| This text was taken from P.A.Wozniak, Economics of learning, Doctoral Dissertation, University of Economics, Wroclaw, 1995 and adapted for publishing as an independent article on the Web. (P.A.Wozniak, Feb 23, 1999) |
New algorithmic elements
Below, I will try to shortly present the new elements introduced in Algorithm SM-6, which is currently used in SuperMemo 6 for DOS, SuperMemo 7 for Windows, and SuperMemo for Amiga.
In Algorithm SM-5, the process of determining the value of a single entry of the matrix of optimal factors looked as follows (see before):
- Set the initial value to an average optimal factor value (OF) obtained in previous experiments
- If the grade produced by the entry in question was (1) greater than the desired value then increase the value of OF, (2) less than the desired value then decrease OF, or (3) equal the desired value then do not change OF
The above approach shows that the optimum value of OF could be reached only after a great number of repetitions, and what is worst, the greater the ordinal number of a repetition, the longer it would take to execute the modification-verification cycle (i.e. the cycle in which an OF entry is changed, and verified upon scheduling another repetition with a correspondingly long interval).
Introducing the concept of the forgetting index
The novelty of Algorithm SM-6 is to approximate the slope of the forgetting curve corresponding to a given entry of the matrix of optimal factors, and compute the new value of the relevant optimal factor directly from the approximated curve. In other words, no modification-verification cycle is necessary in Algorithm SM-6 because of establishing the deterministic relationship between the forgetting curve and the optimum inter-repetition interval. The modification of the optimal factor occurs immediately after a repetition upon approximating the new forgetting curve derived from data that include the grade provided in the recent response. This modification not only made it possible to greatly accelerate the process of determining the optimum values of the matrix of optimal factors, but also provided a means for establishing the desired level of knowledge retention that will be reached in the course of the learning process (see an exemplary forgetting curve in Figure 1).
The desired level of knowledge retention is determined by the proportion of items that are not remembered at repetitions. This proportion is called the forgetting index (items are classified as remembered or forgotten on the basis of grades provided by the student in self-assessment of his or her progress).
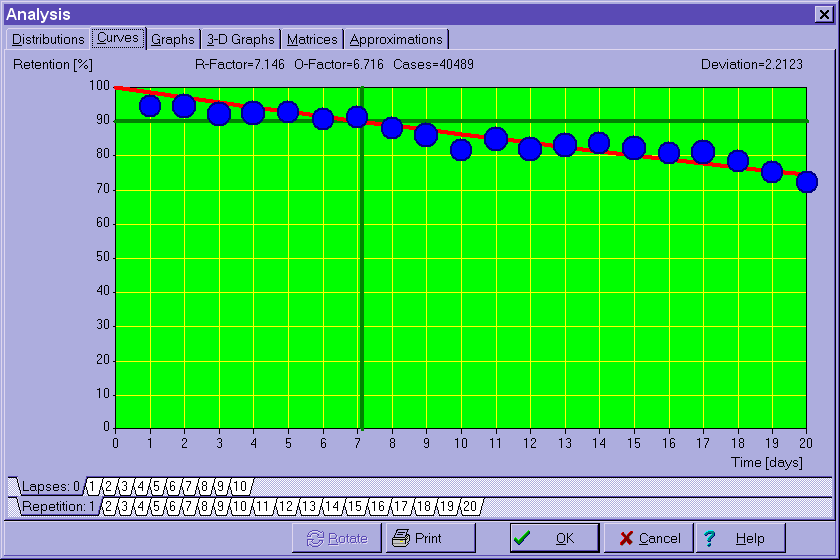
Figure 1 An exemplary forgetting curve plotted in the course of repetitions (over 40,000 repetition cases recorded)
In the figure presented above
[updated in November 1999 with a more recent set of data], the lapse of time is represented by the interval in days. The vertical axis represents knowledge retention stated as percentage. The horizontal line located at the retention level of 90% determines the requested forgetting index, i.e. the desired proportion of items that should be forgotten at the moment of repetition. The optimum interval will then naturally come at the cross-section of the requested forgetting index line with the forgetting curve. In the example above, the optimum interval equals seven days. The presented forgetting curve has been plotted on the basis of 40489 recorded repetition cases. See later in the text for explanation of the values R-Factor (RF), O-Factor (OF), etc.Because of the highly irregular nature of the matrix of optimal factors computed directly from forgetting curves, in Algorithm SM-6, the matrix used in spacing repetitions represents a smoothed version of the so-called matrix of retention factors (matrix RF), which is derived directly from forgetting curves corresponding to particular entries of the matrix OF. In other words, forgetting curves determine the value of entries of the matrix RF, and only the smoothed equivalent of the latter, the matrix OF is used in computing optimum intervals.
| Algorithm SM-6 In short, the Algorithm SM-6 could be summarized as follows (note, that repetitions may and should proceed indefinitely, if the memorized material is to be perpetually retained in the student’s memory):
|
Approximation of the forgetting curve
One of major hypotheses presented in my earlier work that had to be falsified was the presumed sigmoid shape of forgetting curves for all inter-repetitions intervals except the interval that follows memorization. The main reason for putting forward such a hypothesis was that exponential approximation yielded particularly high deviation error for data collected in my work on the model of intermittent learning, and that superposition of sigmoid curves for different E-factors can assume close-to-linear shape. Linear approximation, on the other hand, seemed to excellently fit the model of intermittent learning.
Upon the development of Algorithm SM-6, a large body of data has been collected that could be used in determining the shape of the forgetting curve for all values of E-factors and repetition numbers.
Using my own database, in which data from over 200,000 repetitions has been collected, I tried to answer the question about the mathematical nature of the forgetting curve. Unfortunately, even this huge amount of data cannot give the ultimate answer. I tried simple linear, exponential and sigmoid approximation for entries taken from different areas of the matrix of optimal factors. Clearly, exponential approximation produced the best fit, followed closely by linear approximation. Sigmoid curves clearly did not fit the collected data, the fact that can be testified to by visual interpretation of forgetting curves plotted by standard SuperMemo software for every user and every database (here, the following function is used to approximate the forgetting: R=exp(-k*t), where R-retention in percent, t-time, and k-decay constant whose value depends on the unit used to measure time, which in Algorithm SM-6 is expressed in terms of the U-factor).
Naturally, the greatest amount of data, over 20,000 repetitions, has been collected for E-factor equal to 2.5 and repetition number equal to one. As it can be see in the figure, the retention values in this particular case line up along an almost straight line, which as well might be an exponential curve with a very low decay constant.
Only when looking at the same curve for E-factor equal to 1.3 and the repetition number equal to nine, one can better visualize the exponential nature of the process of forgetting. However, in the latter case, the regularity of collected data seems to fall short from a point at which a conclusive judgment could be made (only slightly over 500 repetition cases have been recorded for that particular entry of the matrix of optimal factors).
As I increasingly tried to argue, the greatest support to all my findings in reference to the optimization of learning comes from the fact that the found paradigm seems to be optimum from the evolutionary survival of the species standpoint, the following reasoning should illustrate why sigmoid nature of forgetting is unlikely. If forgetting mechanisms developed by evolution are indeed optimal with respect to optimizing the memory storage, and consequently survival, then the length of the optimum inter-repetition interval should correspond with the probability of encountering or reusing the learned association in a real-life situation. However, there is no significant change in that probability at or around the point of time determined by the optimum interval. Consequently, there should be no significant drop in the probability of recall.
As for the interpretation of the model of intermittent learning presented in my earlier publications one should not forget about the two following fact that might lead to drawing wrong conclusions: (1) items used in learning and in development of the model of intermittent learning have been grouped in pages and considered collectively (therefore, the resulting forgetting curve must have been a superposition of forgetting curves that would characterize items with different E-factors), and (2) the decay constant used to approximate forgetting curves is low enough to yield good approximation results for linear regression.
All in all, the truth is that 19-th century findings of the German psychologist Herman Ebbinghaus (1850-1909) can be extended to state that the forgetting proceeds along the exponential curve independent of the number of repetitions accorded an item