are a multiple of the optimum interval as compared with the typical negatively exponential curve for well-structured material. However, the optimum intervals for ill-formulated items will expectedly be shorter as can be observed on the first interval graph in Tools : Statistics : Analysis : Graphs : First Interval. The smoothness of this graph depends on the number of repetitions recorded. In the picture below, over 90,000 repetitions have been recorded

For more on non-exponential forgetting curves see: Building memory stability
Will SuperMemo use neural networks?
From: Dawid Calinski
Country: Poland
Sent: Fri, Apr 06, 2001 15:56
Question
I am curious when neural networks will have application in SuperMemo. Although speed of learning with algorithm used in SuperMemo 2000 is really great, it could be even faster with neural networks
Answer
- Known model: Neural networks are superior in cases where we do not know the underlying model of the mapped phenomena. The model of forgetting is well-known and makes it easy to fine-tune the algebraic optimization methods used in computing inter-repetition intervals. The well-known model also makes SuperMemo resistant to unbalanced data sets, which might plague neural networks, esp. in initial stages of learning
- Overlearning: Due to case weighted change in array values, optimization arrays used in SuperMemo are not subject to "overlearning". No pretraining is needed, as the approximate shape of the function of optimal intervals is known in advance. There is no data representation problem, as all kinky data input will be "weighed out" in time
- Equivalence: Mathematically speaking, for continuous functions, n-input networks are equivalent to n-dimensional arrays in mapping functions with n arguments, except for the "argument resolution problem". The scope of argument resolution problem, i.e. the finite number of argument value ranges, is strongly function dependent. A short peek at the optimization arrays displayed by SuperMemo indicates that the "argument resolution" is far better than what is actually needed for this particular type of function, esp. in the light of the substantial "noise" in data
- Research: The use of matrices in SuperMemo makes it easy to see "memory in action". Neural networks are not that well observable. They do not effectively reveal their findings. You cannot see how a single forgetting curve affects the function of optimum intervals. This means that the black-box nature of neural networks makes them less interesting as a memory research tool
- Convergence: The complexity of The Algorithm does not result from the complexity of the memory model. Most of the complexity comes from the use of tools that are supposed to speed up the convergence of the optimization procedure without jeopardizing its stability. This fine-tuning is only possible due to our good knowledge of the underlying memory model, as well as actual learning data collected over years that help us precisely determine best approximation function for individual components of the model
- Forgetting curve: The only way to determine the optimum interval for a given forgetting index is to know the (approximate) forgetting curve for a given difficulty class and memory stability. If a neural network does not attempt to map the forgetting curve, it will always oscillate around the value of the optimum interval (with good grades increasing that value, and bad grades decreasing it). Due to noise of data, this is only a theoretical problem; however, it illustrates the power of using a symbolic representation of stability-retrievability-difficulty-time relationship instead of a virtually infinite number of possible forgetting curve data sets. If the neural network does not use a weighted mapping of the forgetting curve, it will never converge. In other words, it will keep oscillating around the optimum model. If the neural network weighs in the status history and/or employs the forgetting curve, it will take the same approach as the present SuperMemo algorithm, which was to be obviated by the network in the first place
In other words, neural networks could be used to compute the intervals, but they do not seem to be the best tool in terms of computing power, research value, stability, and, most of all, the speed of convergence. When designing an optimum neural network, we run into similar difficulties as in designing the algebraic optimization procedure. In the end, whatever boundary conditions are set in "classic" SuperMemo, are likely to appear, sooner or later, in the network design (as can be seen in: Neural Network SuperMemo).
As with all function approximations, the choice of the tool and minor algorithmic adjustments can make a world of difference in the speed of convergence and the accuracy of mapping. Neural networks could find use in mapping the lesser known accessory functions that are used to speed up the convergence of the algebraic algorithm (e.g. user-dependent grade correlations that speed up the approximation of A-Factors, etc.).
New SuperMemo algorithms are superior, but this should not determine your choice of your learning program
From: Marjur
Country: Poland
Question
Could you comment on this info that I took from Anki's website:
Anki was originally based on the SuperMemo SM5 algorithm. However, Anki’s default behaviour of revealing the next interval before answering a card revealed some fundamental problems with the SM5 algorithm. The key difference between SM2 and later revisions of the algorithm is this:
- SM2 uses your performance on a card to determine the next time to schedule that card
- SM3+ use your performance on a card to determine the next time to schedule that card, and similar cards
The latter approach promises to choose more accurate intervals by factoring in not just a single card’s performance, but the performance as a group. If you are very consistent in your studies and all cards are of a very similar difficulty, this approach can work quite well. However, once inconsistencies are introduced into the equation (cards of varying difficulty, not studying at the same time every day), SM3+ is more prone to incorrect guesses at the next interval - resulting in cards being scheduled too often or too far in the future.
Furthermore, as SM3+ dynamically adjusts the "optimum factors" table, a situation can often arise where answering "hard" on a card can result in a longer interval than answering "easy" would give. The next times are hidden from you in SuperMemo so the user is never aware of this.
Source: Anki. "Frequently Asked Questions." Last modified Aug 10, 2011. http://ankisrs.net/docs/FrequentlyAskedQuestions.html#_what_spaced_repetition_algorithm_does_anki_use
I'm especially interested in this part:
The latter approach promises to choose more accurate intervals by factoring in not just a single card's performance, but the performance as a group. If you are very consistent in your studies and all cards are of a very similar difficulty, this approach can work quite well. However, once inconsistencies are introduced into the equation (cards of varying difficulty, not studying at the same time every day), SM3+ is more prone to incorrect guesses at the next interval - resulting in cards being scheduled too often or too far in the future.
Does SM really behave like this or is this description a result of the writer's misunderstanding? Does SM really factor[s] in not just a single card's performance, but the performance as a group?
If you do not wish to comment publicly, could you send me a private email with an answer (I will keep it private). I'm very interested in how SM algorithm works and how it compares to other SRS algorithms, e.g. of programs such as Anki or Mnemosyne.
Answer
Anki will work great with SM-2, but SM-5 is superior
It is great that Anki introduces its own innovations while still giving due credit to SuperMemo. It is true that SuperMemo's Algorithm SM-2 works great as compared with, for example, Leitner system, or SuperMemo on paper. However, superiority of Algorithm SM-5 over SM-2 is unquestionable. Both in practice and in theory. It is SM-2 that has the intervals hard-wired and dependent only on item's difficulty, which is approximated with a heuristic formula (i.e. a formula based on a guess derived from limited pre-1987 experience). It is true that you cannot "spoil" SM-2 by feeding it with false data. It is so only because it is non-adaptable. You probably prefer your word processor with customizable fonts even though you can mess up the text by applying Wingdings.
SM-2 simply crudely multiplies intervals by a so-called E-Factor which is a way of expressing item difficulty. In contrast, SM-5 collects data about user's performance and modifies the function of optimum intervals accordingly. In other words, it adapts to the student's performance. SM-6 goes even further and modifies the function of optimum intervals so that to achieve a desired level of knowledge retention. Superiority of those newer algorithms has been verified in more ways than one, for example, by measuring the decline in workload over time in fixed-size databases. In cases studied (small sample), the decline of workload with newer algorithms was nearly twice as fast as compared with older databases processed with SM-2 (same type of material: English vocabulary).
All SuperMemo algorithms group items into difficulty categories. SM-2 gives each category a rigid set of intervals. SM-5 gives each category the same set of intervals too, however, these are adapted on the basis of user's performance, i.e. not set in stone.
Consistency is indeed more important in SM-5 than it is in SM-2 as false data will result in "false adaptation". However, it is always bad to give untrue/cheat grades in SuperMemo, whichever algorithm you use.
Varying difficulty has never been a practical problem in SuperMemo. However, it is indeed affecting learning in algorithms SM-4 thru SM-6 and was only eliminated by the introduction of A-Factors in Algorithm SM-8. This is why it used to be recommended in the past that older SuperMemos used databases with similarly structured material (e.g. a separate database for learning Spanish, separate for History, etc.). The recommendation to keep all knowledge in a single collection came in the last decade and was based on the fact that Algorithms SM-8 through SM-15 actually do even better if your knowledge is varied in difficulty (more data to fill out various areas of the RF matrix, which represents your memory).
With incomplete knowledge of memory, adaptability is always superior to rigid models. This is why it is still better to adapt to an imprecise average (as in SM-5) than to base the intervals on a imprecise guess (as in SM-2). Needless to say, the last word goes to Algorithm SM-8 and later, as it adapts to the measured average (except for the first repetition of newly added items where we do not have any estimate of item difficulty).
Learning works best at peak alertness hours; ideally, in the morning
Studying at suboptimum hours will affect all algorithms as long as they are not aware of the homeostatic status of memory (which is possible only as of SuperMemo 2008 with the integration of Sleep Chart). This however has always been just a theoretical problem. It is again better to adapt to varying circadian performance than not to adapt at all. Moreover, the old recommendation is to always use SuperMemo at your peak alertness time. For a person with a healthy sleep it should always be subjective morning (i.e. after waking). However, for many students, good sleep is often a luxury and peak alertness may come at different times of day. Even late in the night. The recommendation to learn at peak hours eliminates the (purely) theoretical problem of a lack of feedback from the circadian system.
SuperMemo displays all details of its own performance
It is not clear what "next times" in SuperMemo are, however, SuperMemo is proud of its rich statistics that far exceed average user's needs. All data used by the algorithms are easily accessible and the performance of the algorithm can be evaluated in ways more than one.
Successive SuperMemos reduce the problem of "incorrect guesses"
The problem of "incorrect guesses" due to scarcity of data in the early stages of learning has been solved in SuperMemo by gradual departure from the average to the given student's model ("stability vs. accuracy" balance in optimization terms). The speed of such a transition must be fast enough to ensure an adaptation in reasonable time. However, SuperMemo makes sure that scarce data does not distort the function of optimum intervals (e.g. via matrix smoothing, boundary conditions, etc.). Metaphorically, if SM-2 was based on a guess with a given margin of error, SM-5 would apply the adaptation within the same margin of error. If you do not know the exact azimuth of your destination, it is always better to get an estimate and keep your eyes open than to get an estimate with no option to verify the trajectory. As of SM-6, actual forgetting curve data is collected and exponential regression is used to provide the best fit to the actual rate of forgetting. In other words, the guesses are as incorrect as all statistical regression models that departs from the never-known "correct reality".
Considerations are moot: chose the program that makes you enjoy learning more
All those detailed considerations should not obscure the fact that the Algorithm SM-2 works great in practice, and algorithmic fine-tuning is important more for theoretical than for practical reasons. Interference between the learning process and real life applications of knowledge levels most differences (if knowledge is actually applied). There are many factors that play a far greater role in learning: self-discipline, item formulation, mnemonic skills, mental hygiene, sleep, personality, joy of learning, etc. In the end, you should give your learning program a try and see which one you enjoy better. The pleasure of learning may determine your motivation which will play a far greater role in your future success. After all, most of SuperMemo dropouts give up learning before they ever experience results of "imprecise adaptations". They just do not find the program (or learning in general) fun enough.
In short, new SuperMemo algorithms might be superior, but this should not determine your choice of your favorite learning program.
Follow-up
Your reply contains some SuperMemo-specific terms (e.g. E-Factor, A-Factor, RF matrix, matrix smoothing, stability, collection - this is usually called a deck or a list by Anki users, etc), which may not be understood by the layman. How about a link to the glossary or something? If it is to come across, it needs to be comprehensible; otherwise, it may put some readers off.
Reply to the follow-up
- the essence of the reply is included in bold headlines, the details are included for those who want to skeptically review the reasoning behind the headlines
- it is difficult to speak about differences between SuperMemo algorithms without mentioning E-Factors, optimization matrices or forgetting curves. Links to the glossary have been included to improve the comprehension
- SuperMemo uses the term collection to describe the sets of its learning material files to differentiate from the old term database, which was more suitable for the old-style sets of questions and answers with simple picture or sound illustrations. Decks or lists are popular in flashcard applications, however, these imply less diversity (SuperMemo also includes topics, tasks, articles for reading, videos and their extracts, etc.), and no structure (as in the knowledge tree). As the FAQ is intended for the SuperMemo Algorithm article, it stands to reason to consistently use the same terminology as over the rest of the site. This followup should clear up potential confusion, if any.
E-Factors and A-Factors
From: Malcolm Macgregor
Sent: Saturday, September 21, 2002 12:32 AM
Question
You say "Unlike E-Factors... A-Factors express absolute item difficulty and do not depend on the difficulty of other items in the same collection". From my reading on E-factors they seem to express the easiness in learning of one item and I cannot see how they depend explicitly on the difficulty of other items
Answer
Originally, E-Factors were defined in the same way as O-Factors (i.e. the ratio of successive intervals). As such, they were an "objective" measure of item difficulty (the higher the E-Factor, the easier the item). However, starting with SuperMemo 4.0, E-Factors were used to index the matrix of O-Factors. They were still used to reflect item difficulty. They were still used to compute O-Factors. However, they could differ from O-Factors. In addition, difficulty of material in a given collection would shape the relationship between O-Factors and E-Factors. For example, in an easy collection, the starting-point O-Factor (i.e. first repetition of the assumed starting difficulty) would be relatively high. As performance in repetitions determines E-Factors, items of the same difficulty in an easy collection would naturally have a lower E-Factor than the exactly same items in a difficult collection. This all changed in SuperMemo 8 where A-Factors where introduced. A-Factors are "bound" to the second row of the O-Factor matrix. This makes them an absolute measure of item difficulty. Their value does not depend on the content of the collection. For example, you know that if A-Factor is 1.5, the third repetition will take place in an interval that is 50% longer than the first interval
SuperMemo algorithm can be made better
From: Dawid Calinski
Country: Poland
Sent: Dec 10, 2004, 01:51:18
Question
I bet SuperMemo algorithm is very good at scheduling reviews. But I also bet is now very complicated and therefore you have a limited capability of developing it further
Answer
Further improvements to the algorithm used in SuperMemo are not likely to result in further acceleration of learning. However, there is still scope for improvement for handling unusual cases such as dramatically delayed repetitions, massed presentation, handling items whose contents changed, handling semantic connections between items, etc. Interestingly, the greatest progress in the algorithm is likely to come from a better definition of the model of human long-term memory. In particular, the function describing changes in memory stability for different levels of retrievability is becoming better understood. This could dramatically simplify the algorithm. Simpler models require fewer variables and this simplifies the optimization. The algorithm based on stability and retrievability of memory traces could also result in better handling of items with low retrievability. However, as unusual item cases in the learning process form a minority, and testing a new algorithm would take several years, it is not clear if such an implementation will ever be undertaken
Why don't you continue your experiment with neural networks?
From: Bartosz
Country: Poland
Sent: Nov 01, 2006, 14:08:40
Question
Why don't you continue your experiment with neural networks? I agree with MemAid in that your models might be wrong, and a neural network can find the real truth about how memory works? Neural networks are unprejudiced
Answer
It is not true that SuperMemo is prejudiced while a neural network is not. Nothing prevents the optimization matrices in SuperMemo to depart from the memory model and produce an unexpected result. It is true, that over years, with more and more knowledge of how memory works, the algorithm used in SuperMemo has been armed with restrictions and customized sub-algorithms. None of these were a result of a wild guess though. The progression of "prejudice" in SuperMemo algorithms is only a reflection of findings from previous years. The same would inevitably affect any neural network implementation if it wanted to maximize its performance.
It is also not true that the original pre-set values of optimization matrices in SuperMemo are a form of prejudice. These are an equivalent of pre-training in a neural network. A neural net that has not be pre-trained will also be slower to converge to the optimum model. This is why SuperMemo is "pre-trained" with the model of an average student.
Finally, there is another area where neural networks must either use the existing knowledge of memory models (i.e. carry a dose of prejudice) or lose out on efficiency. The experimental neural network SuperMemo, MemAid, as well as FullRecall have all exhibited an inherent weakness. The network achieves the stability when the intervals produce a desired effect (e.g. specific level of the measured forgetting index). Each time the network departs from the optimum model it is fed with a heuristic guess on the value of the optimum interval depending on the grade scored during repetitions (e.g. grade=5 would correspond with 130% of the optimum interval in SuperMemo NN or 120% in MemAid). Algebraic SuperMemo, on the other hand, can compute an accurate value of A-Factor, use the accurate retention measurement, and produce an accurate adjustment of the value of the OF matrix. In other words, it does not guess on the optimal interval. It computes its exact value for that particular repetition. The adjustments to the OF matrix are weighted and produce a stable non-oscillating convergence. In other words, it is the memory model that makes it possible to eliminate the guess factor. With that respect, algebraic SuperMemo is less prejudiced than the neural network SuperMemo.
Neural network SuperMemo was a student project with a sole intent to verify the viability of neural networks in spaced repetition. Needless to say, neural networks are a viable tool. Moreover, all imaginable valid optimization tools, given sufficient refinement, are bound to produce similar results to those currently accomplished by SuperMemo. In other words, as long as the learning program is able to quickly converge to the optimum model and produce the desired level of knowledge retention, the optimization tool used to accomplish the goal is of secondary importance
How does SuperMemo compute the optimum increase in intervals?
From: Phil P.
Sent: Jul 05, 2007, 15:15:20
Question
I am reading your article about the two-components of long term memory. I understand that your learning software SuperMemo uses the described model to optimize learning. I am curious how SuperMemo computes the constant C2 from the Equation 2 (i.e. how does it know how much intervals should increase)?
Answer
Equation 2 is only a vastly simplified reflection of functions actually used in SuperMemo. The simplification was needed to prove the existence of two independent variables required to describe the status of simple memories: stability and retrievability.
C2 tells you how much inter-repetition intervals need to increase in learning to meet your criteria on admissible level of forgetting. In reality, C2 is not a constant. It depends on a number of factors. Of these, the most important are:
- item difficulty: the more difficult the remembered piece of information the smaller the C2 (i.e. difficult material must be reviewed more often)
- stability of memory: the more lasting/durable the memory, the smaller the C2 value
- probability of recall: the lower the probability of recall, the higher the C2 value (i.e. due to the spacing effect, items are remembered better if reviewed with delay)
Due to those multiple dependencies, the precise value of C2 is not easily predictable. SuperMemo solves this and similar optimization problems by using multidimensional matrices to represent multi-argument functions and adjusting the value of those matrices on the basis of measurements made during an actual learning process. The initial values of those matrices are derived from a theoretical model or from previous measurements, the actually used values will, over time, differ slightly from those theoretically predicted or those derived from data of previous students.
For example, if the value of C2 for a given item of a given difficulty with a given memory status produces an inter-repetition interval that is longer than desired (i.e. producing lower than desired level of recall), the value of C2 is reduced accordingly.
Historically, C2 can be found in nearly all algorithms used in SuperMemo, often under different names. This review may help you understand how SuperMemo computes C2 today and how it is likely to compute it in the future:
- in the paper-and-pencil version of SuperMemo (1985), C2 was indeed (almost) a constant. Set at the average of 1.75 (varying from 1.5 to 2.0 for rounding errors and simplicity), it did not consider material difficulty, stability or retrievability of memories, etc.
- in early versions of SuperMemo for DOS (1987), C2, named E-Factor, reflected item difficulty for the first time. It was decreased for bad grades and increased for good grades
- SuperMemo 4 (1989) did not use C2, but, to compute inter-repetition intervals, it employed optimization matrices for the first time
- in SuperMemo 5 (1990), C2, named O-Factor was finally represented as a matrix and it included both the difficulty dimension as well as the stability dimension. Again, entries of the matrix would be subject to the measure-verify-correct cycle that would, starting with the initial value based on prior measurements, produce a convergence towards the value that would satisfy the learning criteria
- in SuperMemo 6 (1991), C2, in the form of the O-Factor matrix would be derived from a three-dimensional matrix that would include the retrievability dimension. The important implication of the third dimension was that, for the first time, SuperMemo would make it possible to inspect forgetting curves for different levels of difficulty and memory stability
- in SuperMemo 8 (1997) through SuperMemo 16, the representation of C2 would not change much, however, the algorithm used to produce a quick and stable transition from the theoretical to the real set of data would gradually get more and more complex. Most importantly, new SuperMemos make a better use of the retrievability dimension of C2. Thus, independent of the spacing effect, the student can depart from the initial learning criteria, e.g. to cram before an exam, without introducing noise into the optimization procedure
- future SuperMemos may or may not use simplified algorithms based on algebraic formulation of C2 (denoted as SInc, for stability increase, in Equation 7.1). Although the new formula offers simplicity, it holds no promise as to the accuracy of the determination of C2 and will have required substantial investment in testing and verifying the algorithms that might be based on it
Notes for users of SuperMemo for Windows:
- Stability dimension of C2 can be inspected visually with Tools : Statistics : Analysis : Approximations
- Two dimensional C2 can be viewed in 3-D with: Tools : Statistics : Analysis : 3-D Graphs : O-Factor matrix (smoother) or R-Factor matrix (raw)
- Retrievability dimension of C2 can be seen in several figures in Building memory stability through rehearsal. The retrievability dimension used in computing C2 for the requested forgetting index can be viewed with Tools : Statistics : Analysis : Forgetting curves